堆数据结构详解与实现
需积分: 9 188 浏览量
更新于2024-07-09
收藏 992KB PDF 举报
"这篇文档详细介绍了堆数据结构的概念、特性以及相关的API设计和实现方法,主要关注于如何在数组中构建和操作堆。"
堆是一种特殊的数据结构,它基于完全二叉树的概念,通常用数组来实现。在堆中,有两个主要的类型:大顶堆和小顶堆。大顶堆的每个节点都大于或等于它的子节点,而小顶堆则相反,每个节点都小于或等于它的子节点。这种性质使得堆成为实现优先队列的理想选择,因为可以快速访问或删除最大(或最小)元素。
文档中提到了一个名为`Heap`的类,该类用于表示堆数据结构。这个类有以下关键组成部分:
1. 构造方法`Heap(int capacity)`:创建一个具有指定容量`capacity`的堆对象。
2. 成员方法:
- `private boolean less(int i, int j)`:比较索引`i`和`j`处的元素大小。
- `private void exch(int i, int j)`:交换索引`i`和`j`处的元素值。
- `public T delMax()`:删除并返回堆中的最大元素。
- `public void insert(T t)`:向堆中插入一个元素`t`。
- `private void swim(int k)`:使用上浮算法确保索引`k`处的元素在堆中处于正确位置。
- `private void sink(int k)`:使用下沉算法确保索引`k`处的元素在堆中处于正确位置。
3. 成员变量:
- `private T[] items`:存储堆中元素的数组。
- `private int N`:记录堆中元素的数量。
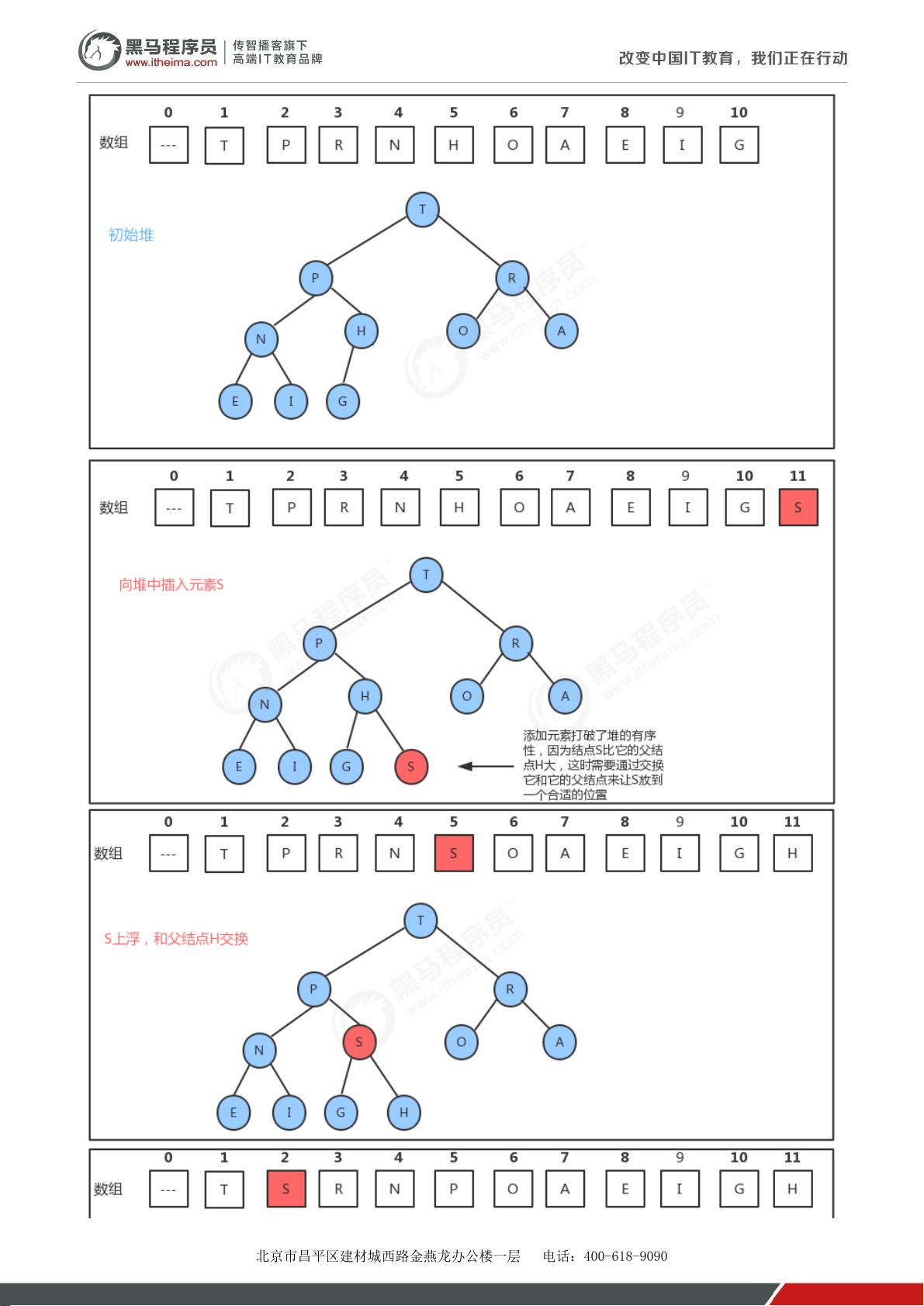
堆的操作主要是通过上浮和下沉算法来保持堆的性质。上浮算法(`swim`)用于新插入的元素或调整后的元素,确保其满足堆的条件,即父亲节点大于等于子节点。下沉算法(`sink`)则用于在删除最大元素后,将新的根节点下移至正确位置,以保持堆的性质。
在堆中插入元素时,由于数组是堆的基础,只能从索引0开始按顺序存放。当需要插入一个新元素时,通常会将其添加到数组末尾,然后通过上浮算法调整使其处于正确位置。删除最大元素时,通常会将最后一个元素替换为当前最大元素,然后通过下沉算法调整以保持堆的性质,同时将数组的最后一个元素设为空。
堆的API设计包括了插入和删除操作,这些操作都需要考虑到数组的特性和堆的性质,以保证数据结构的正确性。实现这些操作时,还需要考虑效率,例如插入操作通常的时间复杂度为O(log n),删除操作也是类似。
总结起来,堆是一种高效的数据结构,常用于优先级队列,它的主要操作包括插入元素和删除最大元素,通过特定的算法(上浮和下沉)来维护堆的性质。理解堆的原理和实现对于优化算法和解决某些问题(如排序、优先级调度等)至关重要。
北京市昌平区建材城西路金燕龙办公楼一层 电话:400-618-9090
剩余18页未读,继续阅读
2022-07-03 上传
2021-02-08 上传
2022-06-29 上传
2021-08-24 上传
2020-10-10 上传
2021-12-30 上传
2008-10-30 上传
2024-01-25 上传
2021-07-16 上传

‖墨染年华℡
- 粉丝: 0
- 资源: 2
 我的内容管理
展开
我的内容管理
展开







最新资源
- Raspberry Pi OpenCL驱动程序安装与QEMU仿真指南
- Apache RocketMQ Go客户端:全面支持与消息处理功能
- WStage平台:无线传感器网络阶段数据交互技术
- 基于Java SpringBoot和微信小程序的ssm智能仓储系统开发
- CorrectMe项目:自动更正与建议API的开发与应用
- IdeaBiz请求处理程序JAVA:自动化API调用与令牌管理
- 墨西哥面包店研讨会:介绍关键业绩指标(KPI)与评估标准
- 2014年Android音乐播放器源码学习分享
- CleverRecyclerView扩展库:滑动效果与特性增强
- 利用Python和SURF特征识别斑点猫图像
- Wurpr开源PHP MySQL包装器:安全易用且高效
- Scratch少儿编程:Kanon妹系闹钟音效素材包
- 食品分享社交应用的开发教程与功能介绍
- Cookies by lfj.io: 浏览数据智能管理与同步工具
- 掌握SSH框架与SpringMVC Hibernate集成教程
- C语言实现FFT算法及互相关性能优化指南
