SparkStreaming入门:DStream的易用特性与容错设计
需积分: 0 91 浏览量
更新于2024-08-05
收藏 711KB PDF 举报
SparkStreaming篇01介绍了Spark Streaming的基本概念和核心特性,它是Apache Spark的一个模块,专为实时流处理而设计。Spark Streaming主要关注的是对连续、无限的流数据进行批处理分析,这使得它在大数据处理和实时应用中具有重要作用。
首先,Spark Streaming易于使用,其API设计简洁直观,允许开发人员利用Spark高度抽象的原语,如map、reduce、join和window等,对流数据进行复杂的处理。这些原语与Spark基于RDD(弹性分布式数据集)的模型类似,只是将数据转换为DStream(离散化流),即随时间流动的一系列RDD,使得数据处理更加灵活。
其次,Spark Streaming强调容错性。由于流数据处理中可能会出现节点故障或数据丢失的情况,Spark Streaming提供了容错机制,确保即使在出现问题时,也能从失败中恢复并继续处理后续数据。这种容错性有助于保证系统的稳定性和可靠性。
再者,Spark Streaming的设计使得它可以无缝地融入Spark的整体框架,与其他Spark组件(如Spark SQL、MLlib等)协同工作,便于开发者构建统一的大数据处理解决方案。
然而,在早期版本的Spark Streaming(1.5之前),数据接收速率的控制是通过静态配置参数“spark.streaming.receiver.maxRate”实现的,这种方法虽然能够防止内存溢出,但也可能导致资源利用率不均衡。为了解决这个问题,Spark Streaming 1.5及以后版本引入了背压机制(SparkStreamingBackpressure)。背压机制可以根据JobScheduler提供的执行信息动态调整接收器的数据接收速率,更好地平衡数据流量与处理能力,避免了资源浪费。
对于实际操作,例如使用netcat工具向9999端口持续发送数据,然后通过Spark Streaming读取并统计不同单词的出现次数,开发人员需要在Maven项目中添加相应的依赖,如`org.apache.spark:spark-streaming_2.11`。代码实现中会涉及到DStream的创建、数据的读取、文本解析以及单词计数等步骤,展示了如何将这些理论知识应用于实际场景。
总结来说,Spark Streaming是一个强大的流处理工具,它通过易用的API、容错设计和与Spark体系的紧密集成,为实时数据分析提供了高效且可扩展的解决方案。理解并掌握DStream的基本操作和背压机制,将有助于开发人员在实时流处理项目中发挥Spark Streaming的最大潜力。
人的大脑倾向于做更容易的事情
SparkStreaming之Dstream入门
SparkStreaming概述
Spark Streaming用于流式数据的处理。Spark Streaming支持的数据输入源很多,例如:
Kafka、Flume、Twitter、ZeroMQ和简单的TCP套接字等等。数据输入后可以用Spark的高度抽
象原语如:map、reduce、join、window等进行运算。而结果也能保存在很多地方,如HDFS,
数据库等。
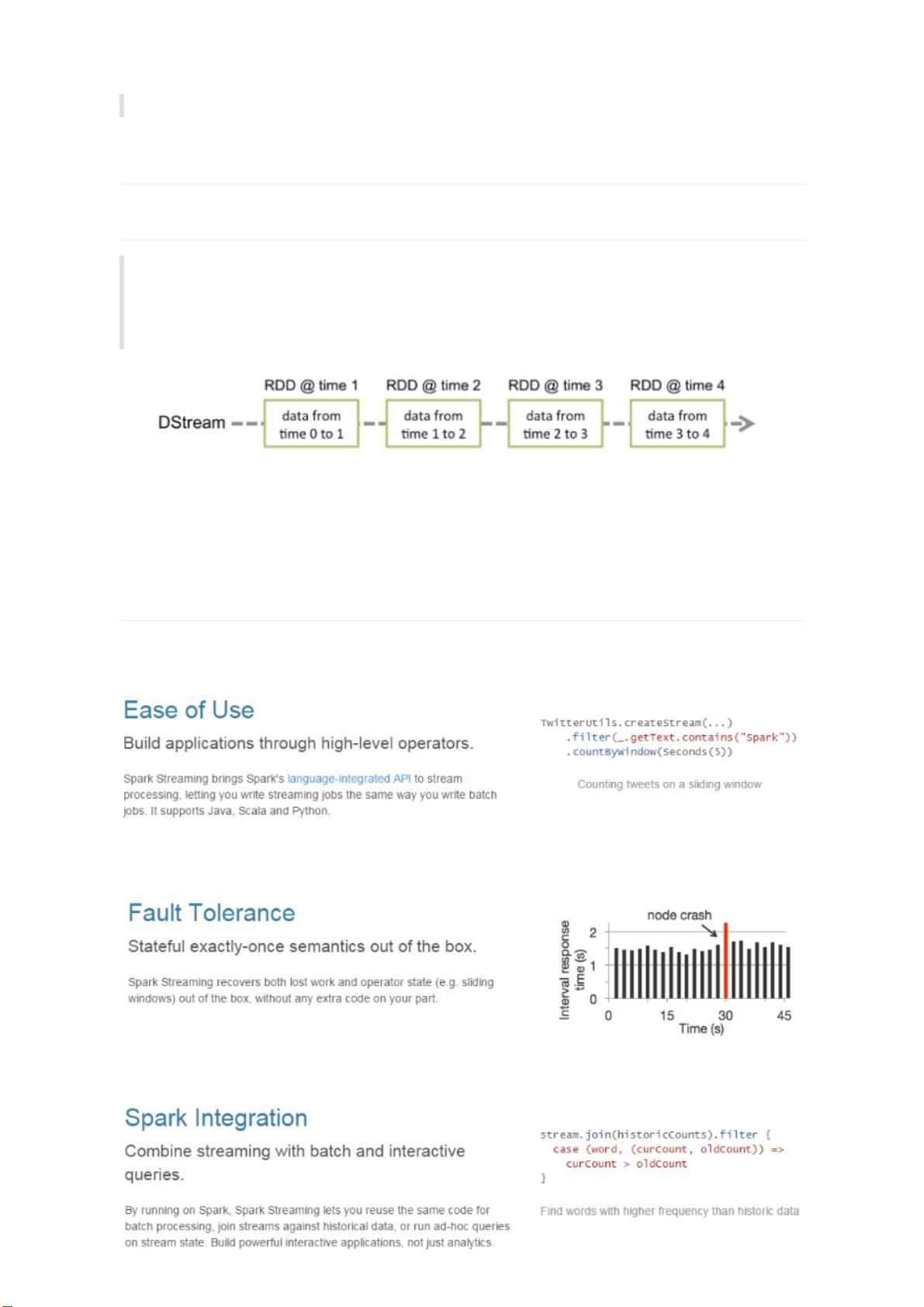
和Spark基于RDD的概念很相似,Spark Streaming使用离散化流(discretized stream)作为抽象表
示,叫作DStream。DStream 是随时间推移而收到的数据的序列。在内部,每个时间区间收到的数据
都作为 RDD 存在,而DStream是由这些RDD所组成的序列(因此得名“离散化”)。
SparkStreaming特点
1.易用
2.容错
3.易整合到Spark体系
下载后可阅读完整内容,剩余3页未读,立即下载
2020-06-22 上传
2017-06-02 上传
点击了解资源详情
点击了解资源详情
2021-01-27 上传
2021-01-27 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情

人亲卓玛
- 粉丝: 32
- 资源: 329
 我的内容管理
展开
我的内容管理
展开







最新资源
- 开源通讯录备份系统项目,易于复刻与扩展
- 探索NX二次开发:UF_DRF_ask_id_symbol_geometry函数详解
- Vuex使用教程:详细资料包解析与实践
- 汉印A300蓝牙打印机安卓App开发教程与资源
- kkFileView 4.4.0-beta版:Windows下的解压缩文件预览器
- ChatGPT对战Bard:一场AI的深度测评与比较
- 稳定版MySQL连接Java的驱动包MySQL Connector/J 5.1.38发布
- Zabbix监控系统离线安装包下载指南
- JavaScript Promise代码解析与应用
- 基于JAVA和SQL的离散数学题库管理系统开发与应用
- 竞赛项目申报系统:SpringBoot与Vue.js结合毕业设计
- JAVA+SQL打造离散数学题库管理系统:源代码与文档全览
- C#代码实现装箱与转换的详细解析
- 利用ChatGPT深入了解行业的快速方法论
- C语言链表操作实战解析与代码示例
- 大学生选修选课系统设计与实现:源码及数据库架构
