Python爬虫入门:实战汽车之家的简单教程
112 浏览量
更新于2024-09-02
收藏 398KB PDF 举报
本文将深入探讨Python爬虫系列中的基础知识,以帮助初学者理解爬虫工作原理并掌握基本操作。首先,我们将使用Python的requests模块和BeautifulSoup库来进行实践,这两个库在爬虫开发中扮演着核心角色。
1. **requests模块**:requests库用于发送HTTP请求,模拟浏览器行为。在爬取网页时,通过`requests.get()`函数发送GET请求,获取目标网站的HTML内容。例如,在汽车之家网站(<https://www.autohome.com.cn/news/>)的案例中,我们通过`requests.get()`获取网页源代码。
2. **BeautifulSoup解析**:BeautifulSoup是一个强大的HTML和XML解析库,它允许开发者以结构化的Python对象方式处理HTML文档。通过`.text`属性获取页面文本,然后使用`BeautifulSoup(res.text, "html.parser")`创建一个BeautifulSoup对象,以便后续搜索和提取信息。
3. **编码处理**:网页的编码可能与Python默认的UTF-8不一致,如汽车之家使用GBK编码。我们需要设置`res.encoding = "gbk"`,确保正确解析网页内容。
4. **查找元素**:BeautifulSoup提供了`.find()`和`.find_all()`方法来定位特定标签。`find()`找到第一个匹配的标签,而`find_all()`则返回所有匹配的标签列表。比如,我们可以查找`id`为`auto-channel-lazyload-article`的`div`标签,并在其中查找`li`标签及其包含的`h3`、`p`和`a`标签。
5. **循环遍历**:对于多个符合特定条件的标签,通过`for li in li_list:`循环遍历,进一步提取每个`li`标签内的信息,如标题、内容和链接。
6. **实战应用**:本文提供了一个完整流程,包括导入模块、发送请求、设定编码、解析HTML以及数据提取。通过这些步骤,读者可以逐渐掌握爬虫的基本操作,无论是学习还是工作中遇到类似需求,都能以此为基础进行拓展。
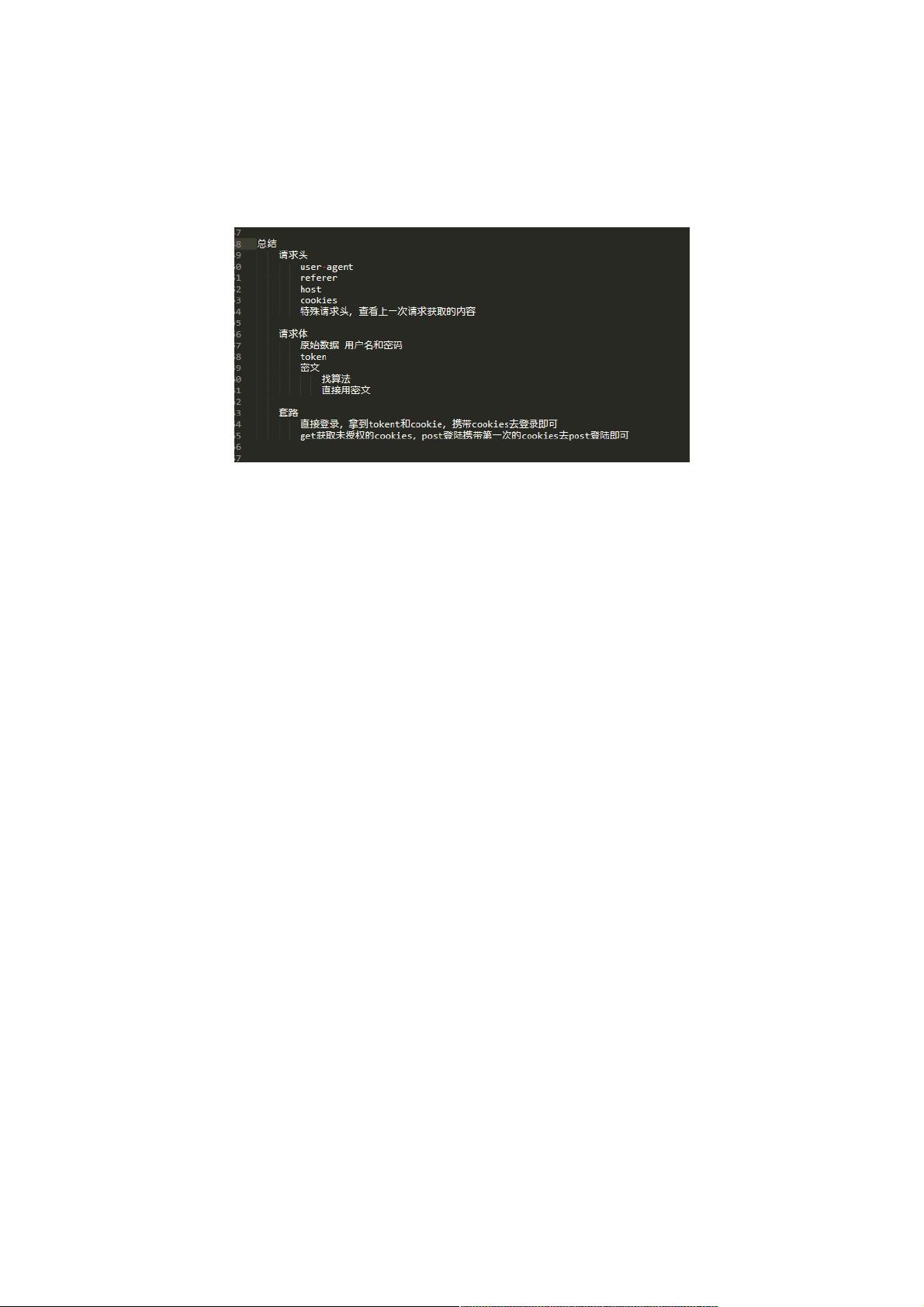
总结来说,本文主要讲解了如何使用Python的requests和BeautifulSoup库进行基础的网页抓取,包括请求发送、内容解析和数据提取。这对于想要入门爬虫技术的人来说是一个很好的起点,通过实际操作,逐步建立起对爬虫工作原理和技巧的理解。
详解详解python爬虫系列之初识爬虫爬虫系列之初识爬虫
主要介绍了python爬虫系列之初识爬虫,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友
们下面随着小编来一起学习学习吧
前言
我们这里主要是利用requests模块和bs4模块进行简单的爬虫的讲解,让大家可以对爬虫有了初步的认识,我们通过爬几个简单网站,让大家循序渐进的掌握
爬虫的基础知识,做网络爬虫还是需要基本的前端的知识的,下面我们进行我们的爬虫讲解
在进行实战之前,我们先给大家看下爬虫的一般讨论,方便大家看懂下面的实例
一、爬汽车之家一、爬汽车之家
汽车之家这个网站没有做任何的防爬虫的限制,所以最适合我们来练手
1、导入我们要用到的模块
import requests
from bs4 import BeautifulSoup
2、利用requests模块伪造浏览器请求
# 通过代码伪造浏览器请求
res = requests.get(https://www.autohome.com.cn/news/)
3、设置解码的方式,python是utf-8,但是汽车之家是用gbk编码的,所以这里要设置一下解码的方式
# 设置解码的方式
res.encoding = "gbk"
4、把请求返回的对象,传递一个bs4模块,生成一个BeautifulSoup对象
soup = BeautifulSoup(res.text,"html.parser")
5、这样,我们就可以使用BeautifulSoup给我们提供的方法,如下是查找一个div标签,且这个div标签的id属性为auto-channel-lazyload-atricle
# find是找到相匹配的第一个标签
div = soup.find(name="div",attrs={"id":"auto-channel-lazyload-article"})
# 这个div是一个标签对象
6、findall方法,是超找符合条件的所有的标签,下面是在步骤5的div标签内查找所有的li标签
li_list = div.find_all(name="li")
7、查找li标签中的不同条件的标签
li_list = div.find_all(name="li")
for li in li_list:
title = li.find(name="h3")
neirong = li.find(name="p")
href = li.find(name="a")
img = li.find(name="img")
if not title:
continue
8、获取标签的属性
# print(title, title.text, sep="标题-->")
# print(neirong, neirong.text, sep="内容-->")
# print(href, href.attrs["href"], sep="超链接-->")
# 获取标签对接的属性
# print(img.attrs["src"])
# ret = requests.get(img_src)
9、如果我们下载一个文件,则需要requests.get这个文件,然后调用这个文件对象的content方法
src = img.get("src")
img_src = src.lstrip("/")
file_name = img_src.split("/")[-1]
img_src = "://".join(["https",img_src])
print(file_name)
ret = requests.get(img_src)
with open(file_name,"wb") as f:
下载后可阅读完整内容,剩余6页未读,立即下载
2024-07-20 上传
2022-05-29 上传
2021-09-13 上传
2022-07-09 上传
3535 浏览量
2300 浏览量
801 浏览量
231 浏览量
116 浏览量

weixin_38538585
- 粉丝: 3
- 资源: 956
 我的内容管理
展开
我的内容管理
展开







最新资源
- metalsmith-scan-images:一个金属匠插件,可扫描子文件夹中的所有图像并将其添加到元数据中
- 单片机作业流水灯实验
- DSnooker-3D-master_herdhzf_page_loadingbarinhtml_
- speedlyh.github.io
- rustls:Rust中的现代TLS库
- 指针验证的有用宏
- 依玛
- UDI-BASpi-Pool-Control
- MercuryProject1:第一天会议
- B样条曲线生成_简单的C++实现
- pull-ipc:电子IPC通道周围的拉流包装器
- ADC_stm32adc_
- meli::honeybee:实验性的终端邮件客户端,https:git.meli.deliverymelimeli.git https:crates.iocratesmeli的镜像
- 鲜花摄影Html5网站模板是一款摄影爱好者Html5网站模板下载 .rar
- pokedex
- 将2D libgdx游戏移植到MonoGame
