SwinTransformer:计算机视觉中的通用模型与拥抱Transformer的五大理由
版权申诉
本文档探讨了Swin Transformer以及为什么在计算机视觉领域拥抱Transformer的原因。作者胡瀚来自微软研究亚洲研究院(MSRA),发表于2021年7月10日,以DataFun为平台,旨在深入分析Transformer在自然语言处理(NLP)和计算机视觉(CV)中的广泛应用,以及它如何成为AI领域的圣杯。
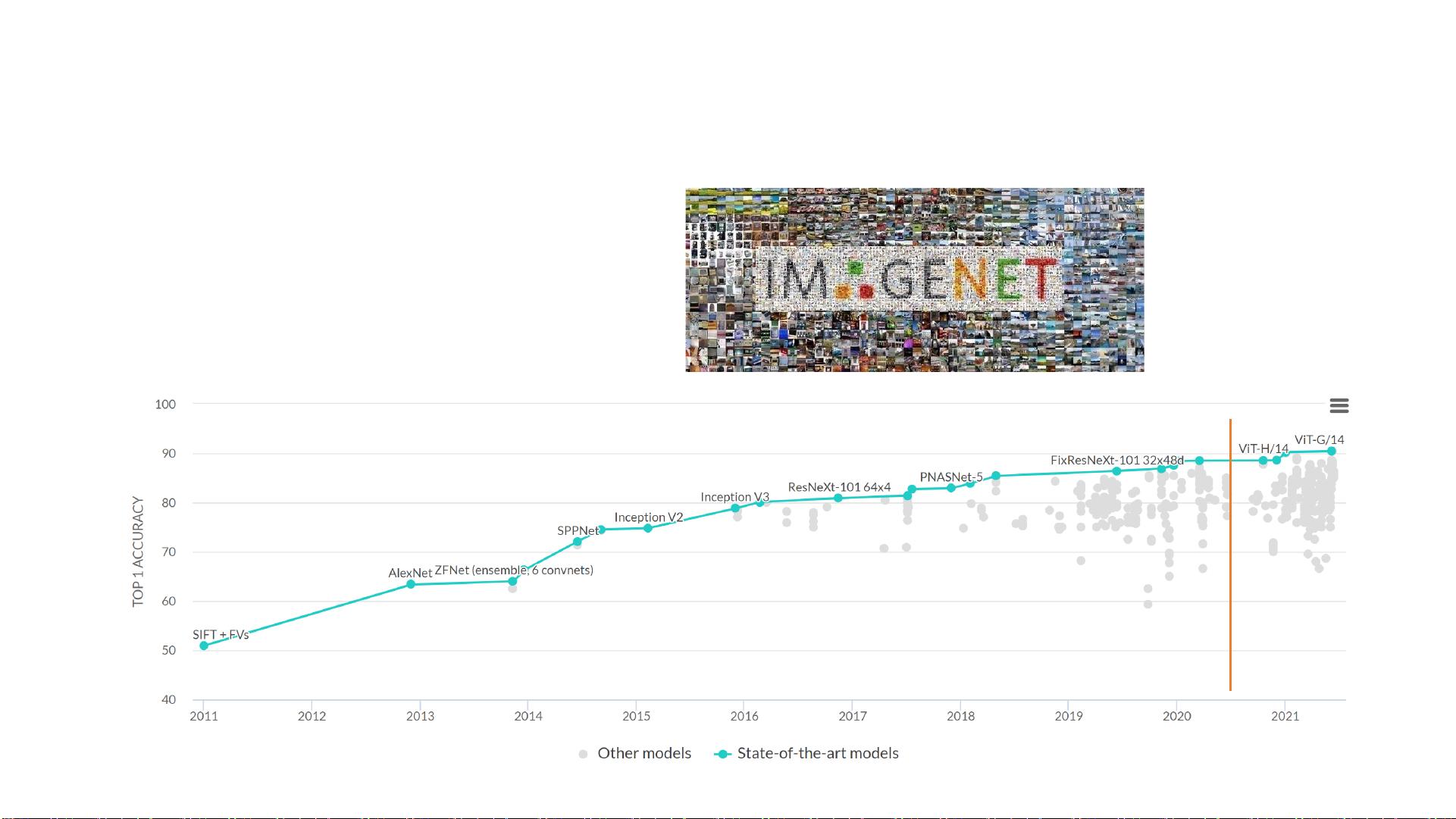
Transformer模型起源于2017年,由Google Brain提出,凭借其自注意力机制在序列数据处理上取得了革命性突破,如机器翻译任务中的显著性能提升。在NLP领域,它推动了诸如LSTM(1995年由Jürgen Schmidhuber提出)、Baidu的Deep RNN(2014年)、Google的GRU(2014年)等模型的发展,同时也引领了CIFAR数据集上RNN+注意力机制的研究。2015年后,Transformer逐渐成为主流,超越了传统的循环神经网络(RNN)架构。
在计算机视觉领域,从LeNet到AlexNet、GoogleNet、VGGNet和ResNet等卷积神经网络(CNN)的演进后,Swin Transformer提出了一个全新的视角,即是否可能让NLP和CV共享基本模块。论文提出了一种思路,即通过动态适应或扩展CNN结构来适应NLP任务,如FAIR的ConvSeq2Seq模型和动态卷积技术。
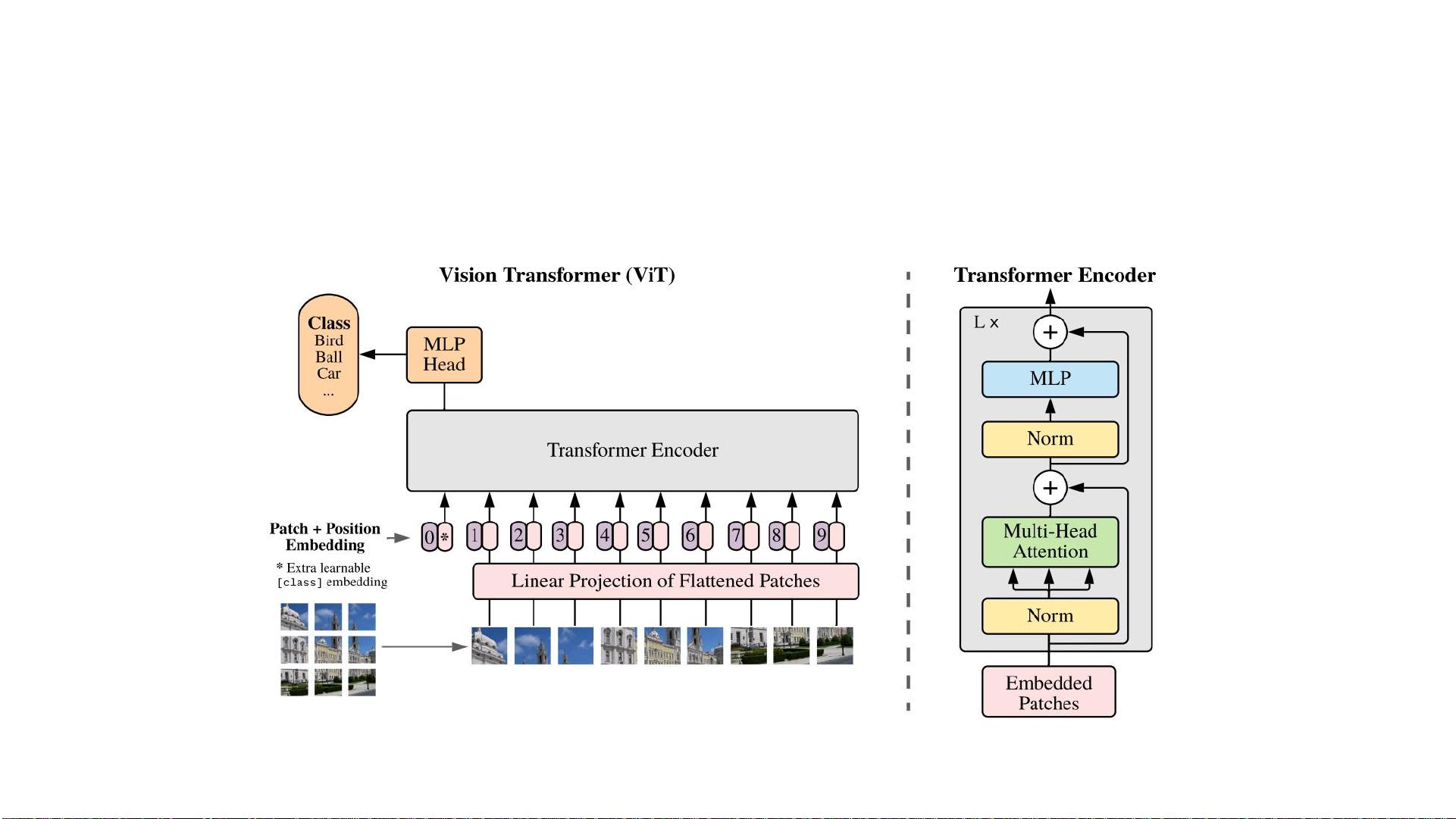
Swin Transformer本身是一种基于Transformer的模型,但针对计算机视觉场景进行了优化,它结合了卷积和自注意力机制,实现了空间和时间上的并行计算,这使得它在保持Transformer高效表示学习的同时,也保留了CNN在局部感受野和效率方面的优点。这种模型的出现,使得联合视觉和文本信号的建模成为可能,能够更深层次地共享知识,追求模型的通用性,这是人工智能领域的美丽理念,也是与物理学中统一理论的相似之处。
文章列举了DALL-E和CLIP等大模型的成功案例,展示了Transformer在跨模态学习中的卓越表现,比如在无监督情况下理解和生成图像和文本的关联。此外,作者还回顾了Transformer如何引领了模型进化,从单一的序列处理扩展到多模态和跨领域的广泛应用。
总结来说,这篇文档深入剖析了Swin Transformer的优势,以及它为何成为拥抱Transformer的五个理由:一是Transformer的通用性,适用于NLP和CV;二是深度整合视觉和文本知识;三是追求模型的普适美;四是通过共享基础模块促进模型间的迁移学习;五是Transformer在实际任务和跨模态模型中的卓越成就。这些都表明Transformer在现代AI发展中占据着核心地位,并将继续推动技术的进步。
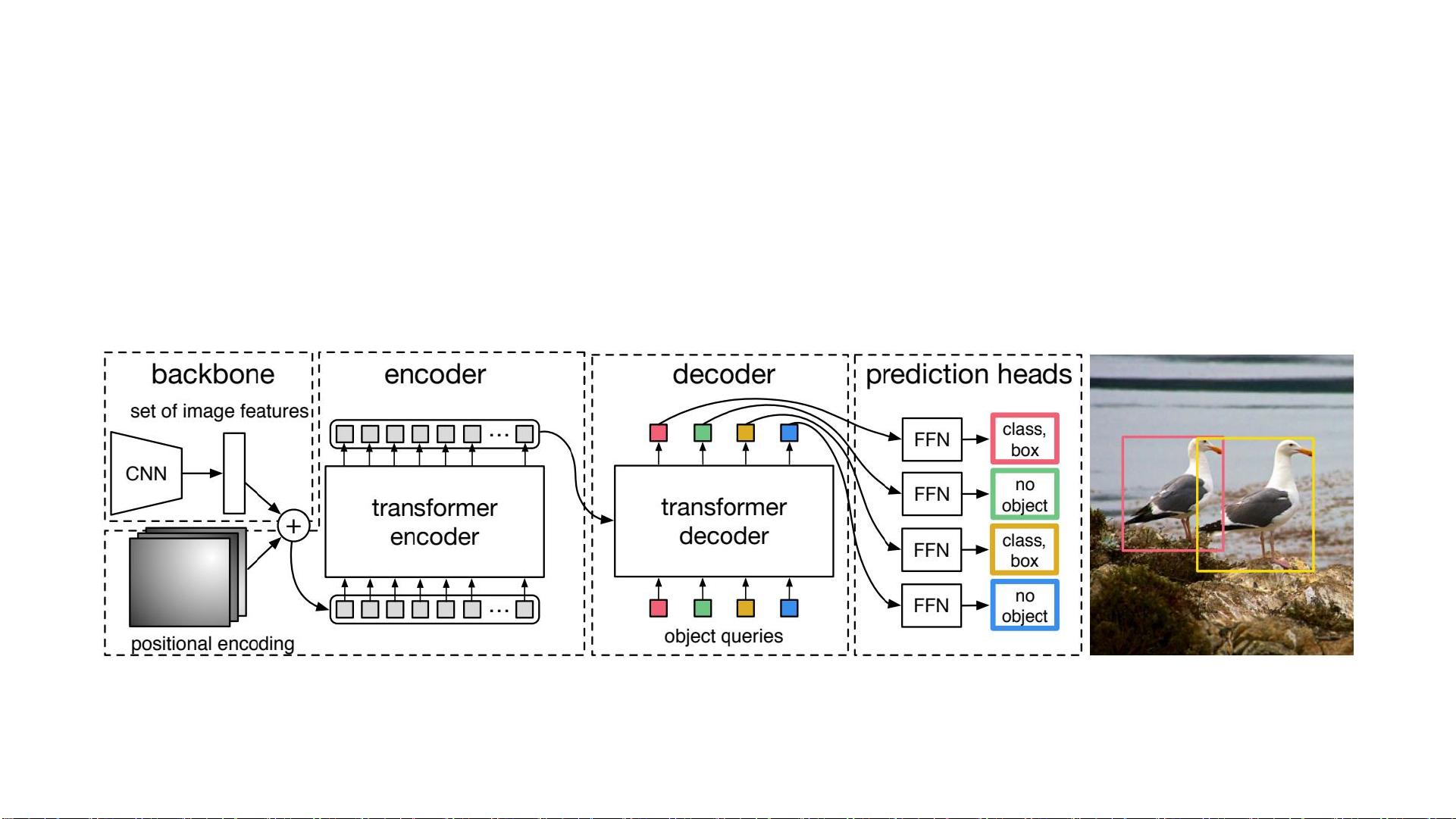
DeTr for object detection
• Treat object detection as a machine translation (or encoder-decode) problem
Nicolas Carion et al. End-to-End Object Detection with Transformers. ECCV 2020
剩余55页未读,继续阅读
2024-03-29 上传
2024-10-20 上传
2024-10-21 上传
2024-10-21 上传
2021-12-06 上传
2024-04-09 上传
2023-06-02 上传

普通网友
- 粉丝: 13w+
- 资源: 9195
 我的内容管理
展开
我的内容管理
展开







