Scrapy爬虫框架详解:构建大数据挖掘的基石
版权申诉
124 浏览量
更新于2024-07-03
收藏 2.54MB PPT 举报
"本资源为关于Scrapy爬虫框架的讲解材料,由大数据挖掘专家制作,日期为2024年5月22日。内容涵盖了Scrapy的基本组成、核心组件的功能及其在大数据挖掘中的应用。"
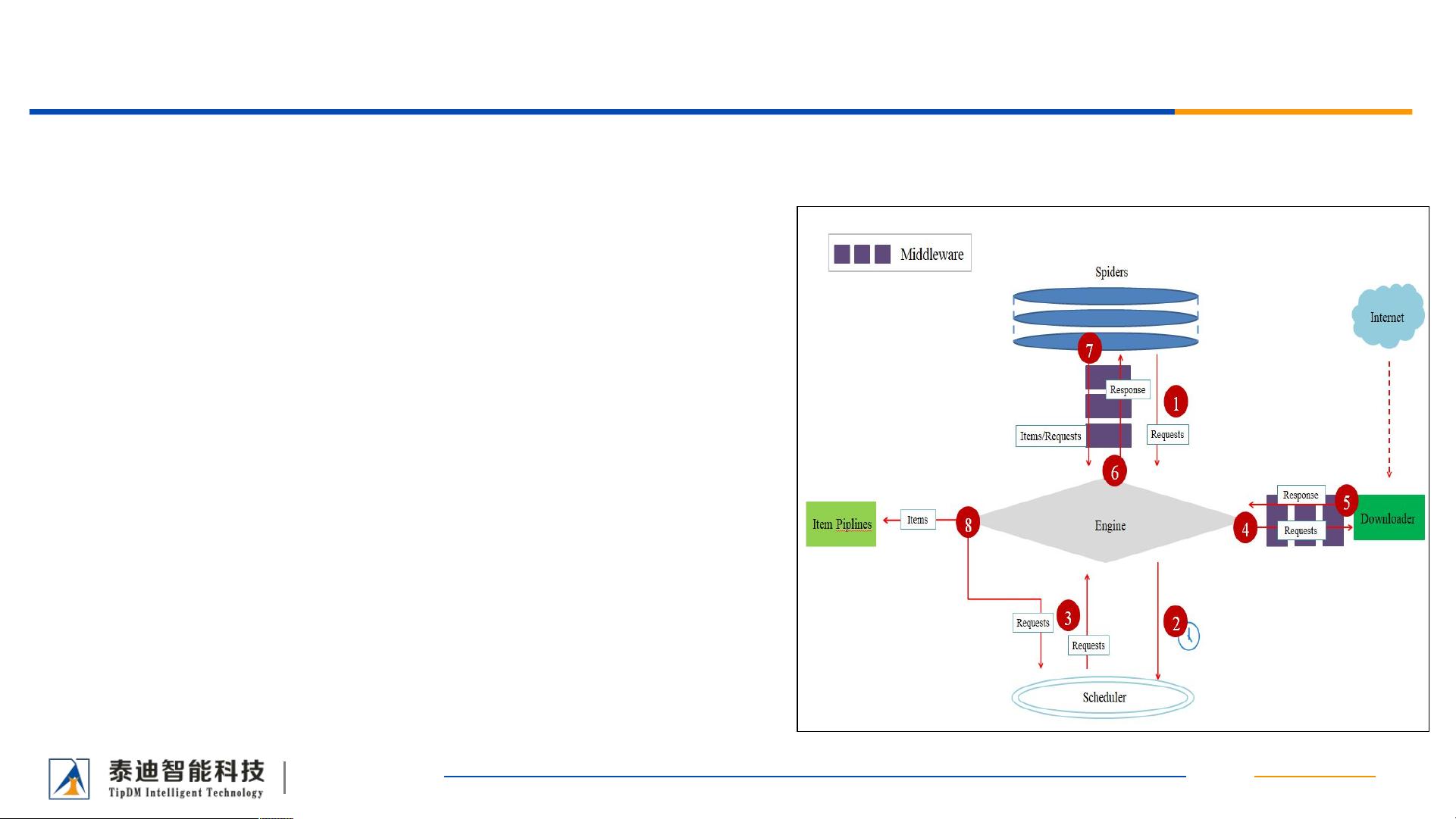
Scrapy是一个强大的Python爬虫框架,专为快速开发专业级网络爬虫而设计。它不是单一的功能函数库,而是由多个组件构成的框架,包括引擎(Engine)、调度器(Scheduler)、下载器(Downloader)、Spiders、ItemPipelines以及两类中间件(下载器中间件和Spider中间件)。这个框架为开发者提供了灵活的接口,便于构建定制化的网络爬虫解决方案。
1. **引擎(Engine)**:作为Scrapy的核心,引擎控制着数据流在各个组件间流动,并根据特定条件触发相应事件。它是爬虫的调度中心,负责协调整个爬取过程。
2. **调度器(Scheduler)**:调度器接收引擎发送的请求(Request),并将其放入队列中,确保没有重复的URL。如果需要,可以通过配置实现对POST请求URL的去重。
3. **下载器(Downloader)**:下载器是获取网页内容的工具,它负责从网络上抓取网页并传递给引擎和Spider。下载器不仅下载网页,还处理可能的重定向、超时等网络问题。
4. **Spiders**:Spider是用户编写的类,用于解析下载器返回的响应(Response),从中提取Items和新的URL。每个Spider可专注于一个或多个特定网站的爬取,实现针对性的数据提取。
5. **ItemPipelines**:ItemPipelines负责处理Spider提取出的Items。它们通常进行数据清洗、验证,并将数据持久化到数据库或文件系统中。Pipeline的执行顺序是预定义的,确保数据经过一系列处理流程。
6. **下载器中间件(DownloaderMiddlewares)**:下载器中间件位于引擎和下载器之间,提供了一种扩展Scrapy功能的方式。它们可以修改或拦截下载器传递给引擎的响应,添加自定义的预处理逻辑,比如处理反爬虫策略、代理设置等。
7. **Spider中间件(SpiderMiddlewares)**:Spider中间件位于引擎和Spider之间,处理Spider生成的请求(Request)和响应(Response)。它们可以用来修改Spider的输入或输出,例如过滤掉无效的URL,或者处理爬取过程中遇到的异常。
Scrapy通过这些组件的协同工作,使得大数据挖掘变得更加高效和便捷。在处理大规模数据时,Scrapy的灵活性和可扩展性使其成为理想的工具,帮助开发者快速构建复杂的网络爬虫项目,挖掘有价值的信息,从而驱动未来的决策和创新。
7
大数据挖掘专家
中间件是一组在引擎及 之间的特定钩
子( ! ),主要功能是处理 的输
入(响应)和输出( 及请求)。 中间件
提供了一个简便的机制,通过插入自定义代码来扩展
功能。各组件之间的数据流向如图所示。
了解 Scrapy 爬虫框架
7.Spider 中间件( Spider Middlewares )

剩余37页未读,继续阅读
1480 浏览量
443 浏览量
152 浏览量
640 浏览量
659 浏览量
2473 浏览量
2024-06-20 上传
2024-06-20 上传
651 浏览量

智慧安全方案
- 粉丝: 3844
- 资源: 59万+
 我的内容管理
展开
我的内容管理
展开







