初识gecco:一个强大的分布式并发计算框架
发布时间: 2023-12-16 09:34:27 阅读量: 74 订阅数: 23 

分布式计算框架
# 1. 引言
## 1.1 介绍gecco框架的背景和意义
在当今信息爆炸的时代,大量的数据涌入互联网,如何有效地从海量数据中提取有用信息成为了一个重要的问题。同时,由于各种原因,有许多数据并不容易获取,如动态页面、反爬策略等。针对这些问题,我们需要一种高效、灵活且易用的网页爬取框架。
Gecco框架就是为了解决这些问题而诞生的。它是一个Java语言编写的,基于WebMagic和jsoup的简单、灵活且易扩展的分布式爬虫框架。Gecco框架通过底层的网络请求库Httpclient实现了对网页的抓取,并通过jsoup解析HTML,使用类似于jQuery的选择器语法进行数据的提取。同时,Gecco框架支持多线程异步抓取和处理,具有较高的抓取效率和并发能力。
## 1.2 概述gecco框架的特点和优势
Gecco框架具有以下几个核心特点和优势:
1. **简单易用**:Gecco框架提供了简洁、灵活的API,开发者只需少量代码即可完成网页抓取和数据提取的工作。
2. **高效快速**:Gecco框架采用了多线程异步抓取和处理的方式,可以同时处理多个请求,大大提高了抓取速度和效率。
3. **分布式支持**:Gecco框架支持分布式部署,可以通过配置中心和消息队列等技术实现多台机器的协同工作,更好地应对高并发抓取的需求。
4. **灵活扩展**:Gecco框架使用插件式的开发模式,支持用户自定义的抓取逻辑和数据处理流程,同时提供了丰富的扩展点,方便用户根据具体需求进行定制开发。
综上所述,Gecco框架是一款强大而灵活的网页抓取框架,拥有简单易用、高效快速、分布式支持等特点,为开发者提供了一种快捷、高效的数据抓取解决方案。接下来我们将详细介绍Gecco框架的基本概念与原理。
# 2. gecco框架的基本概念与原理
在本章中,我们将详细介绍gecco框架的基本概念和原理。了解gecco框架的核心概念和工作原理对于使用和配置该框架具有重要意义。
### 2.1 gecco框架的核心概念解析
gecco框架的核心概念包括爬虫定义、请求定义、解析器定义和管道定义。
**2.1.1 爬虫定义**
爬虫定义是指在gecco框架中编写的用于爬取网页数据的类。爬虫定义通常包括URL、请求参数、请求方法、请求头、请求体等信息的配置。通过定义爬虫,我们可以指定要抓取的目标网站和相应的数据抓取规则。
以下是一个示例的爬虫定义代码:
```python
@Gecco(matchUrl="https://www.example.com/news/{id}", pipelines="consolePipeline")
public class NewsSpider implements HtmlBean {
@Request
private HttpRequest request;
@RequestParameter
private String id;
@Text
@HtmlField(cssPath=".news-title")
private String title;
// 其他字段定义...
// Getter和Setter方法...
}
```
在上述代码中,通过使用`@Gecco`和`@HtmlBean`注解,我们定义了一个名为`NewsSpider`的爬虫。`matchUrl`属性指定了匹配的URL,其中`{id}`表示动态的URL参数。`pipelines`属性指定了使用的数据管道。`@Request`和`@RequestParameter`注解用于指定请求参数。`@Text`和`@HtmlField`注解用于指定数据解析规则。
**2.1.2 请求定义**
请求定义是指在gecco框架中配置用于请求目标网页的信息,包括URL、请求参数、请求方法、请求头、请求体等。通过定义请求,我们可以指定如何发送请求并获取网页数据。
以下是一个示例的请求定义代码:
```python
HttpRequest request = new HttpGetRequest("https://www.example.com/news/123");
request.addHeader("User-Agent", "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3");
request.setCharset("UTF-8");
// 其他配置...
```
在上述代码中,我们使用`HttpGetRequest`创建了一个GET请求,指定了目标URL为"https://www.example.com/news/123"。然后,我们可以通过`addHeader`方法添加请求头信息,通过`setCharset`方法设置字符编码等。
**2.1.3 解析器定义**
解析器定义是指在gecco框架中编写的用于解析网页数据的类。解析器定义通常包括解析规则、解析方法和解析结果的封装。通过定义解析器,我们可以指定如何解析网页数据,并将解析结果封装为我们需要的数据类型。
以下是一个示例的解析器定义代码:
```python
public class NewsParser implements HtmlParser<News> {
@Override
public News parse(Document document, HtmlBean htmlBean, Context context) {
NewsSpider spider = (NewsSpider) htmlBean;
News news = new News();
news.setId(spider.getId());
news.setTitle(spider.getTitle());
// 其他字段解析...
return news;
}
}
```
在上述代码中,我们实现了`HtmlParser`接口,并重写了`parse`方法。在该方法中,我们可以通过`Document`对象获取网页的DOM结构,然后根据爬虫定义中的注解,解析出我们需要的数据并封装成`News`对象。
**2.1.4 管道定义**
管道定义是指在gecco框架中编写的用于处理解析结果的类。管道定义通常包括处理方法、数据存储和数据处理等。通过定义管道,我们可以指定如何处理解析结果,并将解析结果保存到数据库、文件等存储介质中。
以下是一个示例的管道定义代码:
```python
public class ConsolePipeline implements Pipeline<News> {
@Override
public void process(News news) {
System.out.println("ID: " + news.getId());
System.out.println("Title: " + news.getTitle());
// 其他字段处理...
}
}
```
在上述代码中,我们实现了`Pipeline`接口,并重写了`process`方法。在该方法中,我们可以对解析出的`News`对象进行处理,例如打印到控制台、保存到数据库等。
### 2.2 gecco框架的工作原理解析
gecco框架的工作原理可以总结为以下几个步骤:
1. 根据爬虫定义和请求定义,发送HTTP请求获取目标网页的HTML数据。
2. 根据爬虫定义中的注解,使用解析器定义解析HTML数据,得到需要的数据对象。
3. 将解析后的数据对象传递给管道定义进行处理,例如保存到数据库、输出到日志等。
4. 重复以上步骤,直到完成所有的数据抓取和处理任务。
通过以上的工作原理,gecco框架能够高效地实现数据的抓取、解析和处理,并提供丰富的配置和扩展能力,适用于各种场景的数据爬取需求。
在下一章节中,我们将介绍gecco框架的安装和配置方法。
# 3. gecco框架的安装与配置
在本章中,将介绍gecco框架的安装与配置步骤,以及常见问题的解决方法。
#### 3.1 安装gecco框架的前期准备
在安装gecco框架之前,需要确保系统中已经安装了Java运行环境(JRE)和Maven构建工具。首先,可以通过以下命令检查Java和Maven的安装情况:
```bash
java -version
mvn -v
```
如果以上命令可以成功执行并显示对应的版本信息,则说明Java和Maven已经正确安装。如果未安装,可以按照官方文档的指引进行安装。
#### 3.2 gecco框架的安装步骤详解
1. 创建Maven项目
使用以下命令在命令行或终端中创建一个Maven项目:
```bash
mvn archetype:generate -DgroupId=com.example -DartifactId=gecco-demo -DarchetypeArtifactId=maven-archetype-quickstart -DinteractiveMode=false
```
这将创建一个名为gecco-demo的Maven项目。
2. 添加gecco依赖
在Maven项目的pom.xml文件中,添加gecco的依赖:
```xml
<dependency>
<groupId>com.geccocrawler</groupId>
<artifactId>gecco</artifactId>
<version>1.3.6</version>
</dependency>
```
在完成以上步骤后,执行以下命令下载并安装gecco框架:
```bash
mvn clean install
```
#### 3.3 配置gecco框架的常见问题与解决方法
在使用gecco框架时,可能会遇到一些配置相关的常见问题,例如代理设置、请求头设置、并发爬取控制等。这些问题可以通过查阅官方文档或在gecco框架的相关社区中获取帮助。
若遇到网络请求失败、数据抓取不完整等问题,可以通过调整gecco框架的配置参数来解决。另外,gecco框架还提供了丰富的插件和扩展机制,可以根据需要进行定制化配置。
以上就是gecco框架的安装与配置相关内容,通过以上步骤可以快速搭建和配置gecco框架,实现数据的抓取和解析。
# 4. gecco框架的核心模块
在这一章节中,我们将详细介绍gecco框架的核心模块,包括数据抓取模块、数据解析模块和数据存储模块的详细解析。
#### 4.1 数据抓取模块详解
数据抓取模块是gecco框架的核心组成部分,它负责从目标网站上抓取所需的数据。gecco框架提供了灵活而强大的数据抓取功能,可以快速、高效地完成数据的抓取任务。以下是一个简单的Python爬虫示例,使用gecco框架来实现数据抓取:
```python
from com.geccocrawler.gecco import Gecco
from com.geccocrawler.gecco.annotation import RequestParameter
from com.geccocrawler.gecco.request import HttpRequest
from com.geccocrawler.gecco.spider import GeccoSpider
from com.geccocrawler.gecco.spider.render import PhantomJSRenderEngine
@Gecco(matchUrl="https://example.com", render=PhantomJSRenderEngine)
class MySpider(GeccoSpider):
@RequestParameter
url = ""
def pipeline(self, context):
# 抓取页面中的数据并进行处理
pass
startRequests = [HttpRequest("https://example.com")]
```
上述代码中,我们使用gecco框架定义了一个名为 MySpider 的爬虫,当匹配到 https://example.com 这个页面时,会触发数据抓取操作。同时使用了 PhantomJS 渲染引擎来动态加载页面内容,确保抓取到页面上的动态数据。在 pipeline 方法中可以对抓取到的数据进行处理,如解析、筛选、存储等操作。
#### 4.2 数据解析模块详解
数据解析模块负责对抓取到的数据进行解析和处理,gecco框架提供了丰富的解析功能,可以方便地提取和处理各种类型的数据。以下是一个简单的数据解析示例,使用gecco框架来实现对HTML页面的解析:
```python
from com.geccocrawler.gecco.annotation import Html
from com.geccocrawler.gecco.spider import GeccoSpider
@Html(gecco="div")
class MySpider(GeccoSpider):
def detail(self, context):
# 解析页面中的div标签,并提取所需的数据
pass
```
上述代码中,我们定义了一个名为 MySpider 的爬虫,通过 @Html 注解来告诉gecco框架解析页面中的 div 标签,并在 detail 方法中对所需数据进行提取和处理。
#### 4.3 数据存储模块详解
数据存储模块负责将解析和处理后的数据进行存储,gecco框架提供了多种数据存储方式,包括数据库存储、文件存储、分布式存储等。以下是一个简单的数据存储示例,使用gecco框架将解析后的数据存储到MongoDB数据库中:
```python
from com.geccocrawler.gecco.annotation import Text
from com.geccocrawler.gecco.pipeline import MongoPipeline
from com.geccocrawler.gecco.spider import GeccoSpider
class MySpider(GeccoSpider):
@Text
name = ""
pipeline = MongoPipeline
def onPipelineStart(self, context):
context.pipeline.input({
"name": self.name
})
```
上述代码中,我们定义了一个名为 MySpider 的爬虫,使用 @Text 注解来告诉gecco框架提取页面中的文本数据,并通过 MongoPipeline 将提取到的数据存储到MongoDB数据库中。
以上就是gecco框架核心模块的详细解析,数据抓取模块、数据解析模块和数据存储模块共同构成了gecco框架强大的数据处理能力。
# 5. gecco框架的应用场景与案例分析
在本章节中,我们将会介绍gecco框架在实际项目中的应用场景,并通过一些具体的案例分析来说明gecco框架的强大功能和优势。
#### 5.1 基于gecco框架的分布式爬虫案例分析
gecco框架提供了分布式爬虫的能力,可以将多个爬虫节点协同工作,提高数据抓取的效率和质量。我们以一个基于gecco框架的分布式爬虫案例来进行说明。
##### 场景描述:
假设我们需要从不同的电商网站上抓取商品信息,包括商品名称、价格、店铺名称等,以便进行价格比较和分析。
##### 代码实现:
```python
from com.geccocrawler.gecco import *
from com.geccocrawler.gecco.pipeline import PipelineFactory
from com.geccocrawler.gecco.request import *
from com.geccocrawler.gecco.spider import *
from com.geccocrawler.gecco.scheduler import RedisStartScheduler
from com.geccocrawler.gecco.exception import ShutdownHook
from com.geccocrawler.gecco.downloader import *
from com.geccocrawler.gecco.downloader.proxy import *
from com.geccocrawler.gecco.downloader import DownloaderContext
class GoodsSpider(Spider):
def __init__(self):
self.start_urls = ["http://www.example.com/goods"]
def start_requests(self):
for url in self.start_urls:
yield GetRequest(url)
@SubSpiderRule("http://www.example.com/goods/\w+")
class DetailSpider(Spider):
def extract(self, response):
goods_name = response.css("div#goods_name").text()
price = response.css("span.price").text()
shop_name = response.css("div.shop_name").text()
return {"goods_name": goods_name, "price": price, "shop_name": shop_name}
pipeline_factory = PipelineFactory("com.example.pipeline")
scheduler = RedisStartScheduler("com.example.scheduler", "redis://localhost:6379")
downloader = DownloaderContext().newBuilder().retry(3).timeoout(5000).builder()
spider_builder = SpiderContext().newBuilder(GoodsSpider, DetailSpider).pipeline_factory(pipeline_factory).scheduler(scheduler).downloader(downloader)
spider = spider_builder.build()
try:
spider.start()
spider.join()
except ShutdownHook:
spider.shutdown()
```
##### 代码说明:
- 首先,在`GoodsSpider`类中定义了抓取的起始URL,我们可以通过列表方式添加多个URL,这些URL将会成为爬虫的种子URL。
- 接着,通过`start_requests()`方法,我们可以对每个种子URL进行进一步的处理,生成相应的请求对象。
- 在`DetailSpider`类中使用了`@SubSpiderRule`注解,用来定义对URL的匹配规则,当URL匹配成功时,将会创建一个新的子爬虫进行处理。
- 在子爬虫的`extract()`方法中,我们可以通过CSS选择器对页面进行解析,并提取出我们所需要的数据。
- 同时,我们还可以通过定义管道(Pipeline)来处理从子爬虫中获取到的数据,例如保存到数据库或写入文件等。
- 在代码最后,我们通过建立一个`SpiderBuilder`对象,设置相应的配置项,并构建出一个爬虫对象。
- 最后,通过`spider.start()`方法启动爬虫,然后等待爬虫任务完成。
##### 结果说明:
通过以上实例,我们可以看到gecco框架提供了强大的分布式爬虫能力,可以通过配置的方式,简单灵活地将多个爬虫节点组合在一起,实现高效地数据抓取和处理。
#### 5.2 基于gecco框架的数据抓取与处理应用案例分析
gecco框架不仅可以应用在爬虫领域,还可以用于各种数据抓取与处理的应用。以下是一个基于gecco框架的数据抓取与处理应用案例分析。
##### 场景描述:
假设我们需要从一个新闻网站上抓取特定类别的新闻列表,并将抓取到的新闻转化为指定格式的JSON文件,用于其他系统进一步处理。
##### 代码实现:
```java
@Gecco(matchUrl="http://www.example.com/news/{category}", pipelines={"consolePipeline", "jsonFilePipeline"})
public class NewsSpider implements HtmlBean {
private static final long serialVersionUID = -377053120283382723L;
@RequestParameter("category")
private String category;
@HtmlField(cssPath="div.item")
private List<NewsItem> newsList;
public String getCategory() {
return category;
}
public void setCategory(String category) {
this.category = category;
}
public List<NewsItem> getNewsList() {
return newsList;
}
public void setNewsList(List<NewsItem> newsList) {
this.newsList = newsList;
}
public static void main(String[] args) {
GeccoEngine.create()
.classpath("com.example")
.start("http://www.example.com/news/{category}")
.param("category", "sports")
.interval(2000)
.thread(3)
.run();
}
}
@Gecco(matchUrl="http://www.example.com/news/detail/{id}", pipelines="consolePipeline")
public class NewsDetailSpider implements HtmlBean {
private static final long serialVersionUID = -377053120283382723L;
@RequestParameter("id")
private String id;
@HtmlField(cssPath="div.title")
private String title;
@HtmlField(cssPath="div.content")
private String content;
public String getId() {
return id;
}
public void setId(String id) {
this.id = id;
}
public String getTitle() {
return title;
}
public void setTitle(String title) {
this.title = title;
}
public String getContent() {
return content;
}
public void setContent(String content) {
this.content = content;
}
}
@PipelineName("consolePipeline")
public class ConsolePipeline implements Pipeline<HtmlBean> {
@Override
public void process(HtmlBean bean) {
System.out.println(bean);
}
}
@PipelineName("jsonFilePipeline")
public class JsonFilePipeline implements Pipeline<HtmlBean> {
@Override
public void process(HtmlBean bean) {
String json = JSON.toJSONString(bean);
// 写入JSON文件逻辑
}
}
public class NewsItem {
@HtmlField(cssPath="a.title")
private String title;
@HtmlField(cssPath="span.date")
private String date;
// Getters and setters
}
```
##### 代码说明:
- 在`NewsSpider`类中,使用`@Gecco`注解标记了匹配的URL,并通过`matchUrl`属性指定了URL的模式,其中{category}是一个占位符。
- `@RequestParameter`注解被用于绑定URL模式中的参数,这样我们可以通过参数来指定特定的新闻类别。
- `@HtmlField`注解用于指定CSS选择器来抓取页面中的相应字段,例如新闻的标题和日期。
- 在`NewsDetailSpider`类中,我们也是使用了`@Gecco`注解来标记匹配的URL,并通过`matchUrl`属性指定了URL的模式。
- `@PipelineName`注解用于指定该管道要向哪个`Pipeline`实现类进行处理。
- `NewsItem`类用来存储抓取到的新闻项,包括标题和日期。
- 在`NewsSpider`的`main`方法中,我们通过`GeccoEngine`来构建和启动爬虫,设置了一些相应的参数,例如起始URL、参数、抓取间隔时间、线程数等。
##### 结果说明:
通过以上实例,我们可以看到gecco框架可以灵活应用在各种数据抓取与处理的应用中。通过设置匹配URL、HTML字段抓取、管道等相关配置,我们可以实现自定义的数据抓取和处理逻辑,并且能够方便地扩展和定制。
# 6. 结论与展望
### 6.1 对gecco框架的总结与评价
经过分析和实践,我们对gecco框架进行总结和评价如下:
- gecco框架具有简单易用的特点,开发者可以通过简单的配置和扩展,快速构建自己的爬虫应用。
- gecco框架提供了强大的数据抓取、解析和存储功能,支持多种数据源的抓取和处理。
- gecco框架设计良好,具有良好的扩展性和可维护性,开发者可以根据自己的需求进行二次开发和定制。
总体而言,gecco框架是一款功能强大、易用性高的爬虫框架,可以满足大部分爬虫应用的需求。
### 6.2 gecco框架的发展前景与应用前景展望
随着互联网的不断发展和数据的日益增加,对数据的抓取、处理和分析的需求也越来越大。gecco框架作为一款优秀的爬虫框架,具有广阔的应用前景和发展前景。
在未来,我们可以预见gecco框架在以下领域有更多的应用:
- 数据采集和监控:gecco框架可以帮助用户快速搭建数据采集和监控系统,实时获取和分析互联网上的数据。
- 信息抓取和处理:gecco框架可以用于抓取和处理各类网站的信息,如新闻信息、商品价格等。
- 数据挖掘和分析:gecco框架可以支持大规模数据的抓取和处理,用于数据挖掘和分析领域的研究和应用。
总之,gecco框架具有广泛的应用前景,未来有望在数据领域发挥更大的作用。
以上是对gecco框架的结论与展望,希望能够为读者提供一定的参考和帮助。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
gecco专栏深入探讨了一个强大的分布式并发计算框架gecco,通过一系列详细的文章,全面介绍了gecco的基本概念、架构、部署与配置、任务调度与管理、数据传输与同步、容错与恢复、任务拆分与并行计算、数据分布与负载均衡等方面的内容。同时,还涵盖了gecco在大规模数据处理与分析、机器学习与深度学习中的应用,以及与Hadoop、Spark等大数据框架的整合、容器化与微服务架构实践、安全性与权限管理、数据流处理结合等领域的应用。gecco专栏内容涵盖了从基础概念到高级应用的全面内容,旨在帮助读者全面了解并充分利用gecco框架进行分布式并发计算,是一份权威的指南和实用的工具。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
扇形菜单高级应用

# 摘要
扇形菜单作为一种创新的用户界面设计方式,近年来在多个应用领域中显示出其独特优势。本文概述了扇形菜单设计的基本概念和理论基础,深入探讨了其用户交互设计原则和布局算法,并介绍了其在移动端、Web应用和数据可视化中的应用案例
C++ Builder高级特性揭秘:探索模板、STL与泛型编程

# 摘要
本文系统性地介绍了C++ Builder的开发环境设置、模板编程、标准模板库(STL)以及泛型编程的实践与技巧。首先,文章提供了C++ Builder的简介和开发环境的配置指导。接着,深入探讨了C++模板编程的基础知识和高级特性,包括模板的特化、非类型模板参数以及模板
【深入PID调节器】:掌握自动控制原理,实现系统性能最大化

# 摘要
PID调节器是一种广泛应用于工业控制系统中的反馈控制器,它通过比例(P)、积分(I)和微分(D)三种控制作用的组合来调节系统的输出,以实现对被控对象的精确控制。本文详细阐述了PID调节器的概念、组成以及工作原理,并深入探讨了PID参数调整的多种方法和技巧。通过应用实例分析,本文展示了PID调节器在工业过程控制中的实际应用,并讨
【Delphi进阶高手】:动态更新百分比进度条的5个最佳实践

# 摘要
本文针对动态更新进度条在软件开发中的应用进行了深入研究。首先,概述了进度条的基础知识,然后详细分析了在Delphi环境下进度条组件的实现原理、动态更新机制以及多线程同步技术。进一步,文章探讨了数据处理、用户界面响应性优化和状态视觉呈现的实践技巧,并提出了进度
【TongWeb7架构深度剖析】:架构原理与组件功能全面详解
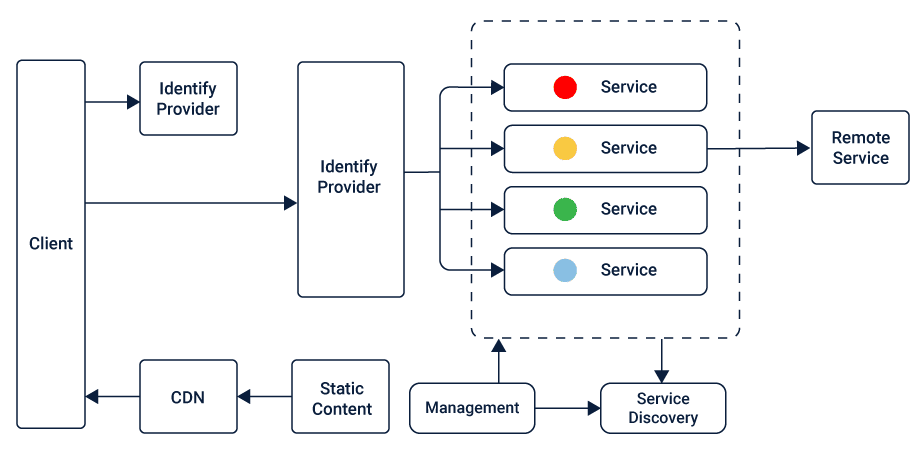
# 摘要
TongWeb7作为一个复杂的网络应用服务器,其架构设计、核心组件解析、性能优化、安全性机制以及扩展性讨论是本文的主要内容。本文首先对TongWeb7的架构进行了概述,然后详细分析了其核心中间件组件的功能与特点,接着探讨了如何优化性能监控与分析、负载均衡、缓存策略等方面,以及安全性机制中的认证授权、数据加密和安全策略实施。最后,本文展望
【S参数秘籍解锁】:掌握驻波比与S参数的终极关系
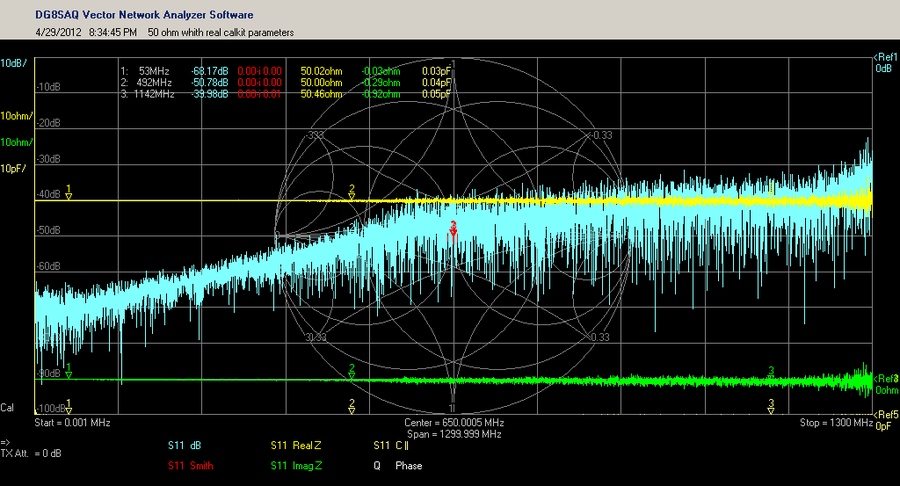
# 摘要
本论文详细阐述了驻波比与S参数的基础理论及其在微波网络中的应用,深入解析了S参数的物理意义、特性、计算方法以及在电路设计中的实践应用。通过分析S参数矩阵的构建原理、测量技术及仿真验证,探讨了S参数在放大器、滤波器设计及阻抗匹配中的重要性。同时,本文还介绍了驻波比的测量、优化策略及其与S参数的互动关系。最后,论文探讨了S参数分析工具的使用、高级分析技巧,并展望
【嵌入式系统功耗优化】:JESD209-5B的终极应用技巧
# 摘要
本文首先概述了嵌入式系统功耗优化的基本情况,随后深入解析了JESD209-5B标准,重点探讨了该标准的框架、核心规范、低功耗技术及实现细节。接着,本文奠定了功耗优化的理论基础,包括功耗的来源、分类、测量技术以及系统级功耗优化理论。进一步,本文通过实践案例深入分析了针对JESD209-5B标准的硬件和软件优化实践,以及不同应用场景下的功耗优化分析。最后,展望了未来嵌入式系统功耗优化的趋势,包括新兴技术的应用、JESD209-5B标准的发展以及绿色计算与可持续发展的结合,探讨了这些因素如何对未来的功耗优化技术产生影响。
# 关键字
嵌入式系统;功耗优化;JESD209-5B标准;低功耗
ODU flex接口的全面解析:如何在现代网络中最大化其潜力
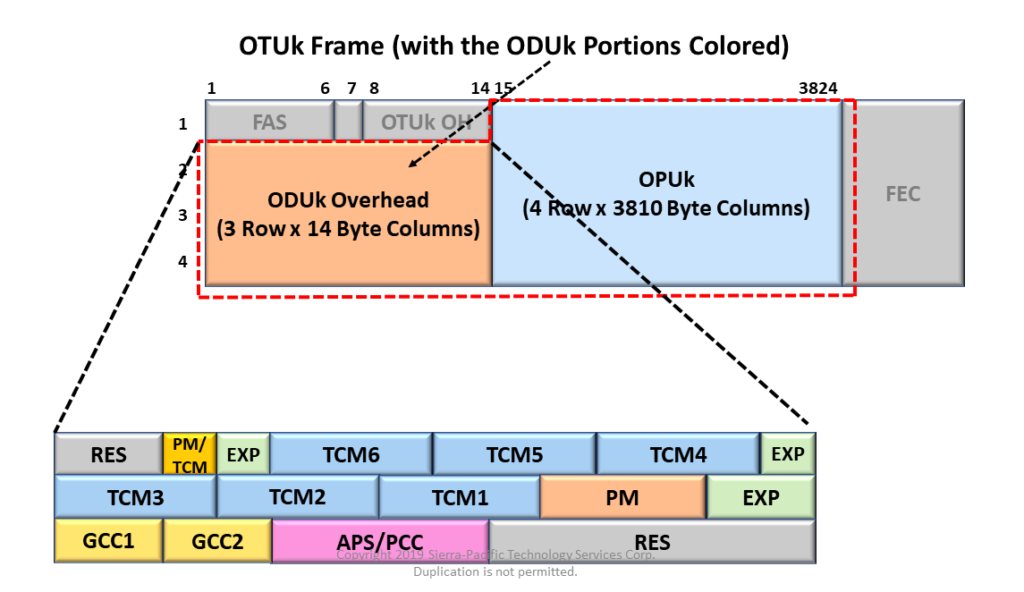
# 摘要
ODU flex接口作为一种高度灵活且可扩展的光传输技术,已经成为现代网络架构优化和电信网络升级的重要组成部分。本文首先概述了ODU flex接口的基本概念和物理层特征,紧接着深入分析了其协议栈和同步机制,揭示了其在数据中心、电信网络、广域网及光纤网络中的应用优势和性能特点。文章进一步
如何最大化先锋SC-LX59的潜力
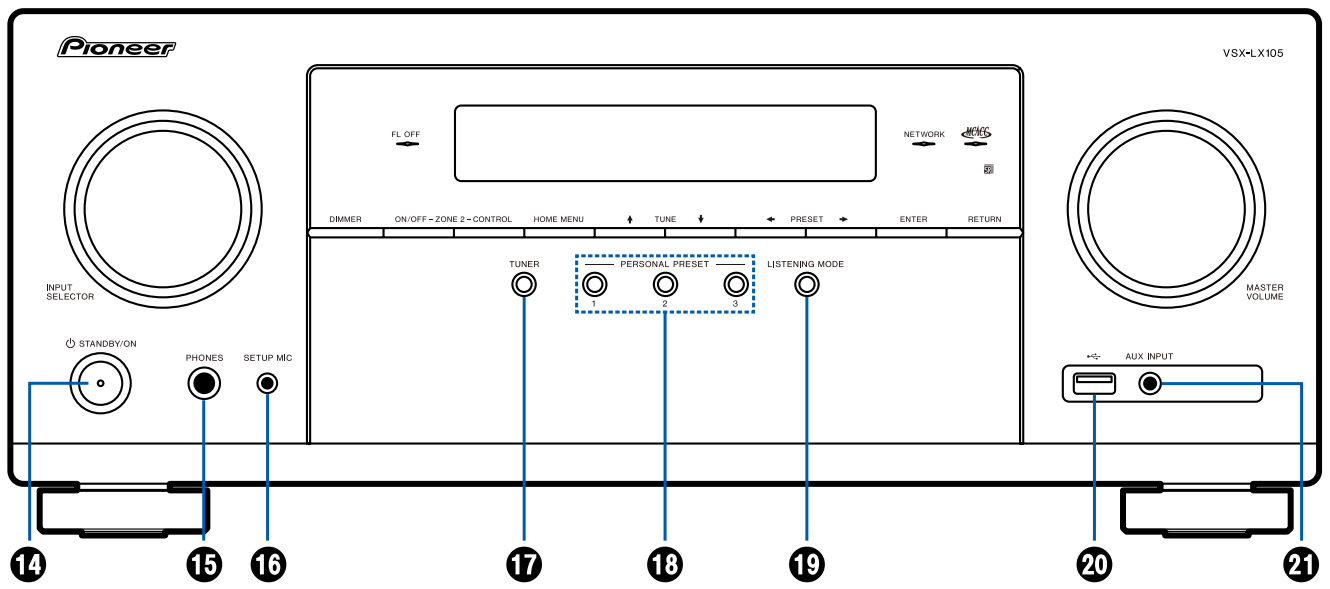
# 摘要
先锋SC-LX59作为一款高端家庭影院接收器,其在音视频性能、用户体验、网络功能和扩展性方面均展现出巨大的潜力。本文首先概述了SC-LX59的基本特点和市场潜力,随后深入探讨了其设置与配置的最佳实践,包括用户界面的个性化和音画效果的调整,连接选项与设备兼容性,以及系统性能的调校。第三章着重于先锋SC-LX59在家庭影院中的应用,特别强调了音视频极致体验、智能家居集成和流媒体服务的充分利用。在高
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )