初识alluxio:分布式内存计算框架的介绍
发布时间: 2023-12-15 11:09:53 阅读量: 31 订阅数: 34 
# 1. 引言
## 1.1 介绍alluxio
Alluxio是一个开源的分布式内存计算框架,旨在加速大数据处理和分析工作负载的速度。它提供了一个统一命名空间,用于将数据存储在内存中,并通过快速访问进行读取和写入。
## 1.2 目的和意义
随着大数据技术的发展和普及,传统的分布式存储系统在处理大规模数据时面临一些挑战,比如高延迟、低吞吐量等。Alluxio作为一种分布式内存计算框架,旨在解决这些问题,提供高速的数据访问和处理能力。
Alluxio可以与各种计算框架(如Apache Hadoop、Apache Spark等)无缝集成,使得这些计算框架可以利用内存中的数据进行计算,从而大幅提升整体的计算性能。
## 1.3 文章结构概览
本文将深入介绍Alluxio这个分布式内存计算框架,包括其基本概念、架构与工作原理、应用场景、部署与管理以及未来展望等方面。
在第二章中,我们将介绍Alluxio的基本概念,包括分布式内存计算框架的定义、Alluxio的主要特点以及与其他分布式存储系统的对比。
第三章将详细讲解Alluxio的架构与工作原理,包括整体架构以及在数据存储和访问层面的工作原理。
第四章将探讨Alluxio在实际场景中的应用,包括在大数据处理、内存计算以及深度学习等领域的使用案例。
第五章将介绍Alluxio的部署与管理,包括部署方式及要求、集群的管理与监控以及性能调优等方面。
最后,在第六章中,我们将展望Alluxio的未来发展趋势,并对其在分布式内存计算领域的地位进行分析和总结。在结语部分,我们将强调Alluxio对分布式内存计算框架的意义和重要性。
希望通过本文的介绍,读者们能够对Alluxio有一个全面而深入的了解,并能够在实际应用中灵活运用,提升大数据处理和分析的效率!
# 2. alluxio的基本概念
### 2.1 分布式内存计算框架简介
分布式内存计算框架是一种通过将数据存储在内存中,并使用分布式计算模型进行数据处理和计算的方法。它将数据存储在分布式内存中,以提高数据访问速度和计算效率。与传统的磁盘存储相比,分布式内存计算框架具有更低的访问延迟和更高的计算吞吐量。
### 2.2 alluxio的主要特点
alluxio是一种开源的分布式内存计算框架,具有以下主要特点:
- **高性能**:alluxio支持将数据存储在内存中,以加速数据访问速度。它还提供了高度并发的数据访问能力,以支持大规模数据处理和计算。
- **数据共享**:alluxio提供了高效的数据共享机制,可以将数据从一个存储系统快速地移动到另一个存储系统,实现不同系统之间的数据共享和互操作。
- **数据持久化**:alluxio支持将数据持久化到各种类型的存储系统中,包括本地磁盘、分布式文件系统、对象存储等。这使得用户可以根据自己的需求选择最适合的存储系统。
- **数据一致性**:alluxio通过提供一致性模型和数据写入策略,确保在多个计算节点上的数据一致性。这对于大规模分布式计算和数据处理非常重要。
### 2.3 alluxio与其他分布式存储系统的对比
alluxio与其他分布式存储系统相比具有以下特点:
- **与Hadoop兼容**:alluxio可以与Hadoop生态系统无缝集成,支持Hadoop MapReduce、Spark等框架,提供高效的数据访问和计算能力。
- **更高的性能**:alluxio将数据存储在内存中,提供更低的访问延迟和更高的计算吞吐量。与基于磁盘的存储系统相比,alluxio具有更高的性能优势。
- **更灵活的数据共享**:alluxio提供了高效的数据共享机制,可以快速地将数据从一个存储系统移动到另一个存储系统,实现不同系统之间的数据共享和互操作。
- **更强大的一致性模型**:alluxio提供了一致性模型和数据写入策略,确保在多个计算节点上的数据一致性。与其他分布式存储系统相比,alluxio具有更强大的一致性保证。
总的来说,alluxio是一种高性能、灵活和可靠的分布式内存计算框架,它在大数据处理和内存计算领域具有广泛的应用前景。在接下来的章节中,我们将深入探讨alluxio的架构和工作原理,以及在实际场景中的应用。
# 3. alluxio的架构与工作原理
在本章中,我们将详细介绍alluxio的架构和工作原理。
#### 3.1 alluxio的整体架构
alluxio是一个层级存储系统,它由三个关键的组件组成:Master、Worker 和Client。Master负责元数据管理,Worker负责数据存储,而Client则是用户与系统交互的接口。
alluxio的整体架构如下图所示:
```
+-------------------------------------------------------+
| Alluxio Cluster |
+-----------------------+-------------------------------+
| Client | Master |
+-----------------------+-------------------------------+
| | |
| | +-------------+ |
| | | Worker | |
| | +-------------+ |
| | |
| +----------+ | +-------------+ |
| | App | | | Worker | |
| +----------+ | +-------------+ |
| | |
+-----------------------+-------------------------------+
```
#### 3.2 数据存储层面的工作原理
在alluxio中,数据被划分为一系列的块(block)。当数据被写入系统时,它会被分割为多个块,并存储在不同的Worker节点上。而对于读取操作,alluxio会根据用户的访问请求,将数据块从Worker节点读取到内存中,以加速访问。
alluxio还支持数据的复制与容错机制。当Worker节点失效时,alluxio会自动将数据从其他可用的Worker节点上进行复制,以保障数据的可靠性和高可用性。
#### 3.3 数据访问层面的工作原理
在alluxio中,数据的访问可以分为两种模式:读(read)和写(write)。
对于读操作,当Client请求读取数据时,alluxio会首先检查数据是否在内存中,如果是,则直接返回给用户。如果数据不在内存中,则alluxio会根据策略从磁盘或者其他存储系统中(如HDFS)读取数据,并将数据缓存到内存中,以便后续快速访问。
对于写操作,当Client请求写入数据时,alluxio会将数据写入到Worker节点的内存中,然后异步地将数据写入到底层的存储系统(如HDFS)。这种方式可以避免数据写入时的磁盘开销,提高写入性能。
综上所述,alluxio通过内存存储和数据缓存,以及智能的数据访问策略,实现了快速访问和高性能的分布式存储系统。
希望本章内容对你理解alluxio的架构和工作原理有所帮助。下一章,我们将介绍alluxio在实际场景中的应用。
# 4. alluxio在实际场景中的应用
在前面的章节中,我们已经了解了alluxio的基本概念、架构及工作原理。本章我们将探讨alluxio在实际场景中的应用。
#### 4.1 alluxio在大数据处理中的角色
alluxio作为分布式内存计算框架,具有快速访问分布式存储的能力,因此在大数据处理中扮演着重要的角色。下面介绍几个典型的应用场景:
**实时数据处理**:在实时数据处理任务中,通常需要快速读取和处理大量的数据,alluxio可以将热数据缓存在内存中,加快数据访问速度,提高实时处理的性能。
**批处理作业**:对于需要频繁读取和写入数据的批处理作业,alluxio可以作为中间存储层,加速数据的读写操作,减少对底层存储系统的压力。
**数据缓存**:alluxio可以作为数据的缓存层,将热数据缓存在内存中,减少对底层存储系统的访问,提高数据访问的效率。
#### 4.2 alluxio在内存计算中的应用
alluxio作为分布式内存计算框架,可以为内存计算任务提供高速的数据访问能力。以下是几个内存计算领域的应用案例:
**机器学习**:在机器学习任务中,通常需要处理大规模的数据集,并进行大量的计算,alluxio可以将数据集缓存在内存中,提供高速的数据访问,加快模型训练的速度。
```python
# 代码示例:使用alluxio缓存数据集
import tensorflow as tf
import alluxio
import numpy as np
# 从alluxio分布式存储系统中读取数据集
with alluxio.open('/data/dataset.txt') as f:
dataset = np.loadtxt(f)
# 将数据集缓存在内存中
dataset = tf.convert_to_tensor(dataset)
# 在内存中进行模型训练
# ...
# 将模型保存到alluxio分布式存储系统
model.save('/model/model.pb')
```
**实时分析**:在实时分析任务中,alluxio可以作为快速数据访问的中间层,加速数据的读取和计算,提高分析结果的实时性。
**图计算**:在图计算任务中,alluxio可以缓存图数据,提供高速的数据访问能力,加速图算法的执行速度。
#### 4.3 alluxio在深度学习等领域的使用案例
除了上述应用场景外,alluxio在深度学习等领域也有广泛的应用。以下是一些使用案例:
**分布式深度学习**:在分布式深度学习任务中,alluxio可以作为数据的分布式存储层,提供数据访问的统一接口,简化数据处理的过程。
**迁移学习**:在迁移学习任务中,通常需要使用一个已经训练好的模型来解决新的问题,alluxio可以用于存储和共享已经训练好的模型,简化迁移学习的流程。
以上是alluxio在实际场景中的一些应用示例,随着分布式内存计算框架的发展,相信在更多领域中会有更多的应用场景出现。
在下一章中,我们将介绍alluxio的部署与管理。
# 5. alluxio的部署与管理
在本章中,我们将介绍如何部署和管理alluxio集群,并讨论一些性能调优的方法。
#### 5.1 alluxio的部署方式及要求
alluxio的部署方式有多种选择,可以根据不同的需求和环境选择适合的方式。下面我们列举了几种常见的部署方式:
1. 单机模式(Standalone Mode):适用于测试和开发环境,所有的alluxio组件都运行在一台机器上。
```shell
./bin/alluxio-start.sh local
```
2. 伪分布式模式(Pseudo-Distributed Mode):适用于模拟分布式环境,所有的alluxio组件运行在同一台机器上,但它们会使用不同的端口号。
```shell
./bin/alluxio-start.sh master
./bin/alluxio-start.sh worker
```
3. 分布式模式(Distributed Mode):适用于真实的分布式环境,alluxio的各个组件运行在不同的机器上。首先需要编辑配置文件`conf/alluxio-site.properties`,配置各个节点的信息,包括master节点和worker节点。
```shell
./bin/alluxio-start.sh all SudoMount # 启动所有节点的master和worker
```
在部署alluxio集群之前,还需要确保满足以下的要求:
- 操作系统要求:支持Linux和MacOS,并安装了Java
- 网络要求:确保所有的节点都能相互通信,可以通过ping命令来测试
- 存储要求:每个节点都需要至少一个目录来存储alluxio的数据,这些目录可以是本地文件系统、HDFS、S3等。
#### 5.2 alluxio集群的管理与监控
一旦alluxio集群部署成功,就需要进行相应的管理和监控工作,以确保集群的稳定运行和高性能。
alluxio提供了Web界面来方便运维人员进行集群管理和监控。可以通过访问`http://<master-node>:19999`来查看集群的运行状态、配置信息、工作进程等。
除了Web界面,alluxio还提供了一些命令行工具来管理集群,例如:
- `./bin/alluxio fsadmin report`:生成关于文件系统状态和容量的报告
- `./bin/alluxio fsadmin report -uptime`:生成关于文件系统状态、容量和工作进程运行时间的报告
- `./bin/alluxio fsadmin workers`:列出所有的worker节点以及它们的状态和负载信息
通过命令行工具和Web界面,可以及时了解集群的运行情况,进行故障处理和性能调优。
#### 5.3 alluxio的性能调优
为了获得更好的性能,我们可以对alluxio进行一些调优。
首先,可以通过修改配置文件`conf/alluxio-site.properties`来调整系统的参数,例如:
- `alluxio.user.file.metadata.cache.max.size`:设置文件元数据缓存的最大大小
- `alluxio.user.file.metadata.cache.expiration.time`:设置文件元数据缓存的过期时间
- `alluxio.user.file.capacity.ahead.factor`:设置在写入文件之前分配的缓冲区容量
- `alluxio.master.metastore.dirs`:设置元数据存储的目录
- `alluxio.worker.tieredstore.level0.alias`:设置第一级存储的别名
- `alluxio.worker.tieredstore.level0.dirs.path`:设置第一级存储的目录路径
其次,可以根据不同的应用场景来选择合适的数据读写策略和缓存策略,以提高系统的性能。
最后,可以监控集群的运行情况,及时发现和解决性能瓶颈问题,例如通过日志分析、性能测试等方式。
总结起来,alluxio的部署和管理是保证集群高效运行的重要环节,通过适当的调优可以提升系统的性能和可靠性。
在下一章中,我们将展望alluxio的未来发展,并对其在分布式内存计算领域的地位进行分析。
希望这一章的内容能帮助你更好地理解和应用alluxio。
# 6. 未来展望与结语
## 6.1 alluxio未来的发展趋势
alluxio作为一种新兴的分布式内存计算框架,目前已在大数据处理、内存计算和深度学习等领域得到了广泛的应用。随着大数据和人工智能技术的不断发展,alluxio的未来发展趋势值得关注。
首先,alluxio将继续优化其性能和稳定性,提供更高效、更可靠的分布式内存计算解决方案。通过对底层数据存储和访问的优化,alluxio可以更快速地处理大规模数据,并提供更低的延迟。
其次,alluxio将进一步扩展其在大数据生态系统中的应用。alluxio已经与Hadoop、Spark等常用的大数据处理框架进行了集成,未来将与更多的开源框架进行深入合作,使得alluxio在大数据处理中发挥更大的作用。
另外,alluxio还将加强与云计算平台的集成,提供更好的云原生支持。随着越来越多的企业将其数据部署到云端,alluxio将适应这一趋势,并提供更便捷的部署和管理方式。
最后,alluxio将继续推动其社区的发展,吸引更多的开发者和用户参与其中。通过开展技术交流、举办活动等方式,alluxio社区将共同推动分布式内存计算的发展,为用户提供更好的支持和服务。
## 6.2 alluxio在分布式内存计算领域的地位
alluxio作为一种分布式内存计算框架,具有重要的地位和价值。首先,alluxio提供了高效的数据存储和访问方式,可以在内存和存储之间提供快速的数据交换,提高了计算效率。
其次,alluxio与现有的大数据处理框架和机器学习框架无缝集成,可以作为数据服务层,为上层应用提供高速、可扩展的数据访问接口。
另外,alluxio具有良好的扩展性和可定制性。开发者可以根据自己的需求,对alluxio进行二次开发和定制化,以满足特定的业务需求。
最后,alluxio的开源性质使得其具有广泛的适用性和可移植性。用户可以根据自己的需求选择部署在私有云、公有云或混合云环境中,灵活地构建自己的分布式内存计算平台。
## 6.3 结语:alluxio对分布式内存计算框架的意义
本文介绍了alluxio这一分布式内存计算框架的基本概念、架构和工作原理,并探讨了其在实际场景中的应用和未来的发展趋势。
作为一种分布式内存计算框架,alluxio在大数据处理、内存计算和深度学习等领域具有重要的地位和价值。它通过将数据存储在内存中,提供了高速的数据访问和计算能力,大大提高了大数据处理的效率。
未来,alluxio将进一步发展和完善,为用户提供更好的支持和服务。我们期待alluxio在分布式内存计算领域的继续创新和突破,为大数据处理和人工智能技术的发展做出更大的贡献。
希望本文能为读者对alluxio这一分布式内存计算框架有更深入的了解,为实际应用提供一些参考和指导。各位读者如果对alluxio或者本文有任何疑问或建议,欢迎留言讨论。谢谢!

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
专栏《alluxio》涵盖了深入全面的介绍、解析和应用探索,为读者呈现了分布式内存计算框架alluxio的全貌。从其基础概念、架构解析到高效数据缓存实现,以及分层存储管理策略、数据加速优势与挑战等方面展开深入探讨。此外,还涉及alluxio与Hadoop的集成、数据访问与传输简化、数据中心跨地域复制等实践应用,以及在实时数据处理、快速数据分析、机器学习、深度学习、大规模图处理、数据预处理、大规模数据清洗与过滤、安全性与权限管理、分布式数据共享与协作、物联网大数据处理等领域的应用。通过本专栏,读者将全面了解alluxio的各个方面,深入掌握其原理和应用场景,为实际项目应用提供充分的参考与指引。
专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【PFC5.0数据流分析】:深入理解数据处理过程的完整指南

参考资源链接:[PFC5.0用户手册:入门与教程](https://wenku.csdn.net/doc/557hjg39sn?sp
电动汽车充电效率提升:SAE J1772标准实施难点的解决方案

参考资源链接:[SAE J1772-2017.pdf](https://wenku.csdn.net/doc/6412b74abe7fbd1778d
【ASP.NET Core Web API设计】:构建RESTful服务的最佳实践

参考资源链接:[ASP.NET实用开发:课后习题详解与答案](https://wenku.csdn.net/doc/649e3a1550e8173efdb59dbe?spm=1055.2635.3001.10343)
# 1. ASP.NET
【高级控制算法】:提高FANUC 0i-MF系统精度的算法优化,技术解析
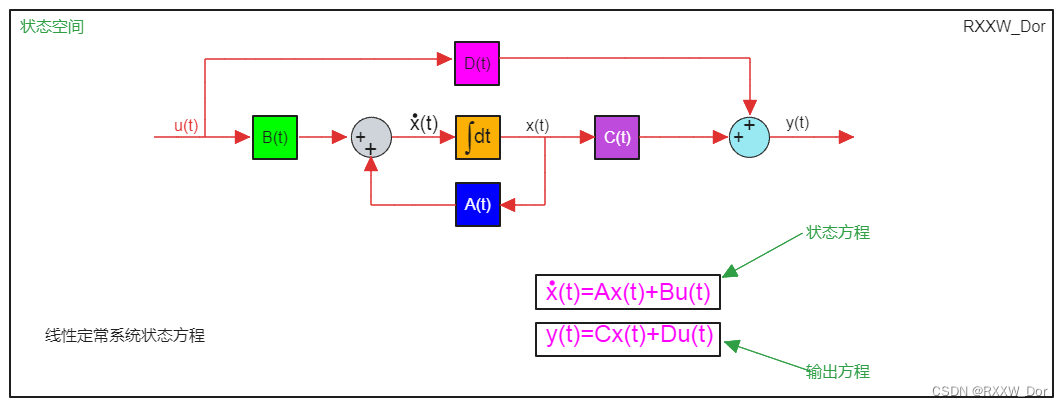
参考资源链接:[FANUC 0i-MF 加工中心系统操作与安全指南](https://wenku.csdn.net/doc/6401ac08cce7214c316ea60a?spm=1055.2635.3001.10343)
# 1. ```
# 第一章:FANUC 0i-MF系统与控制算法概述
FANUC 0i-MF系统作为现代工业自动化领域的重要组成部分,以其卓越的控制性能和可靠性在数控机床等领域得到广泛应用。本章将从系统架构、控制算法类型
iSecure Center审计功能:合规性监控与审计报告完全解析

参考资源链接:[iSecure Center 安装指南:综合安防管理平台部署步骤](https://wenku.csdn.net/doc/2f6bn25sjv?spm=1055.2635.3001.10343)
# 1. iSecure Center审计功能概述
## 1.1 了解iSecure Center
iSecure Center是一个高效的审计和合规性
硬盘SMART故障处理:从警告到数据恢复的全过程
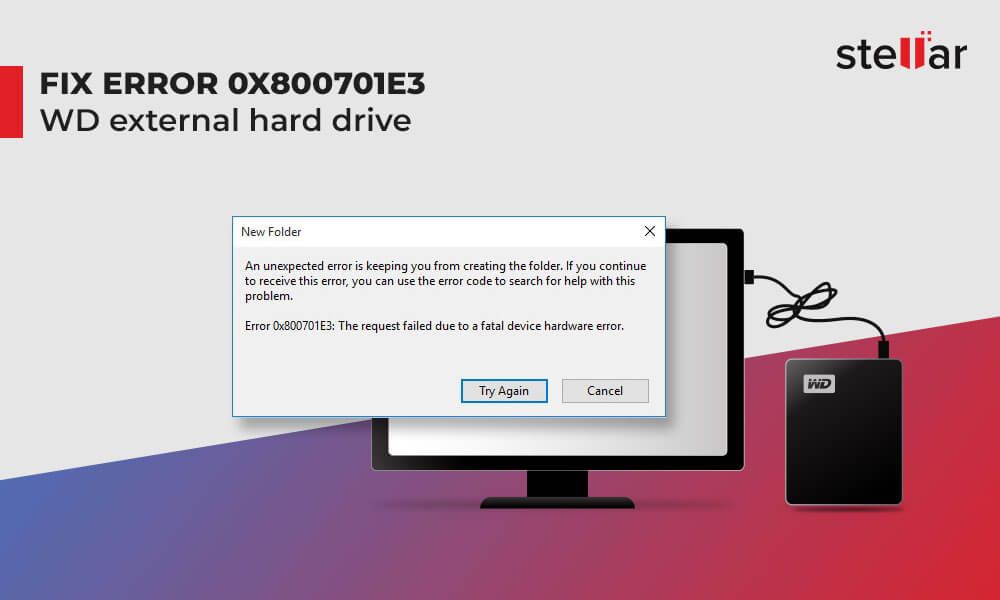
参考资源链接:[硬盘SMART错误警告解决办法与诊断技巧](https://wenku.csdn.net/doc/7cskgjiy20?spm=1055.2635.3001.10343)
# 1. 硬盘SMART技术概述
硬盘自监测、分析和报告技术(SMART)是用于监控硬盘健康状况的一种方法,旨在提前预警潜在的硬盘
避免IDEA编译卡顿:打开自动编译的正确方式
参考资源链接:[IDEA 开启自动编译设置步骤](https://wenku.csdn.net/doc/646ec8d7d12cbe7ec3f0b643?spm=1055.2635.3001.10343)
# 1. 自动编译在IDEA中的重要性
自动编译功能是现代集成开发环境(IDE)中不可或缺的一部分,特别是在Java开发中,IntelliJ
WINCC与操作系统版本兼容性:专家分析与实用指南
参考资源链接:[Windows XP下安装WINCC V6.0/V6.2错误解决方案](https://wenku.csdn.net/doc/6412b6dcbe7fbd1778d483df?spm=1055.2635.3001.10343)
# 1. WinCC与操作系统兼容性的基础了解
## 1.1 软件与操作系统兼容性的重要性
在工业自动化领域,Win
STM32F103VET6外围设备接口设计:原理图要点揭秘

参考资源链接:[STM32F103VET6 PCB原理详解:最小系统板与电路布局](https://wenku.csdn.net/doc/6412b795be7fbd1778d4ad36?spm=1055.2635.3001.10343)
# 1. STM32F103VET6简介与外围设备概述
## 1.1 STM32F103VET6概述
STM32F103VE
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )