Hive详解:数据仓库工具与SQL查询处理
Hive是基于Hadoop的大数据处理工具,它专注于在分布式环境下提供结构化数据的存储和查询功能。Hive的核心特点包括:
1. **数据仓库工具**:Hive的设计初衷是将Hadoop中的大规模数据结构化,类似于一个关系型数据库,允许用户使用类似SQL的语言HiveQL(Hive Query Language)进行操作,这对于熟悉SQL的开发者来说非常便捷。
2. **SQL处理扩展**:Hive在Hadoop上实现了扩展的SQL处理能力,能够处理PB级别的数据,特别适合于大数据环境下的查询需求。
3. **元数据管理**:Hive将元数据(如表结构、分区信息、属性等)存储在独立的数据库中,如MySQL或Derby,这有助于提高数据管理和查询性能。
4. **查询过程**:Hive的查询流程包括词法分析、语法分析、编译、优化和查询计划生成,这些步骤生成的执行计划存储在Hadoop分布式文件系统(HDFS)中,然后由MapReduce执行。
5. **数据存储**:Hive的数据存储完全依赖于HDFS,所有的查询,除了包含通配符`*`的全表扫描,大部分会触发MapReduce作业来执行。
6. **局限性**:Hive不支持实时数据更新,数据的插入、删除和修改必须通过创建新的表或分区来实现。此外,由于其基于MapReduce的执行机制,查询响应时间相对较高,但这是为了换取在大数据集上的高效访问。
7. **可扩展性**:作为Hadoop生态系统的一部分,Hive的可扩展性取决于Hadoop本身,理论上,Hadoop的扩展能力有限,但可以通过增加硬件资源来提升性能。
8. **使用场景**:目前主要应用于处理结构化数据,对于非结构化数据的支持相对较弱,但随着技术发展,Hive也在不断进化,可能涉及对半结构化或JSON数据的处理。
学习Hive意味着理解其在大数据处理中的角色,掌握HQL的使用,以及如何与Hadoop生态系统其他组件协同工作,以实现高效的批量数据处理和分析。
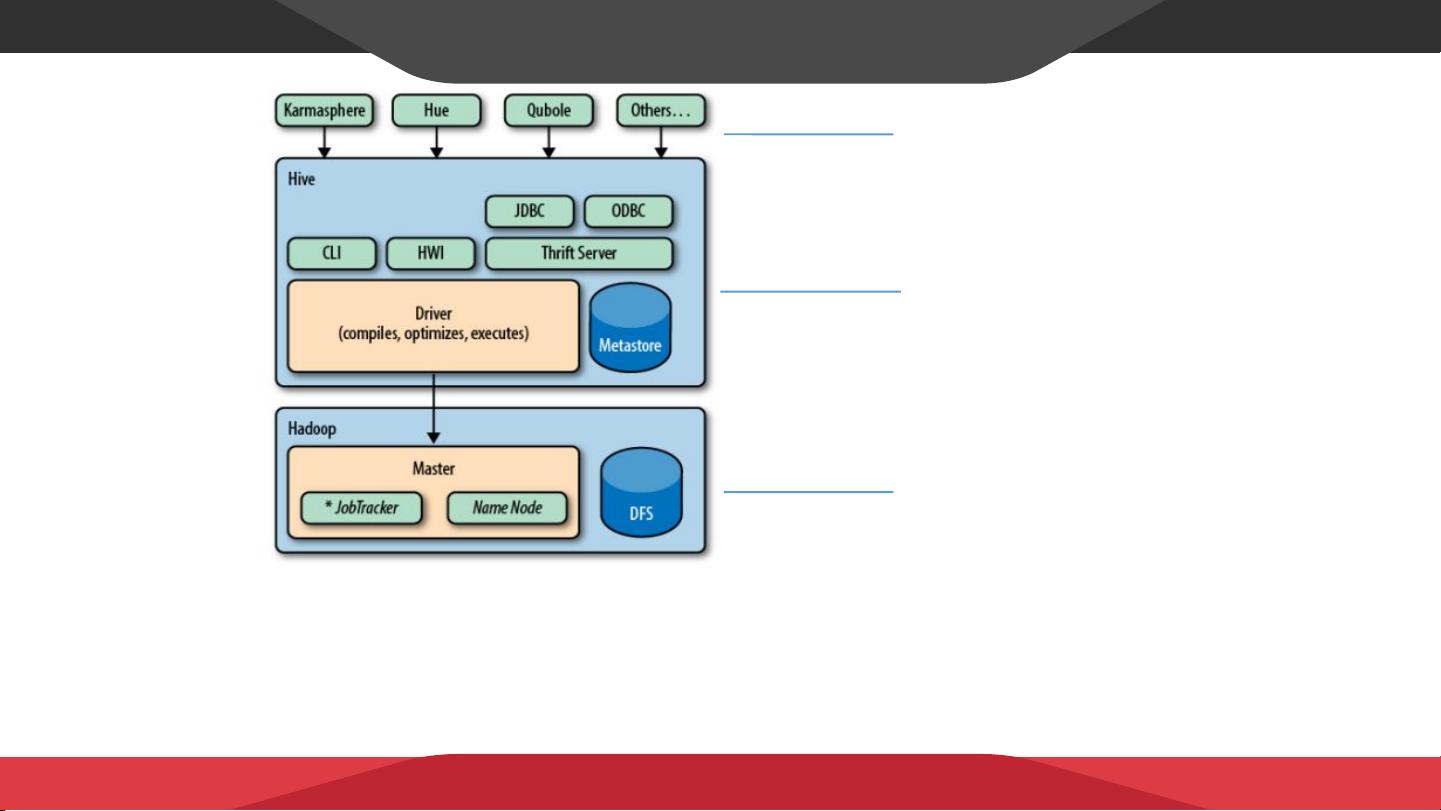
建立在 Hive 之上的交换层
让传统 DBA 或者 Java 工程师轻松
就能完成更多的工作
最终转化成 MapReduce Job
Hive 架构
Hive 将元数据存储在数据库中,如 mysql 、 derby 。 Hive 中的元数据包括表的名字,表的列和分区及其属性,表的
属性(是否为外部表等),表的数据所在目录等。
解释器、编译器、优化器完成 HQL 查询语句从词法分析、语法分析、编译、优化以及查询计划的生成。生成的查询
计划存储在 HDFS 中,并在随后有 MapReduce 调用执行。
Hive 的数据存储在 HDFS 中,大部分的查询由 MapReduce 完成(包含 * 的查询,比如 select * from tbl 不会生成
MapRedcue 任务)。
剩余22页未读,继续阅读
2021-09-12 上传
2023-12-03 上传
2023-08-13 上传
2023-06-28 上传
2023-06-06 上传
2023-12-27 上传
2024-07-10 上传

qq_36779605
- 粉丝: 1
- 资源: 2
 我的内容管理
展开
我的内容管理
展开







最新资源
- WPF渲染层字符绘制原理探究及源代码解析
- 海康精简版监控软件:iVMS4200Lite版发布
- 自动化脚本在lspci-TV的应用介绍
- Chrome 81版本稳定版及匹配的chromedriver下载
- 深入解析Python推荐引擎与自然语言处理
- MATLAB数学建模算法程序包及案例数据
- Springboot人力资源管理系统:设计与功能
- STM32F4系列微控制器开发全面参考指南
- Python实现人脸识别的机器学习流程
- 基于STM32F103C8T6的HLW8032电量采集与解析方案
- Node.js高效MySQL驱动程序:mysqljs/mysql特性和配置
- 基于Python和大数据技术的电影推荐系统设计与实现
- 为ripro主题添加Live2D看板娘的后端资源教程
- 2022版PowerToys Everything插件升级,稳定运行无报错
- Map简易斗地主游戏实现方法介绍
- SJTU ICS Lab6 实验报告解析
