Hadoop3.X大数据平台中的分布式文件系统解析
需积分: 5 67 浏览量
更新于2024-07-09
收藏 2.41MB PDF 举报
"本章主要介绍了Hadoop3.X中的分布式文件系统HDFS,涵盖了HDFS的基本概念、设计目标、高可用架构以及如何通过Shell和Java进行管理。内容包括HDFS的架构,如数据块、名称节点(包括活跃名称节点和备用名称节点)、FsImage和EditLog等关键组件的工作机制。"
在Hadoop3.X的大数据平台中,分布式文件系统HDFS(Hadoop Distributed File System)是核心组件之一,用于存储海量数据。HDFS的设计目标主要是为了处理大规模的数据集,提供高容错性和高吞吐量的数据访问。
3.1 HDFS概述
HDFS的核心思想是将大文件分割成固定大小的数据块,通常默认为128MB,这有利于数据的并行处理和提高存储效率。这种设计适应了大规模数据存储的需求,并简化了系统设计。数据块还会被复制多份,以确保数据的可靠性,支持快速的数据备份和恢复。
3.1.1 HDFS架构
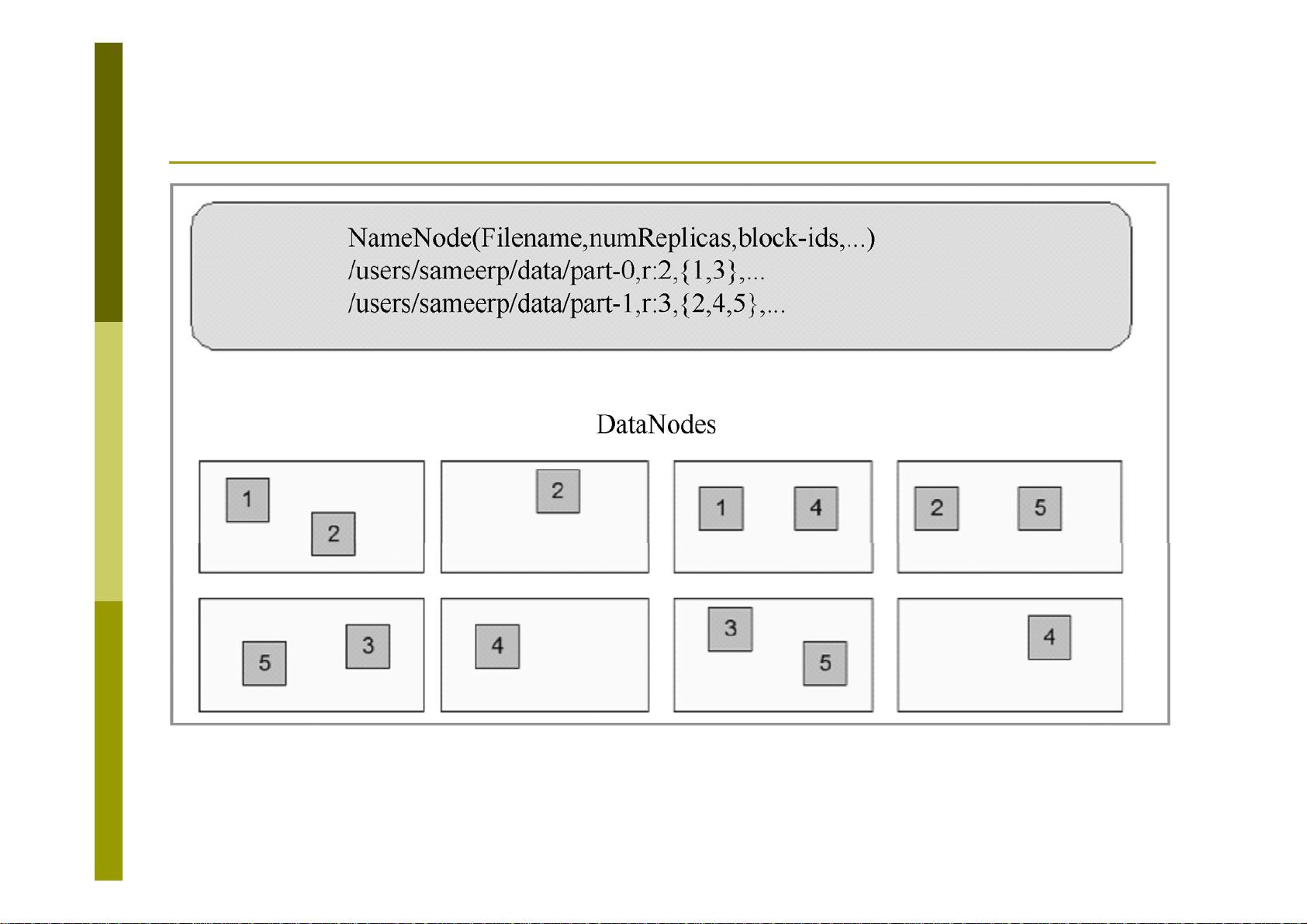
HDFS由两个主要组件构成:名称节点(NameNode)和数据节点(DataNode)。名称节点是整个HDFS的元数据管理中心,它维护着文件系统的命名空间,包括文件路径、文件的元数据(如权限、时间戳等),以及文件数据块在数据节点上的位置信息。名称节点分为两类:活跃名称节点和备用名称节点。活跃名称节点负责处理客户端请求,而备用名称节点则处于热备状态,与活跃名称节点保持同步,一旦活跃名称节点故障,可以无缝接管服务,避免系统单点故障。
名称节点的内部数据结构包括FsImage和EditLog。FsImage文件存储了HDFS的初始状态,包括所有文件和目录的元数据。EditLog则是记录所有修改操作的日志,如文件的创建、删除和重命名。当系统运行时,所有的更改都会首先写入EditLog,然后在合适的时间点合并到FsImage中。
3.1.1 HDFS架构 - 备用名称节点
备用名称节点通过定期接收和合并活跃名称节点的EditLog,更新自身的FsImage,使得两者状态保持一致。在活跃名称节点出现问题时,备用名称节点能够迅速转变为活跃状态,保证服务不间断。
HDFS的Shell管理允许用户通过命令行接口执行文件系统操作,如创建、删除文件或目录,读取文件内容等。同时,HDFS也提供了Java API,让开发者能直接在应用程序中进行文件操作,方便集成到各种大数据处理框架中,如MapReduce。
HDFS作为Hadoop的核心组件,通过其独特的分布式架构和高可用性设计,为大数据处理提供了稳定且高效的存储基础。理解HDFS的工作原理和管理方式对于掌握Hadoop大数据平台的应用至关重要。

Hadoop 3.X 大数据平台技术与应用开发
3.1.4 HDFS架构的优劣性
HDFS具有下列优点
高容错性:数据自动保存多个副本,副本丢失后,可以自动恢复
适合大量数据的批量处理:Hadoop架构以数据为中心,在进行
计算时并不移动数据,而是将计算分配给数据,适合GB级、TB
级甚至PB级的数据量,数据文件的数量可以达到百万级别,系统
中节点数可以达到上万的规模。
简单的数据模型:HDFS采用“一次写入,多次读取”的简单文
件模型,文件一旦完成写入,关闭后就无法再次写入,只能被读
取。
构建成本低、安全可靠:HDFS采用成千上万的廉价服务器存储
数据,极大降低了Hadoop集群的架构成本。



剩余101页未读,继续阅读
2021-07-14 上传
2020-05-30 上传
2023-12-14 上传
2023-06-28 上传
2023-03-25 上传
2023-07-02 上传
2023-05-23 上传
2023-03-17 上传

oracle_teacher
- 粉丝: 1
- 资源: 11
 我的内容管理
展开
我的内容管理
展开







最新资源
- Hadoop生态系统与MapReduce详解
- MDS系列三相整流桥模块技术规格与特性
- MFC编程:指针与句柄获取全面解析
- LM06:多模4G高速数据模块,支持GSM至TD-LTE
- 使用Gradle与Nexus构建私有仓库
- JAVA编程规范指南:命名规则与文件样式
- EMC VNX5500 存储系统日常维护指南
- 大数据驱动的互联网用户体验深度管理策略
- 改进型Booth算法:32位浮点阵列乘法器的高速设计与算法比较
- H3CNE网络认证重点知识整理
- Linux环境下MongoDB的详细安装教程
- 压缩文法的等价变换与多余规则删除
- BRMS入门指南:JBOSS安装与基础操作详解
- Win7环境下Android开发环境配置全攻略
- SHT10 C语言程序与LCD1602显示实例及精度校准
- 反垃圾邮件技术:现状与前景
