2020年最新Azure数据解决方案实践题库DP-200,193道实战题目
需积分: 9 11 浏览量
更新于2024-07-15
收藏 13.72MB PDF 举报
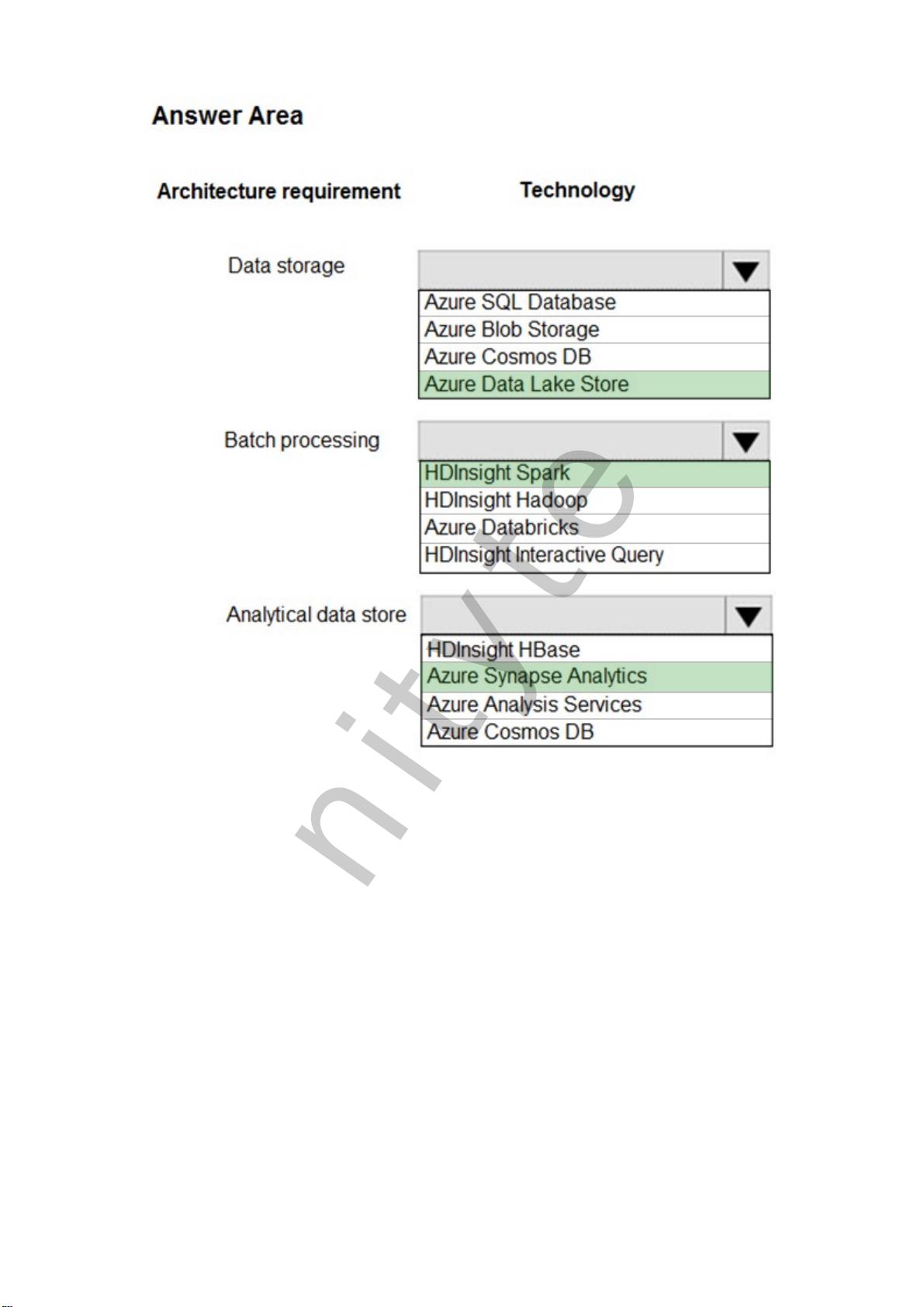
在"DP-200_193Q.pdf"这份最新的练习题集中,涵盖了2020年6月前的最新内容,主要聚焦于Azure Data Solutions的实施,特别是针对Lambda架构的实践。Lambda架构是一种处理大数据分析问题的方法论,它将数据处理分为三个阶段:批处理、实时流处理和交互式查询。
题目中提到,作为数据工程师,你正在Azure上部署一个Lambda架构,并利用开源大数据解决方案收集、处理数据。然而,分析性数据存储性能不佳,目标是实现以下需求:
1. 提供数据仓库功能
2. 减少持续的管理活动
3. 在不到一秒的时间内提供SQL查询响应
为了满足这些要求,你需要创建一个HDInsight集群。在这里,正确答案是D. Apache Spark。Apache Spark是一个强大的分布式计算框架,特别适合实时数据处理和大数据处理任务。它支持SQL查询,并且能够提供快速的响应时间,符合题目的需求。选择Spark集群可以实现数据仓库的功能,同时利用其处理能力来降低管理复杂性,满足实时查询的性能指标。
除此之外,Azure还提供了其他技术来加速实时大数据分析,例如:
- Azure Cosmos DB:这是一个全球分布式的多模型数据库服务,适用于需要高可用性和低延迟的应用。
- Apache Spark for Azure HDInsight:在Azure上运行的Spark,能处理大规模数据分析应用,与Lambda架构中的实时处理阶段相契合。
总结来说,这份练习题集是学习Azure Data Platform 200 (DP-200)的理想资料,特别是对于理解如何在Azure上设计和优化Lambda架构,以及如何选择合适的工具(如Apache Spark)来满足实时分析和数据仓库的需求。通过学习和练习这些题目,考生可以更好地准备考试并提高在实际项目中的技能。

909A545160E581887343EF295A26525D
E. Configure the storage account to log read, write and delete operations for service type queue
Correct Answer: AB
Section: (none)
Explanation
Explanation/Reference:
Explanation:
Storage Logging logs request data in a set of blobs in a blob container named $logs in your storage
account. This container does not show up if you list all the blob containers in your account but you can see
its contents if you access it directly.
To view and analyze your log data, you should download the blobs that contain the log data you are
interested in to a local machine. Many storage-browsing tools enable you to download blobs from your
storage account; you can also use the Azure Storage team provided command-line Azure Copy Tool
(AzCopy) to download your log data.
References:
https://docs.microsoft.com/en-us/rest/api/storageservices/enabling-storage-logging-and-accessing-log-
data
QUESTION 16
DRAG DROP
You are developing a solution to visualize multiple terabytes of geospatial data.
The solution has the following requirements:
Data must be encrypted.
Data must be accessible by multiple resources on Microsoft Azure.
You need to provision storage for the solution.
Which four actions should you perform in sequence? To answer, move the appropriate action from the list
of actions to the answer area and arrange them in the correct order.
Select and Place:
Correct Answer:
nityte



剩余261页未读,继续阅读
2022-07-10 上传
2023-06-10 上传
2023-07-25 上传
2023-06-09 上传
2023-05-15 上传
2023-05-31 上传
2023-06-15 上传
2023-05-24 上传
2023-06-02 上传

janelsf
- 粉丝: 0
- 资源: 2
 我的内容管理
展开
我的内容管理
展开







最新资源
- zlib-1.2.12压缩包解析与技术要点
- 微信小程序滑动选项卡源码模版发布
- Unity虚拟人物唇同步插件Oculus Lipsync介绍
- Nginx 1.18.0版本WinSW自动安装与管理指南
- Java Swing和JDBC实现的ATM系统源码解析
- 掌握Spark Streaming与Maven集成的分布式大数据处理
- 深入学习推荐系统:教程、案例与项目实践
- Web开发者必备的取色工具软件介绍
- C语言实现李春葆数据结构实验程序
- 超市管理系统开发:asp+SQL Server 2005实战
- Redis伪集群搭建教程与实践
- 掌握网络活动细节:Wireshark v3.6.3网络嗅探工具详解
- 全面掌握美赛:建模、分析与编程实现教程
- Java图书馆系统完整项目源码及SQL文件解析
- PCtoLCD2002软件:高效图片和字符取模转换
- Java开发的体育赛事在线购票系统源码分析
