B树到R树:数据存储与索引优化解析
需积分: 2 155 浏览量
更新于2024-07-09
收藏 2.96MB PDF 举报
"这篇文档是关于数据库索引结构的深入探讨,主要涵盖了B树、B+树、B*树以及R树。它旨在帮助程序员在面试中更好地理解这些数据结构,提升面试竞争力。"
文章详细内容:
在数据库系统中,高效的数据检索是至关重要的,特别是在处理大量数据时。B树、B+树和B*树是为了解决传统二叉查找树在处理大规模数据时效率低下的问题而设计的。这些数据结构特别适用于外部存储,如硬盘,因为它们能够显著减少磁盘I/O操作,从而提高查询速度。
1. B树( Balanced Tree)
B树是一种自平衡的多路搜索树,每个节点可以有多个子节点。它的特点在于所有叶子节点都在同一层,且每个节点都包含键值对,这些键将子节点分成若干部分。B树允许快速查找,插入和删除操作,同时保持较低的树高度。
2. B+树(B Plus Tree)
B+树是B树的变体,进一步优化了B树的设计。在B+树中,所有的数据都存储在叶子节点,非叶子节点只用于索引。这样的设计使得所有的数据路径长度相同,提高了查询效率,尤其适合范围查询,因为可以在叶子节点之间进行线性遍历。
3. B*树(B Star Tree)
B*树是B+树的改进版,它在非根和非叶子节点增加了指向兄弟节点的指针,减少了搜索时的磁盘I/O操作。B*树的分支因子更大,因此在相同的数据集上,B*树的树高通常小于B+树,从而提高了查询速度。
4. R树(R-Tree)
R树是一种多维空间索引结构,特别适用于地理信息系统或数据库中的空间对象,如地图坐标。R树可以处理多维数据,如矩形、圆等,它可以有效地存储和检索分布在多维空间中的数据。
总结,B树系列和R树是数据库和文件系统中广泛使用的索引结构,它们的核心目标是减少磁盘I/O,通过增加每个节点的子节点数来降低树的高度,从而提高检索效率。对于程序员来说,深入理解这些数据结构对于设计高效的数据库系统和解决面试中的问题至关重要。
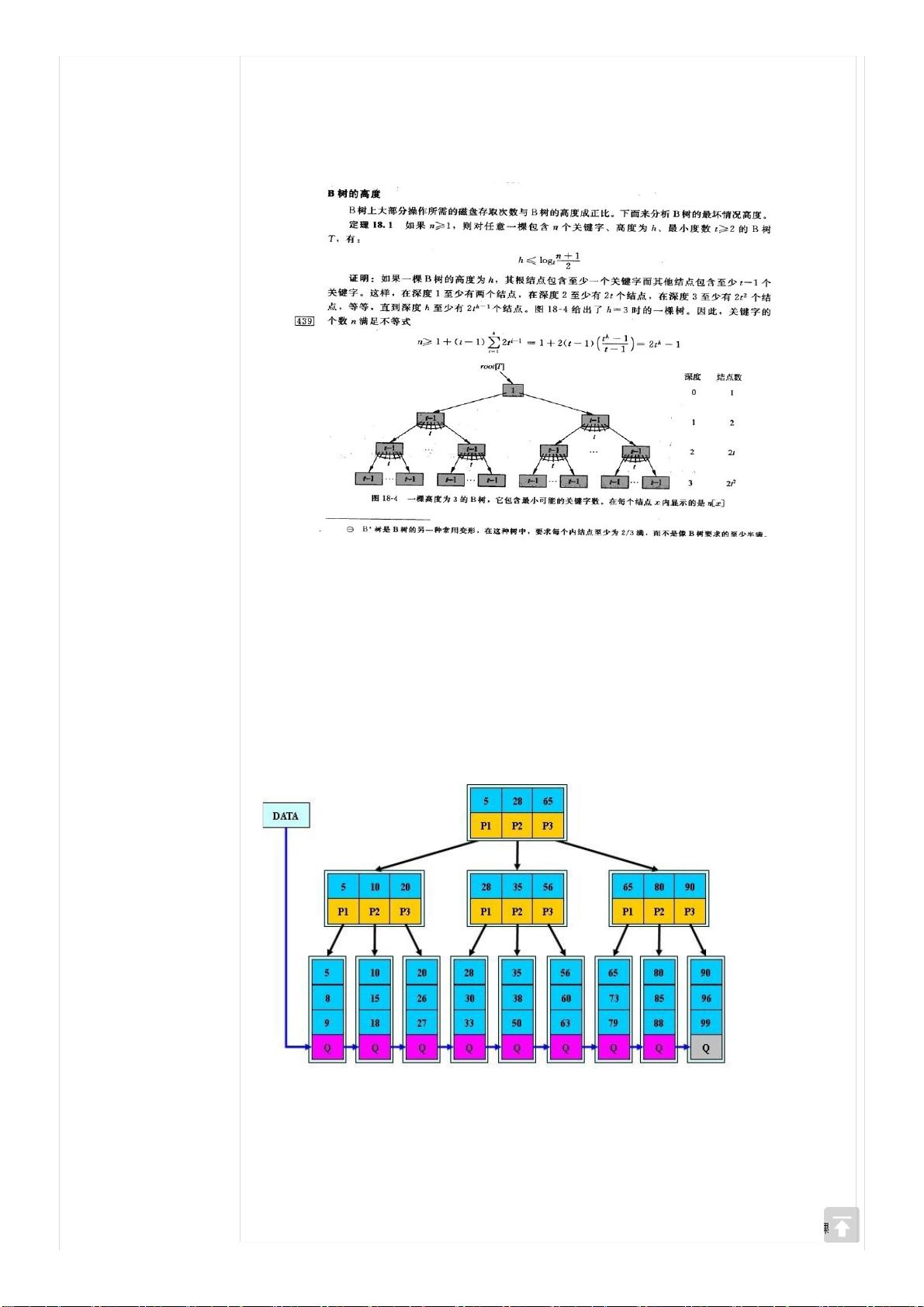
即: I≤ log┌m/2┐((N+1)/2 )+2
所以,当B树包含N个关键关键字时,B树的最大高度为l-1(因为计算B树高度时,叶结点所在层不计算在内)
即:log┌m/2┐((N+1)/2 )+1。
这个B树的高度公式从侧面显示了B树的查找效率是相当高的。
有读者反馈,说上面的B树的高度计算公式与算法导论一书上的不同,而后我特意翻看了算法导论第18章关于B树的高度一节的
内容,如下图所示:
在上图中书上所举的例子中,也许,根据我们大多数人的理解,它的高度应该是4,而书上却说的是“一棵高度为3的B树”。我
想,此时,你也就明白了,算法导论一书上的高度的定义是从“0”开始计数的,而我们中国人的习惯是树的高度是从“1”开始计
数的。特此说明。July、二零一二年九月二十七日。
4.B
+
-tree
B
+
-tree:是应文件系统所需而产生的一种B-tree的变形树。
一棵m阶的B+树和m阶的B树的差异在于:
1.有n棵子树的结点中含有n个关键字; (而B 树是n棵子树有n-1个关键字)
2.所有的叶子结点中包含了全部关键字的信息,及指向含有这些关键字记录的指针,且叶子结点本身依关键字
的大小自小而大的顺序链接。 (而B 树的叶子节点并没有包括全部需要查找的信息)
3.所有的非终端结点可以看成是索引部分,结点中仅含有其子树根结点中最大(或最小)关键字。 (而B 树的
非终节点也包含需要查找的有效信息)
a) 为什么说B
+
-tree比B 树更适合实际应用中操作系统的文件索引和数据库索引?
1)
B
+
-tree的磁盘读写代价更低
B
+
-tree的内部结点并没有指向关键字具体信息的指针。因此其内部结点相对B 树更小。如果把所有同一内部
结点的关键字存放在同一盘块中,那么盘块所能容纳的关键字数量也越多。一次性读入内存中的需要查找的关键
字也就越多。相对来说IO读写次数也就降低了。
举个例子,假设磁盘中的一个盘块容纳16bytes,而一个关键字2bytes,一个关键字具体信息指针2bytes。一棵
从B树、B+树、B
*
树谈到R 树 - 结构之法 算法之道 - 博客频道 - C... http://blog.csdn.net/v_JULY_v/article/details/6530142
6 of 31 10/27/2012 8:08 P
M
剩余30页未读,继续阅读
2009-04-04 上传
152 浏览量
2019-09-05 上传
2021-10-27 上传
2021-09-08 上传
282 浏览量
912 浏览量
2021-10-16 上传
点击了解资源详情

Jeffnju
- 粉丝: 0
- 资源: 18
 我的内容管理
展开
我的内容管理
展开







最新资源
- Fisher Iris Setosa数据的主成分分析及可视化- Matlab实现
- 深入理解JavaScript类与面向对象编程
- Argspect-0.0.1版本Python包发布与使用说明
- OpenNetAdmin v09.07.15 PHP项目源码下载
- 掌握Node.js: 构建高性能Web服务器与应用程序
- Matlab矢量绘图工具:polarG函数使用详解
- 实现Vue.js中PDF文件的签名显示功能
- 开源项目PSPSolver:资源约束调度问题求解器库
- 探索vwru系统:大众的虚拟现实招聘平台
- 深入理解cJSON:案例与源文件解析
- 多边形扩展算法在MATLAB中的应用与实现
- 用React类组件创建迷你待办事项列表指南
- Python库setuptools-58.5.3助力高效开发
- fmfiles工具:在MATLAB中查找丢失文件并列出错误
- 老枪二级域名系统PHP源码简易版发布
- 探索DOSGUI开源库:C/C++图形界面开发新篇章
