优化Hive性能:SQL处理、与关系DB对比及高效Join策略
版权申诉
129 浏览量
更新于2024-07-03
收藏 405KB DOCX 举报
Hive 是一个专为大数据处理设计的工具,它提供了一个 SQL 接口,使得非技术背景的用户能够利用 Hadoop 集群处理和分析结构化和非结构化的海量数据(PB级别)。Hive 的核心优势在于其扩展性和对大规模数据集的处理能力,支持 SQL92 标准并扩展了部分功能。
Hive 关注的重点包括:
1. 可扩展的 SQL 处理:Hive 能够处理超过 100 PB 的数据,通过 MapReduce 并行计算模型实现高效处理。
2. 结构化和非结构化数据兼容:Hive 支持 SQL 查询,可以无缝地处理来自各种数据源的结构化数据,如表格和半结构化数据,如 JSON 和 XML。
与传统关系型数据库的对比中,Hive 强调了以下特点:
- Hive 作为 Hadoop 生态系统的一部分,提供了分布式查询的能力,而传统的 RDBMS 通常局限于单机性能。
- Hive 的设计更侧重于大规模数据的批处理而非实时事务处理,这与在线事务处理(OLTP)系统的优化有所不同。
Hive 中的 Join 操作是一个关键知识点,尽管有时被误认为是性能瓶颈,但实际上在分析场景中必不可少。有以下几种 Join 策略:
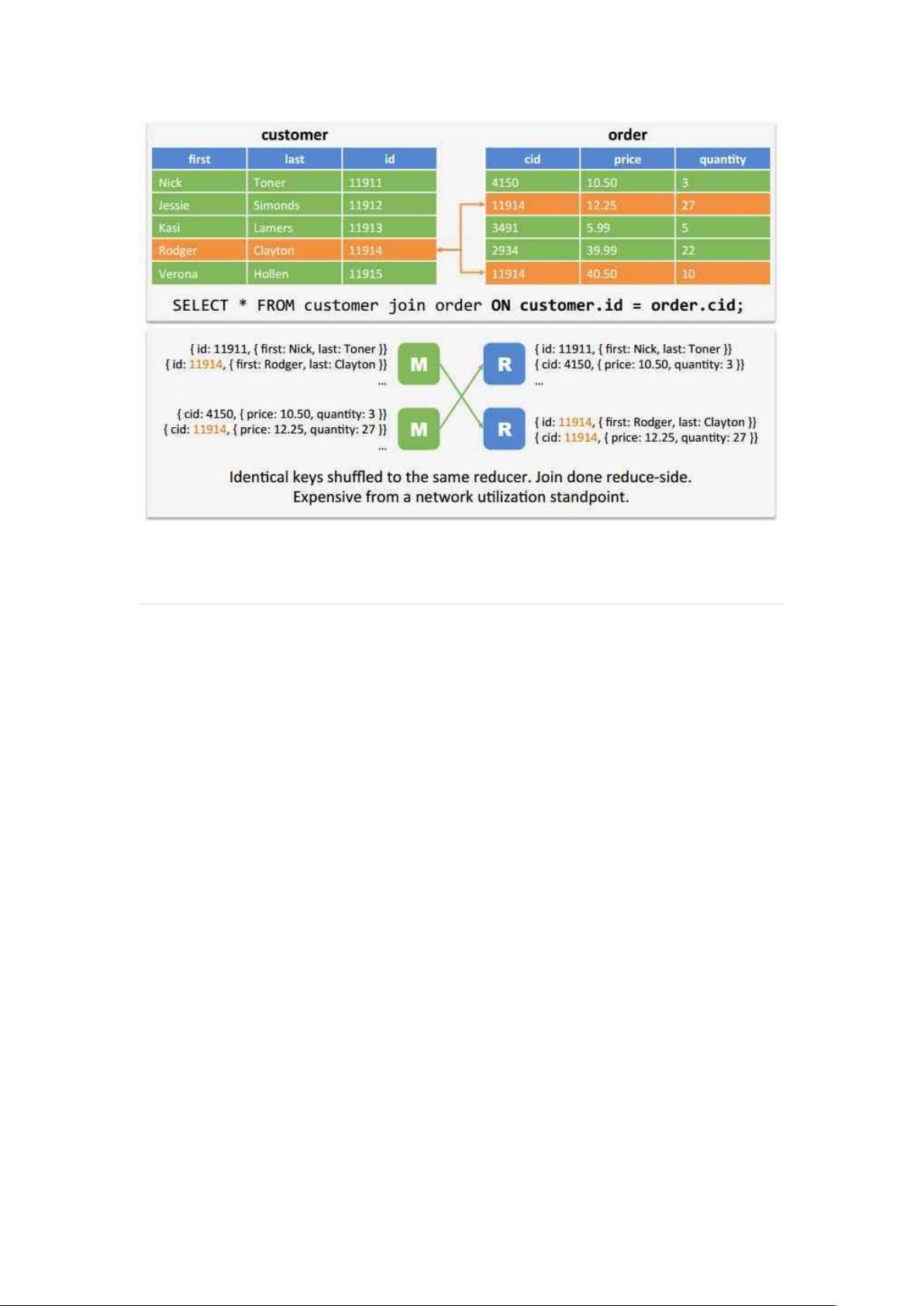
- Reduce-side join (Shuffle Join):这是 MapReduce 中最常见的 Join 方法,数据在 Shuffle 过程中进行合并,适用于大规模数据的全表扫描。
- Map-side join (Broadcast Join):适用于星型架构(星式模式),其中维度表较小,可以完全加载到所有节点的内存中,便于快速查找。适用于简单的维度查找操作。
- SMB join:当两个表都太大,不适合内存时,可以采用 Small-Medium-Big Join,即先将其中一个表的部分数据加载到内存,然后与另一个大表进行 Join。
值得注意的是,排序对于 Join 的性能至关重要,通过将 Join 键排序,所有的匹配项可以在磁盘上的相同区域找到,而对于 Equi-joins,使用哈希分区可以确保匹配值位于同一节点上,从而减少 shuffle,提高性能。
关于具体的 MapReduce Join 示例代码,可以通过链接(http://my.oschina.net/leejun2005/blog/82523 和 http://my.oschina.net/leejun2005/blog/111963)获取,这些资源会展示如何在实际项目中运用这些 Join 策略,并提供相应的代码实现细节。
学习 Hive 性能优化时,理解这些概念和策略至关重要,包括但不限于数据抽象、Join 策略的选择、以及如何根据数据规模和查询需求调整优化方法。此外,性能调优可能涉及分区、索引、优化查询语句等多方面,需要结合实践经验不断探索和提升。
,- 1/):%.#
0'''0B).#
'0''"" 00
0 *0'"A''-4
剩余21页未读,继续阅读
2019-04-21 上传
106 浏览量
185 浏览量
302 浏览量
107 浏览量
126 浏览量
2024-07-13 上传
166 浏览量
249 浏览量

码农.one
- 粉丝: 7
- 资源: 345
 我的内容管理
展开
我的内容管理
展开







最新资源
- 创新商业公司网页模板
- leetcode-[removed]前攻城狮从零入门算法的宝藏题库,根据算法大师的经验总结了100+道LeetCode力扣的经典题型JavaScript题解和思路。一起加油
- 情侣微信小程序,支持任务完成、奖励兑换、记事本和 Todo-List 等功能.zip
- terminal-context-menu
- QT5.13.1的MySQL所需文件.rar
- 中秋节动态宽银幕中国风ppt片头动画模板.rar
- 绿色电子科技商务网页模板
- nodeul-market-retro
- firmware-master.zip
- 投资组合:个人投资组合
- 中国电信分公司微博运营策划方案ppt模板.rar
- 绿色城市生活公司网页模板
- simpy_practice:引用官方文档中的示例:https:simpy.readthedocs.ioenlatestindex.html
- 商务团队背景图片PPT模板
- PSEC:对等安全临时通信协议
- java源码查看-pimcore-groupdocs-viewer-java-source:适用于PimCore的GroupDocsViewe
