STATA面板数据模型操作详解
版权申诉
36 浏览量
更新于2024-07-10
收藏 317KB DOC 举报
"STATA面板大数据模型操作命令要点"
在STATA中,处理面板数据模型是一种常见的统计分析任务,尤其在社会科学和经济学研究中。面板数据结合了时间序列和横截面数据,提供了丰富的信息来分析变量之间的关系。本文件主要介绍了如何在STATA中进行静态面板数据的处理,包括固定效应模型和随机效应模型的操作。
首先,面板数据的准备工作至关重要。使用`tsset code year`命令设置时间变量,表明数据是面板形式。`xtdes`用于查看面板数据的结构,确保数据正确无误。在进行模型估计之前,通常需要对数据进行描述性统计分析,如`summarize`命令,以了解各变量的基本特征。
接着,我们关注模型的构建。固定效应模型用于处理个体间的异质性,而随机效应模型则考虑个体效应的随机性。在STATA中,`xtreg`命令用于估计这些模型。例如,`xtreg y x1 x2, fe`会估计一个包含固定效应的线性模型,其中`y`是因变量,`x1`和`x2`是自变量。
为了构建固定效应模型,我们需要生成滞后变量(`gen lag_y = L.y`)、超前变量(`gen F_y = F.y`)或差分变量(如一阶差分`gen D_y = D.y`)。这些变量可以帮助捕捉时间序列中的动态关系。
在模型选择阶段,有几个重要的检验方法。首先,使用`xtreg y x1 x2, fe`并查看F统计量,可以检验个体效应是否显著,从而判断是否应该选择固定效应模型。如果F统计量的p值极小,那么固定效应模型相对于普通最小二乘法(OLS)更优。
其次,用`quixtreg y x1 x2, re`和`xttest0`组合来检验时间效应。LM统计量的p值若小于显著性水平,说明随机效应显著,随机效应模型可能更适合。然而,这并不能直接决定是固定效应还是随机效应模型更好。
Hausman检验用于确定固定效应模型和随机效应模型的优劣。首先,分别用`xtreg`命令估计固定效应模型(存储为`fe`)和随机效应模型(存储为`re`)。然后,执行`hausman fe re`进行Hausman检验。如果Hausman检验的p值很小,拒绝原假设,即随机效应模型不优于固定效应模型,那么应选择固定效应模型。
以上就是STATA中处理面板数据模型的关键步骤,包括模型的设定、变量处理和模型选择检验。理解并熟练掌握这些命令对于进行有效的面板数据分析至关重要。
word
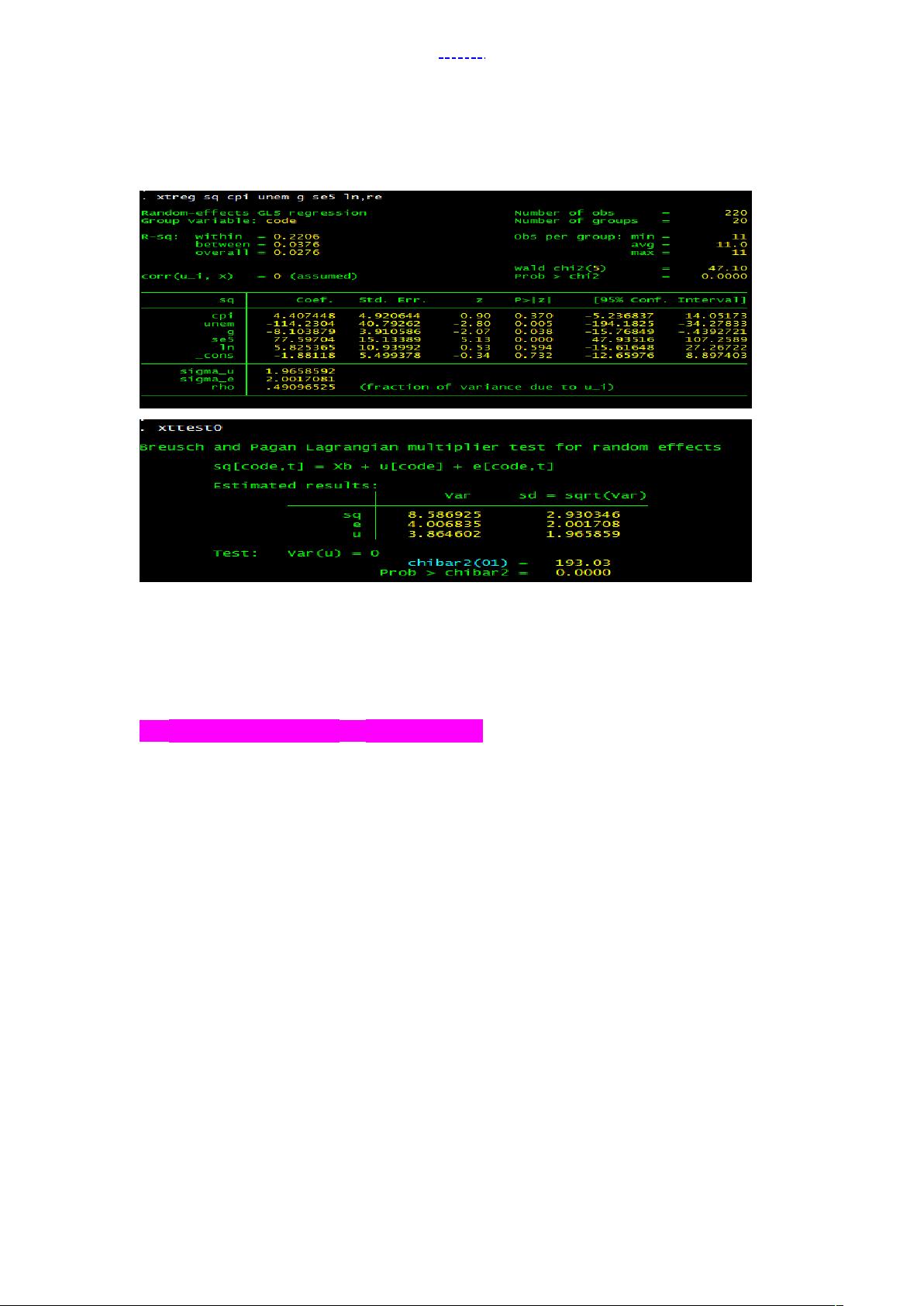
●qui xtreg sq cpi unem g se5 ln,re (加上“qui〞之后第一幅图将不会呈现)
xttest0
可以看出,LM 检验得到的 P 值为 0.0000,明确随机效应非常显著。可见,
随机效应模型也优于混合 OLS 模型。
●3、检验固定效应模型 or 随机效应模型 〔检验方法:Hausman 检验〕
原假设:使用随机效应模型〔个体效应与解释变量无关〕
通过上面分析,可以发现当模型参加了个体效应的时候,将显著优于截距
项为常数假设条件下的混合 OLS 模型。但是无法明确区分 FE or RE 的优劣,
这需要进展接下来的检验,如下:
Step1:估计固定效应模型,存储估计结果
Step2:估计随机效应模型,存储估计结果
Step3:进展 Hausman 检验
●qui xtreg sq cpi unem g se5 ln,fe
est store fe
qui xtreg sq cpi unem g se5 ln,re
est store re
hausman fe (或者更优的是 hausman fe,sigmamore/ sigmaless)
3 / 15
剩余14页未读,继续阅读
点击了解资源详情
点击了解资源详情
点击了解资源详情
2022-12-18 上传
2023-03-06 上传

「已注销」
- 粉丝: 0
- 资源: 5万+
 我的内容管理
展开
我的内容管理
展开







最新资源
- 51单片机入门教程(PDF文件格式).pdf
- 2009年软件设计师考试大纲<软考>
- 2009年5月软件设计师考试题(上午题)
- linux经典图书之kernel篇
- linux经典图书之drivers篇
- springGuide
- 开放式机房互动交流系统(数据库课程设计)
- CSDN 软件开发2.0技术会议:iPhone平台之(下):OpenGL ES的三维图形开发揭密
- 让你的软件飞起来---------------------
- CSDN 软件开发2.0技术会议:iPhone平台之(上):应用开发和实例解析
- 最小生成树 数据结构 C语言编程
- Linux初级应用指南
- Linux 菜鸟 过关
- LINUX基础介绍扫盲贴
- Python 基础教程(最新3.0)
- unix常用命令 (包括各种常用命令)
