决策树算法详解:特征选择与剪枝策略
需积分: 50 141 浏览量
更新于2024-09-07
收藏 578KB PDF 举报
决策树分类算法原理深入解析
决策树是一种基于“分而治之”策略的机器学习算法,特别适用于分类任务,同时也可用于回归分析。其基本流程包括特征选择、决策树生成和剪枝三个步骤。文档介绍了ID3、C4.5和CART这三种经典的决策树算法,它们的主要区别在于特征选择的准则。
在特征选择过程中,信息增益、信息增益率和基尼指数是常用的定量评估标准。信息增益衡量的是某个特征在给定数据集中对分类的纯度提升,即\( g(D,A) = H(D) - H(D|A) \),其中\( H(D) \)是数据集的整体不确定性,\( H(D|A) \)是特征A条件下子集的不确定性。信息增益率考虑了特征的纯度提升相对于特征引入的复杂性,而基尼指数则反映了分类不纯度,用于衡量不确定性。
以贷款申请人的案例为例,假设数据集包含年龄、工作状态、住房状况和信贷情况四个特征。通过不同的特征排序,决策树的结构会有所变化。例如,按照年龄-工作-房子-信贷或工作-房子-年龄-信贷的顺序构建,可能会得出不同复杂度的决策树。通常,选择具有最高信息增益或信息增益率的特征作为分割点,可以生成更简单的树,提高分类效率。
然而,特征选择并非总是直接根据这些指标,还需要结合实际问题的业务理解,以及避免过拟合。剪枝过程是防止过度拟合的重要环节,它通过在决策树生成后删除或合并某些内部节点来简化模型。CART算法采用的是代价复杂度或基尼指数剪枝,以找到最佳平衡点。
决策树分类算法的核心在于合理选择特征和适时剪枝,以实现模型的高效性和可解释性。通过信息增益等量化方法,我们可以优化特征选择过程,最终构建出既能有效分类又具有可理解性的决策树模型。这对于实际问题中的预测和决策支持具有重要意义。
决策树—分类
作者:归去来兮 日期:2018.8.16
核心:特征选择+剪枝。
1 概述
决策树采取了“分而治之”的思想,是一种基本的分类方法,也可以用于回归。包括 3 个
步骤:特征选择、决策树的生成和决策树的修剪。主要有 ID3、C4.5 和 CART 三种算法。
从形式上,决策树就是一棵按照各个特征建立的树形结构,叶节点表示对于的类别,特
征选择的顺序不同,得到的树的形状也不同。我们追求的是模型简单、效果好,直观上也就
是建立的决策树深度越小越好。
[例](来自:李航《统计学习方法》)
下表是一个贷款统计数据(训练数据),数据中贷款申请人有 4 个特征:年龄、是否有
工作、是否有自己的房子、信贷情况。现要通过此数据表建立一个决策树模型,用以对新的
贷款申请人进行分类,来决定是否同意其贷款。
编 号
年 龄
有工作
有自己的房子
信贷情况
是否同意(类别)
1
青年
否
否
一般
否
2
青年
否
否
好
否
3
青年
是
否
好
是
4
青年
是
是
一般
是
5
青年
否
否
一般
否
6
中年
否
否
一般
否
7
中年
否
否
好
否
8
中年
是
是
好
是
9
中年
否
是
非常好
是
10
中年
否
是
非常好
是
11
老年
否
是
非常好
是
12
老年
否
是
好
是
13
老年
是
否
好
是
14
老年
是
否
非常好
是
15
老年
否
否
一般
否
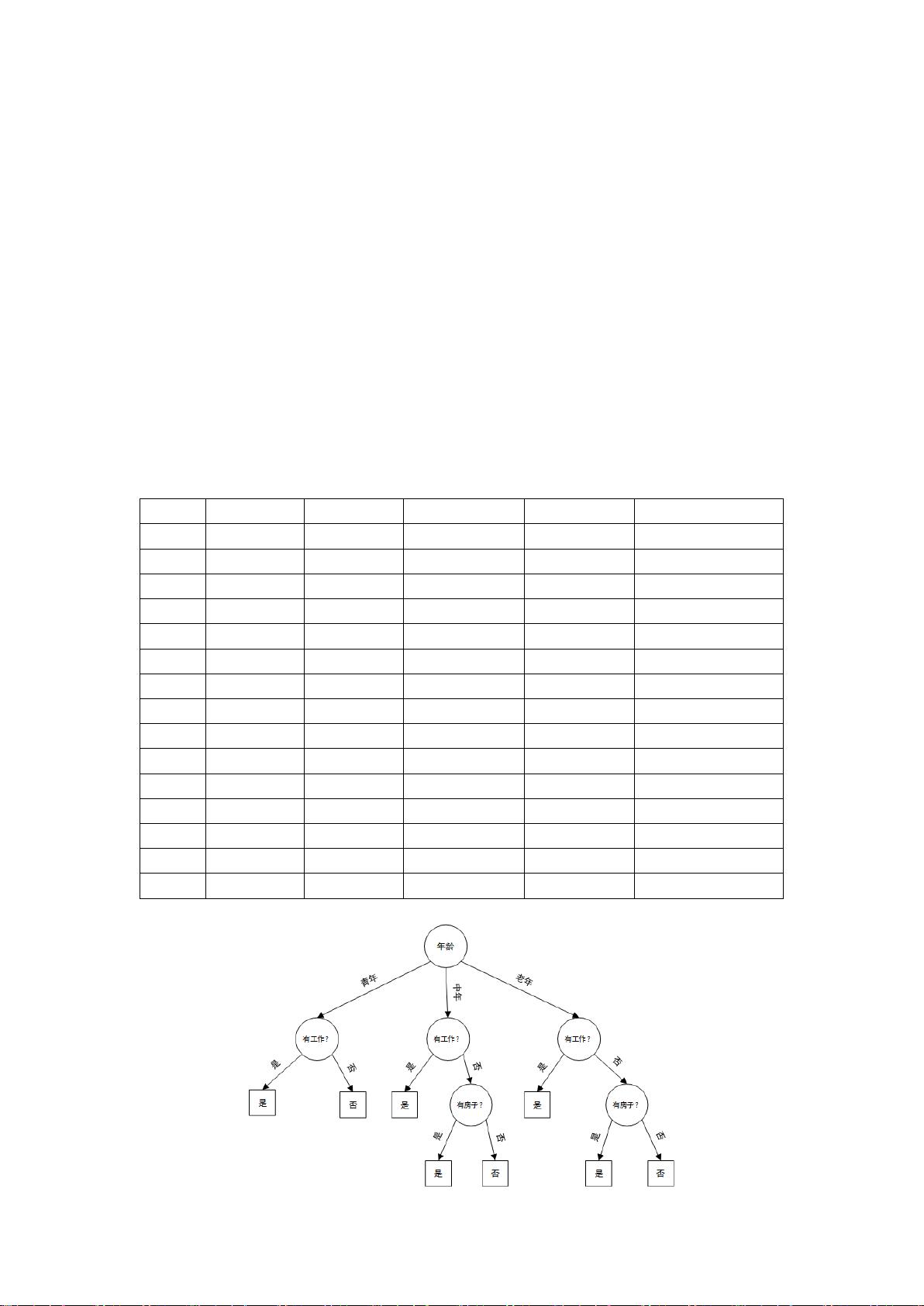
可以这样做:先看年龄(根节点),再看工作-房子-信贷,得到的决策树为
下载后可阅读完整内容,剩余4页未读,立即下载
264 浏览量
2022-07-11 上传
260 浏览量
2535 浏览量
2024-04-25 上传
630 浏览量
点击了解资源详情

禺垣
- 粉丝: 5474
 我的内容管理
展开
我的内容管理
展开







最新资源
- MATLAB实现ART与SART算法在医学CT重建中的应用
- S2SH整合版:快速搭建Struts2+Spring+Hibernate开发环境
- 托奇卡项目团队成员介绍
- 提升外链发布效率的SEO推广神器——搜易达网络推广大师v2.035
- C#打造简易记事本应用详细教程
- 探索虚拟现实地图VR的奥秘
- iOS模拟器屏幕截图新工具
- 深入解析JavaScript在生活应用开发中的运用
- STM32F10x函数库3.5中文版详解与应用
- 猎豹浏览器v6.0.114.13396 r1:安全防护与网购敢赔
- 掌握JS for循环输出的最简洁代码技巧
- Java入门教程:TranslationFileGenerator快速指南
- OpenDDS3.9源码解析及最新文档指南
- JavaScript提示框插件:鼠标滑过显示文章摘要
- MaskRCNN气球数据集:优质图像识别资源
- Laravel日志查看器:实现Apache多站点日志统一管理
