MindFormers套件深度解析:大模型的文本生成与分布式推理
167 浏览量
更新于2024-06-20
收藏 2.95MB PPTX 举报
"第四期《MindFormers套件之大模型文本生成和分布式在线推理》主要探讨了MindFormers工具包在大模型文本生成和分布式在线推理方面的应用。课程涵盖了LLM(Large Language Model)文本生成的基础概念、增量推理与流式推理的特点、分布式推理与多batch推理的实现,以及ChatWeb功能的演示。"
MindFormers大模型使能套件是一个强大的工具,用于支持大规模语言模型的各类任务,包括文本生成。文本生成是自然语言处理中的一个重要任务,它基于已有的文本输入,通过预测并选择下一个最可能的词汇,生成连续的文本序列。MindFormers套件的实现使得这个过程变得更加高效和便捷。
在LLM文本生成基础概念部分,课程介绍了如何根据已有文本token输入,预测下一个token的概率,并通过概率分布采样确定下一个token值。这个过程会持续进行,直到生成结束符出现。MindFormers提供了一个名为`text_generator.py`的模块,其中的`GeneratorMixin`接口实现了文本生成流程。所有继承此接口的语言模型都可以调用`.generate()`方法来进行文本生成推理。
`.generate()`接口的使用示例可以在MindSpore的MindFormers GitHub仓库中找到。该接口支持多种参数,包括输入的文本tokens列表(可以是单个数据或批量数据)、`GenerationConfig`实例以定制生成行为(默认从模型配置文件读取)、用户自定义的`LogitsProcessorList`以进行更复杂的逻辑处理,以及`BaseStreamer`对象,用于支持流式推理的输出流。此外,`.generate()`接口还接受其他关键字参数,如`do_sample`(用于控制是否采用随机采样策略)和`top_k`(限制采样时考虑的最高k个词汇)等,这些参数可以根据具体需求调整。
在课程中,增量推理/流式推理特性讲解部分可能涉及了如何在处理大量实时数据时,有效地利用模型进行推理。这种推理方式通常适用于需要连续处理新输入数据而无需等待完整序列的情况,可以显著提高效率。
分布式推理/多batch推理则关注如何利用多台设备或多个计算资源同时处理数据,以加快推理速度和提升系统吞吐量。这在处理大型模型时尤为重要,因为它们通常需要大量计算资源,而分布式策略可以帮助分摊计算负担。
最后,ChatWeb功能演示可能展示了如何集成MindFormers套件与交互式聊天应用,让用户能够直接与大模型进行对话,实现智能问答和对话生成。
第四期的课程深入讲解了MindFormers套件在文本生成和分布式推理方面的实用技术,对于希望利用大模型进行高效、灵活的自然语言处理任务的开发者来说,具有很高的学习价值。
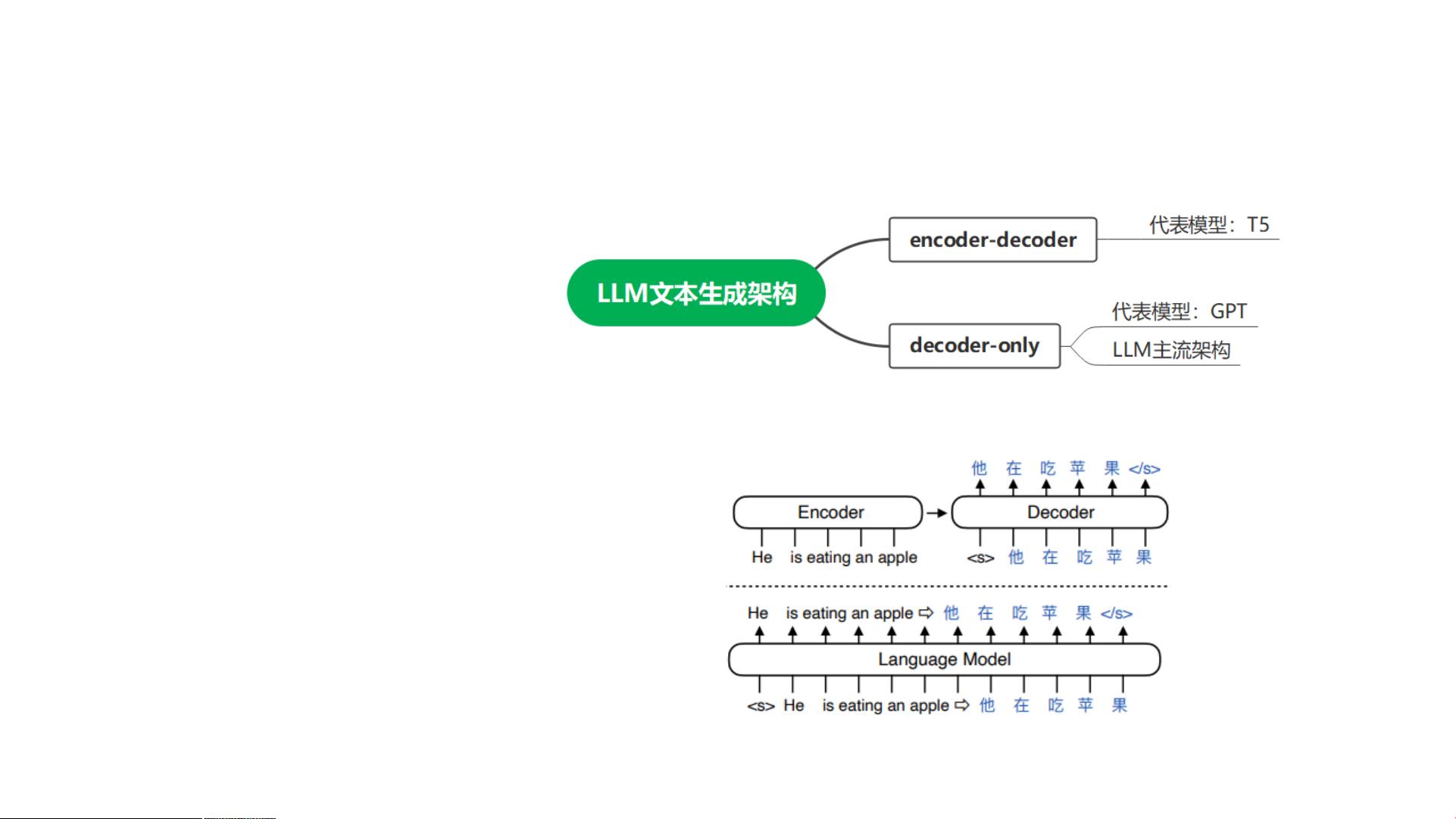
LLM文本生成基础概念
文本生成任务做法:
• 根据已有的文本token输入,预测下一个
token的概率
• 从生成的概率分布中采样决定下一个
token值
• 将生成的token值拼接回原输入token,形
成下一次预测的新输入
• 循环进行模型前向,直至生成结束符
剩余16页未读,继续阅读
275 浏览量
334 浏览量
2024-10-29 上传
233 浏览量
119 浏览量
2024-10-22 上传
2019-08-10 上传
149 浏览量










