Pytorch SSD模型深度解析:结构与输入输出分析
162 浏览量
更新于2024-08-30
收藏 77KB PDF 举报
"基于Pytorch的SSD模型分析,探讨模型结构及输入输出特性。SSD(Single Shot MultiBox Detector)是一种目标检测算法,通过在不同尺度的特征图上预测物体框来实现单次前传完成检测。文章引用了GitHub上的SSD实现,并提供了基础网络配置,包括VGG网络的部分和额外的卷积层定义。"
SSD(Single Shot MultiBox Detector)是深度学习中用于目标检测的一种高效算法,它克服了以往如R-CNN系列方法的多步骤检测流程,实现了在单个前向传播中同时预测多个物体边界框和类别。SSD的核心思想是在不同分辨率的特征层上同时预测物体框,这使得它可以快速并行地处理多个尺度的物体。
在给出的代码片段中,可以看到SSD的基础网络结构部分是基于VGG网络构建的。VGG网络以其深度著称,通常由多个卷积层(Conv2d)和最大池化层(MaxPool2d)组成。在`vgg`函数中,`cfg`参数是一个包含不同卷积层通道数和池化操作的配置列表。`batch_norm`参数决定是否在卷积层后应用批量归一化层。这段代码中还定义了`extras`,这是一组额外的卷积层,用于添加更多的特征提取层次,以增强模型对不同尺度物体的检测能力。
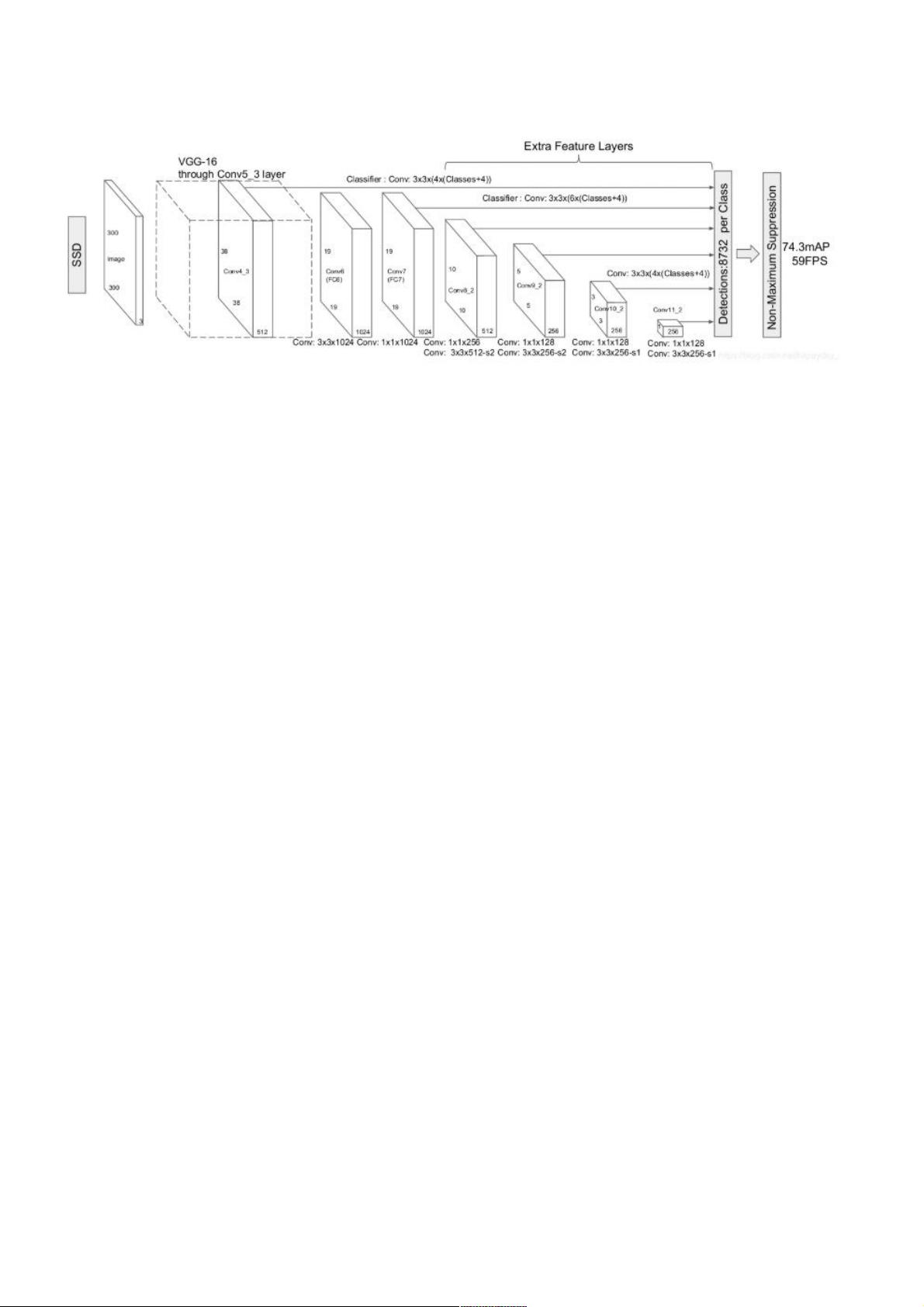
`mbox`字典定义了每个特征图位置上预测的边界框数量。例如,对于输入尺寸为300x300的图像,每个特征图位置会预测4(小物体)+ 6(中等物体)+ 6(大物体)+ 6(更大物体)+ 4(非常大物体)= 26个边界框。总输出框的数量是所有特征图位置的总和,即8732个,这是因为SSD会在多个尺度的特征图上进行预测。
SSD的预测过程包括两部分:分类和定位。每个边界框会预测一个类别概率分布和四个偏移量,这些偏移量将预定义的默认框(称为 anchor boxes)调整到实际物体框的位置。不同尺度的特征图对应不同大小的anchor boxes,以覆盖不同大小的物体。
在提供的代码中,`pool5`、`conv6`和`conv7`等层是VGG16网络的最后部分,它们增加了额外的卷积层以提升模型的表达能力。`conv6`和`conv7`使用较大的卷积核大小(6x6)和步长(1),并且在`conv6`中使用了更大的填充(6)来保持输出尺寸不变,这是为了处理更大的感受野,以捕获更大物体的信息。
总结来说,SSD模型通过结合多尺度特征图的预测,提高了目标检测的速度和精度。在PyTorch中实现时,它通常基于预训练的VGG网络进行微调,然后添加额外的头部层用于边界框回归和分类。这个实现包括了基础的VGG结构、额外的卷积层以及定义了模型输出框数量的配置,展示了SSD模型的关键组成部分。
基于基于Pytorch SSD模型分析模型分析
本文参考github上SSD实现,对模型进行分析,主要分析模型组成及输入输出大小.SSD网络结构如下图:
每输入的图像有8732个框输出;
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.autograd import Variable
#from layers import *
from data import voc, coco
import os
base = {
'300': [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 'C', 512, 512, 512, 'M',
512, 512, 512],
'512': [],
}
extras = {
'300': [256, 'S', 512, 128, 'S', 256, 128, 256, 128, 256],
'512': [],
}
mbox = {
'300': [4, 6, 6, 6, 4, 4], # number of boxes per feature map location
'512': [],
}
VGG基础网络结构基础网络结构:
def vgg(cfg, i, batch_norm=False):
layers = [] in_channels = i
for v in cfg:
if v == 'M':
layers += [nn.MaxPool2d(kernel_size=2, stride=2)] elif v == 'C':
layers += [nn.MaxPool2d(kernel_size=2, stride=2, ceil_mode=True)] else:
conv2d = nn.Conv2d(in_channels, v, kernel_size=3, padding=1)
if batch_norm:
layers += [conv2d, nn.BatchNorm2d(v), nn.ReLU(inplace=True)] else:
layers += [conv2d, nn.ReLU(inplace=True)] in_channels = v
pool5 = nn.MaxPool2d(kernel_size=3, stride=1, padding=1)
conv6 = nn.Conv2d(512, 1024, kernel_size=3, padding=6, dilation=6)
conv7 = nn.Conv2d(1024, 1024, kernel_size=1)
layers += [pool5, conv6,
nn.ReLU(inplace=True), conv7, nn.ReLU(inplace=True)] return layers
size=300
vgg=vgg(base[str(size)], 3)
print(vgg)
输出为:
Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
ReLU(inplace)
Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
ReLU(inplace)
下载后可阅读完整内容,剩余4页未读,立即下载
4170 浏览量
2022-02-07 上传
207 浏览量
238 浏览量
113 浏览量
113 浏览量
2021-03-28 上传
713 浏览量
287 浏览量

weixin_38645379
- 粉丝: 7
 我的内容管理
展开
我的内容管理
展开







最新资源
- 32位TortoiseSVN_1.7.11版本下载指南
- Instant-gnuradio:打造定制化实时图像和虚拟机GNU无线电平台
- PHP源码工具PHProxy v0.5 b2:多技术项目源代码资源
- 最新版PotPlayer单文件播放器: 界面美观且功能全面
- Borland C++ 必备库文件清单与安装指南
- Java工程师招聘笔试题精选
- Copssh:Windows系统的安全远程管理工具
- 开源多平台DimReduction:生物信息学的维度缩减利器
- 探索Novate:基于Retrofit和RxJava的高效Android网络库
- 全面升级!最新仿挖片网源码与多样化电影网站模板发布
- 御剑1.5版新功能——SQL注入检测体验
- OSPF的LSA类型详解:网络协议学习必备
- Unity3D OBB下载插件:简化Android游戏分发流程
- Android网络编程封装教程:Retrofit2与Rxjava2实践
- Android Fragment切换实例教程与实践
- Cocos2d-x西游主题《黄金矿工》源码解析
