"Origin7.5数据拟合方法与非线性拟合步骤详解"
需积分: 3 131 浏览量
更新于2023-12-19
收藏 1.06MB PPT 举报
本文讨论了在ORIGIN7.5软件中进行线性和非线性拟合的过程。在进行数据拟合之前,必须选择要拟合的数据,并在图形中设置数据点的显示范围。在ORIGIN中,非线性拟合的算法包括Levenberg-Marquardt (L-M) method和Simplex Method。L-M算法需要对每一个待估参数求偏导,对于内置拟合函数,ORIGIN提供了求偏导的解析表达式,因此速度较快;对于用户自定义的拟合函数,求偏导时,直接使用数值进行,速度较慢。当L-M算法不能得出最佳的拟合结果时,可以尝试使用Simplex Method。
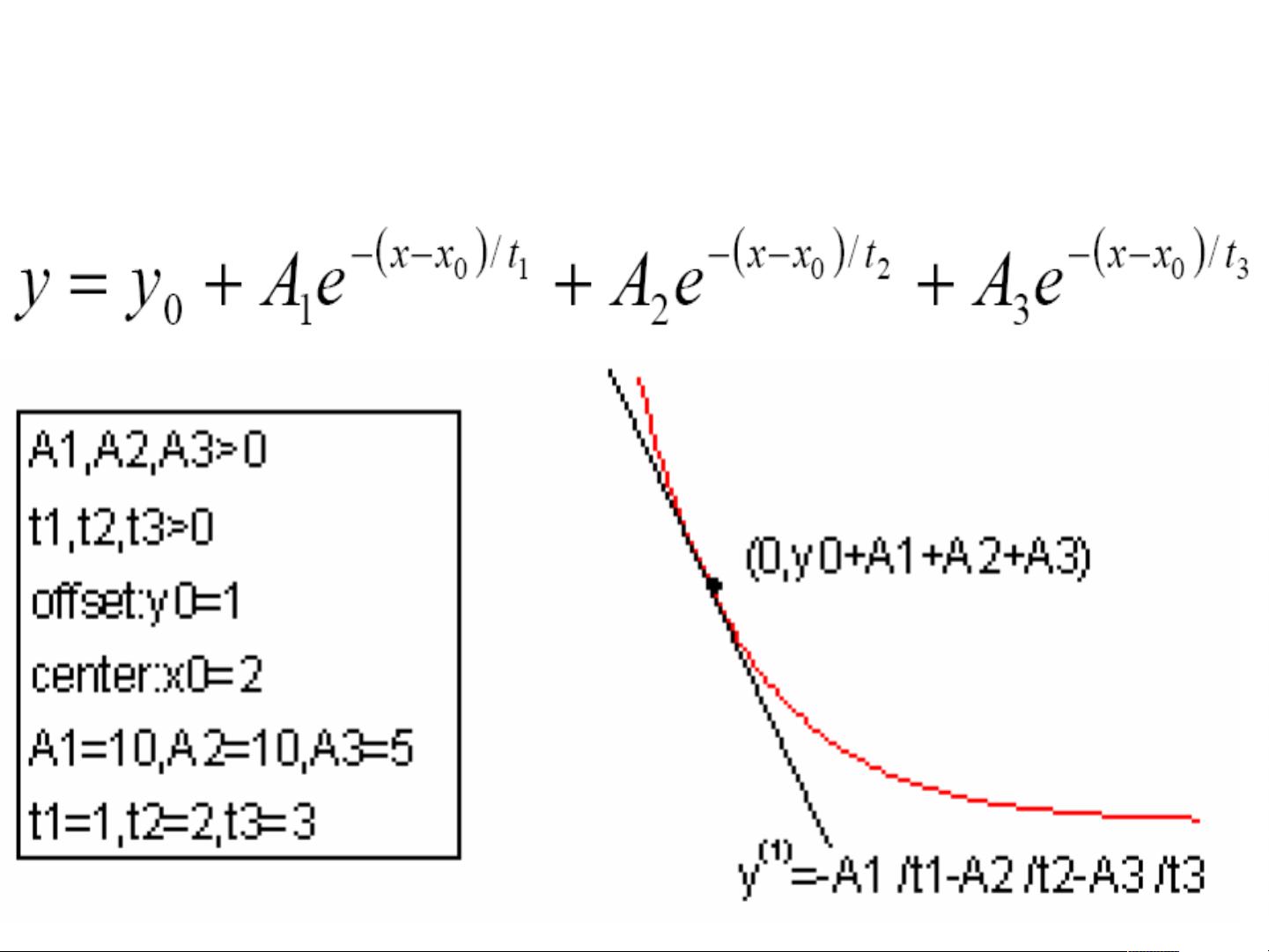
在进行非线性拟合时,需要将数据输入worksheet,并做数据的散点图。进行非线性拟合的步骤包括使用菜单进行非线性拟合Fit Exponential Decay - first order一阶指数衰减拟合等。ORIGIN还提供了拟合向导,按照向导的指示操作即可,如果是自定义函数,可以使用高级非线性拟合工具进行拟合,所有的拟合过程都可以控制。
对于线性拟合,ORIGIN7.5提供了线性拟合的功能,其过程是比较简单的。通过线性拟合,可以得到自变量和因变量之间的线性关系,从而可以进行预测和分析。
在进行非线性拟合的结果评价时,可以使用拟合的拟合度(R-Squared)、残差分析和参数的置信区间等指标对拟合结果进行评价。R-Squared越接近于1,表示拟合结果越好;残差分析可以得到残差的分布情况,从而评价拟合的误差情况;参数的置信区间则可以用来评价参数的估计值的可靠性。
在实际应用中,线性和非线性拟合都有其各自的优缺点。线性拟合比较简单,计算速度较快,但是只能拟合线性关系的数据;而非线性拟合可以拟合复杂的数据关系,但是拟合过程相对复杂,计算速度较慢。因此,在选择拟合方法时,需要根据实际情况和数据的特点来进行选择。
总之,ORIGIN7.5提供了丰富的线性和非线性拟合功能,针对不同的拟合需求提供了不同的拟合算法和工具。通过合理选择拟合方法,可以得到准确的拟合结果,从而进行数据分析和预测。同时,在进行拟合结果的评价时,需要综合考虑拟合度、残差分析和参数的置信区间等指标,以得到对拟合结果的全面评价。
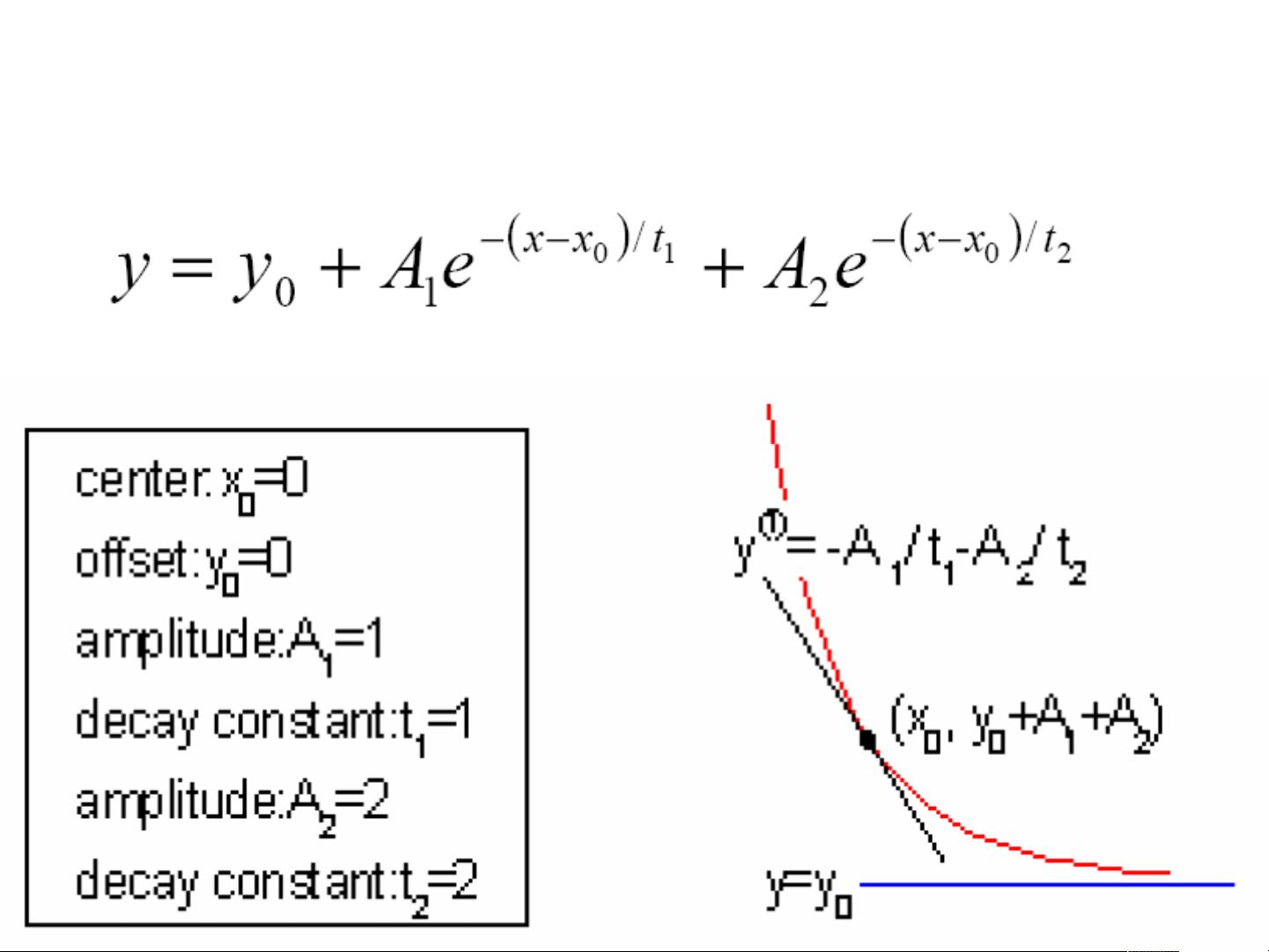
FitExponentialDecay-secondorder
二阶指数衰减拟合
剩余42页未读,继续阅读
点击了解资源详情
点击了解资源详情
点击了解资源详情
128 浏览量
点击了解资源详情
点击了解资源详情
333 浏览量
点击了解资源详情

鲁严波
- 粉丝: 26
 我的内容管理
展开
我的内容管理
展开







最新资源
- MATLAB实现ART与SART算法在医学CT重建中的应用
- S2SH整合版:快速搭建Struts2+Spring+Hibernate开发环境
- 托奇卡项目团队成员介绍
- 提升外链发布效率的SEO推广神器——搜易达网络推广大师v2.035
- C#打造简易记事本应用详细教程
- 探索虚拟现实地图VR的奥秘
- iOS模拟器屏幕截图新工具
- 深入解析JavaScript在生活应用开发中的运用
- STM32F10x函数库3.5中文版详解与应用
- 猎豹浏览器v6.0.114.13396 r1:安全防护与网购敢赔
- 掌握JS for循环输出的最简洁代码技巧
- Java入门教程:TranslationFileGenerator快速指南
- OpenDDS3.9源码解析及最新文档指南
- JavaScript提示框插件:鼠标滑过显示文章摘要
- MaskRCNN气球数据集:优质图像识别资源
- Laravel日志查看器:实现Apache多站点日志统一管理
