Hadoop入门学习:构建分布式计算与高可用架构
需积分: 10 189 浏览量
更新于2024-07-17
收藏 1.04MB DOCX 举报
Hadoop阶段初识学习笔记主要介绍了Apache Hadoop的基本概念和核心特性,这是一个开源的分布式计算框架,由Doug Cutting和Mike Cafarella共同创建。Hadoop的核心理念是通过简单易用的编程模型来处理大规模数据集,其设计目标是能够无缝扩展到成千上万台计算机组成的集群,每台机器都负责部分计算和存储任务。
首先,Hadoop官方网站(http://hadoop.apache.org/)提供了项目的详细介绍和下载资源。Hadoop的主要功能是实现高可用性和可扩展性,它不依赖单一硬件节点的可靠性,而是通过软件层面的设计来处理节点故障,确保服务的连续性。这意味着即使在某个节点出现故障时,Hadoop集群仍然能够继续运行,并能自动恢复数据处理任务。
Hadoop的核心组件包括Hadoop Distributed File System (HDFS) 和 MapReduce。HDFS是一个分布式文件系统,用于存储大量数据,它将数据分散在多台机器上,提供高容错性和吞吐量。MapReduce则是一种编程模型,它将复杂的计算任务划分为多个独立的部分(映射阶段和规约阶段),分别在不同的节点上执行,最后将结果合并。
学习Hadoop的第一天,你可以理解到Hadoop的优势在于其对大数据的高效处理能力和处理大规模并行计算的能力。通过Hadoop,开发者可以构建能够处理PB级别的数据的应用程序,而无需过多关注底层的复杂性。此外,Hadoop生态系统还包括其他工具如Hive(SQL查询接口)、Pig(高级数据流语言)和Spark(实时计算框架),它们进一步增强了Hadoop的功能和灵活性。
Hadoop阶段的学习将引导你步入一个强大的数据处理世界,让你掌握分布式计算的基础知识,以及如何利用Hadoop进行大数据的存储、处理和分析。这是一项必备技能,对于云计算、大数据分析和人工智能等领域都有广泛应用。
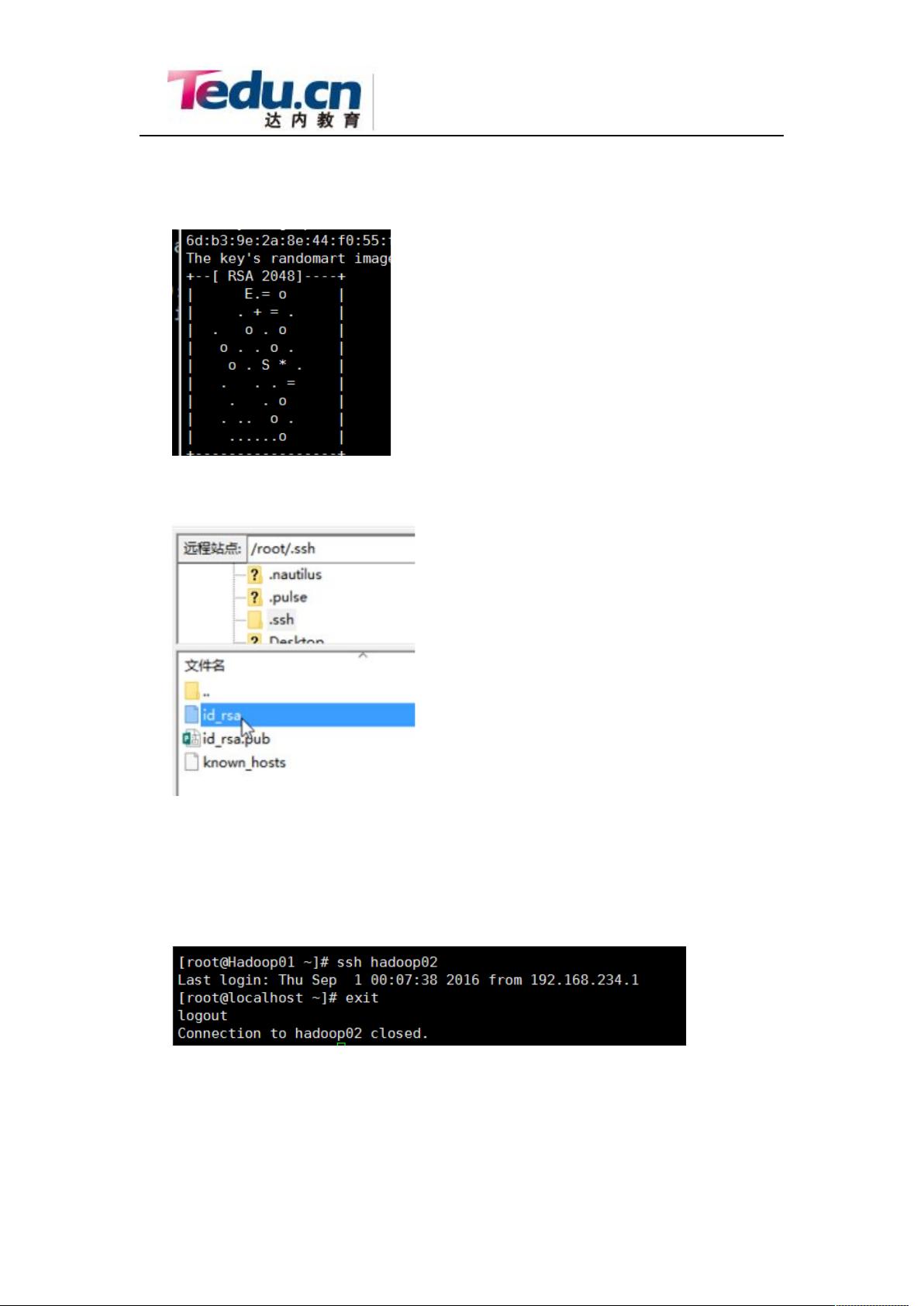
在 hadoop01 节点执行:
执行:ssh-keygen
然后一直回车
生成节点的公钥和私钥,生成的文件会自动放在/root/.ssh 目录下
然后把公钥发往远程机器,比如 hadoop01 向 hadoop02 发送
执行:ssh-copy-id root@hadoop01
此时,hadoop02 节点就是把收到的 hadoop 秘钥保存在
/root/.ssh/authorized_keys 这个文件里,这个文件相当于访问白名单,凡是
在此白明白存储的秘钥对应的机器,登录时都是免密码登录的。
当 hadoop01 再次通过 ssh 远程登录 hadoop02 时,发现不需要输入密码了。
在 hadoop02 节点执行上述上述步骤,让 hadoop02 节点连接 hadoop01 免密码登
录
4.配置自己节点登录的免密码登录
如 果 是 单 机 的 伪 分 布 式 环 境 , 节 点 需 要 登 录 自 己 节 点 , 即 hadoop01 要 登 录
hadoop01

剩余38页未读,继续阅读
2011-11-18 上传
2019-04-14 上传
2020-08-25 上传
2018-06-11 上传
点击了解资源详情
点击了解资源详情
2024-11-29 上传

迷茫的蚊子
- 粉丝: 1
- 资源: 9
 我的内容管理
展开
我的内容管理
展开







最新资源
- C语言数组操作:高度检查器编程实践
- 基于Swift开发的嘉定单车LBS iOS应用项目解析
- 钗头凤声乐表演的二度创作分析报告
- 分布式数据库特训营全套教程资料
- JavaScript开发者Robert Bindar的博客平台
- MATLAB投影寻踪代码教程及文件解压缩指南
- HTML5拖放实现的RPSLS游戏教程
- HT://Dig引擎接口,Ampoliros开源模块应用
- 全面探测服务器性能与PHP环境的iprober PHP探针v0.024
- 新版提醒应用v2:基于MongoDB的数据存储
- 《我的世界》东方大陆1.12.2材质包深度体验
- Hypercore Promisifier: JavaScript中的回调转换为Promise包装器
- 探索开源项目Artifice:Slyme脚本与技巧游戏
- Matlab机器人学习代码解析与笔记分享
- 查尔默斯大学计算物理作业HP2解析
- GitHub问题管理新工具:GIRA-crx插件介绍
