整合异构数据:IBM SPSS Modeler的数据库节点操作详解
174 浏览量
更新于2024-08-28
收藏 1.34MB PDF 举报
在本文中,我们将深入探讨如何利用IBM SPSS Modeler这款强大的数据分析工具来整合不同数据库之间的数据。IBM SPSS Modeler作为IBM在商业智能和预测分析领域的核心组件,提供了一套完整的数据挖掘工具集,帮助用户快速构建预测模型并将其应用到实际业务决策中,提升决策效率。
文章首先介绍了IBM SPSS Modeler的界面,如图1所示,其工作原理是基于数据流模型,通过一系列节点来处理数据。这些节点包括但不限于:
1. 数据源节点:负责从各种数据库(如关系型数据库、IBM SPSS Analytic Server、文本文件、SPSS Statistics文件、Excel和XML等)导入数据,这是整合不同数据库的第一步。
2. 记录选项节点:针对数据记录执行操作,如数据选择、排序、抽样、合并和追加,确保数据的准确性和完整性。
3. 字段选项节点:用于处理字段,如数据过滤、创建新字段以及调整字段的测量级别,有助于数据清洗和预处理。
4. 图形节点:在建模过程中,通过图表展示数据,如散点图、直方图、网络图和评估图表,便于可视化理解和探索数据模式。
5. 建模节点:提供了丰富的建模算法,如神经网络、决策树、贝叶斯网络、聚类、支持向量机和排序等,用于构建预测模型。
6. 输出和导出节点:生成模型的结果,包括数据、图表和模型本身,还可以将这些输出导出到其他IBM SPSS产品(如DataCollection)、数据库、XML、IBM SPSS Analytic Server或其他外部应用。
7. IBM SPSS Statistics节点:此功能允许在Modeler与SPSS Statistics之间进行数据交换,利用SPSS Statistics的强大统计分析能力。
8. IBM SPSS SDAP介绍:文章还提到了IBM SPSS Data Access Pack (SDAP),它是Modeler附带的ODBC驱动程序,用于增强Modeler与更多数据源的连接能力。
本文详细展示了如何利用IBM SPSS Modeler进行跨数据库的数据整合,从数据获取、预处理到模型构建,再到结果输出和导出,涵盖了整个数据处理和分析的生命周期。通过掌握这些技术,用户可以在实际项目中高效地利用数据资源,推动业务决策的科学化。
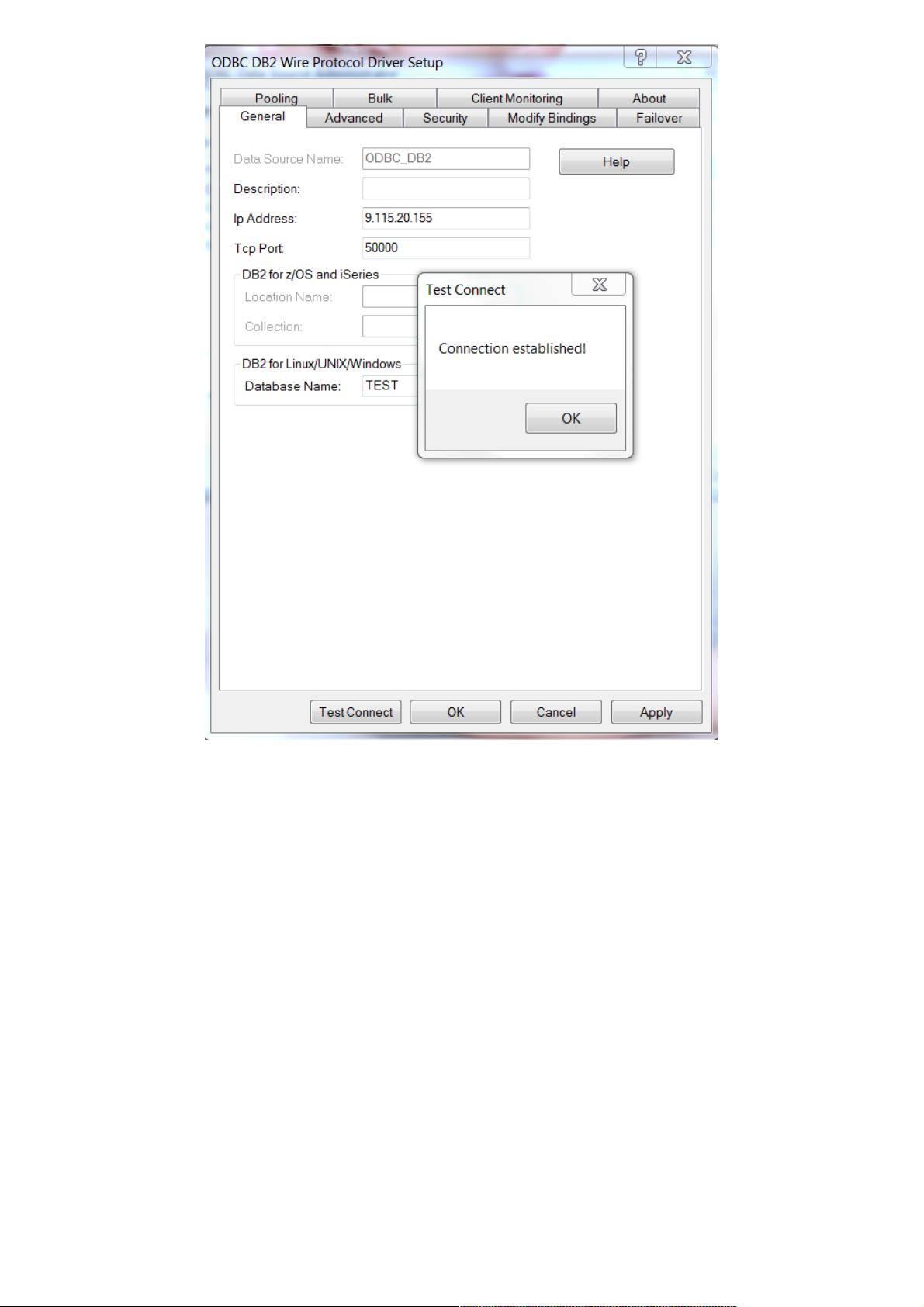
图 4. 创建 DB2 ODBC
在“ODBC DB2 Wire Protocol 驱动程序设置”对话框中需要指定如下内容:
数据源名称(指定一个 ODBC 的名字);
IP 地址,指定 DB2(Oracle,SQL Server) RDBMS 所在服务器的主机名或者 IP 地址;
TCP 端口 ( 对于 DB2,默认是 50000,Oracle 是 1521,SQL Server 是 1433);
数据库的名称(指定需要连接的数据库);
点击“测试连接”后,输入要连接数据库的用户名和密码,然后单击确定按钮。此时会显示“连接已建立!”的消息,说明配置成
功。
对于 Oracle 数据库来说,如图 5 所示:
剩余11页未读,继续阅读
2021-03-04 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
2024-12-21 上传
2024-12-21 上传

weixin_38576392
- 粉丝: 7
- 资源: 896
 我的内容管理
展开
我的内容管理
展开







最新资源
- JavaScript实现的高效pomodoro时钟教程
- CMake 3.25.3版本发布:程序员必备构建工具
- 直流无刷电机控制技术项目源码集合
- Ak Kamal电子安全客户端加载器-CRX插件介绍
- 揭露流氓软件:月息背后的秘密
- 京东自动抢购茅台脚本指南:如何设置eid与fp参数
- 动态格式化Matlab轴刻度标签 - ticklabelformat实用教程
- DSTUHack2021后端接口与Go语言实现解析
- CMake 3.25.2版本Linux软件包发布
- Node.js网络数据抓取技术深入解析
- QRSorteios-crx扩展:优化税务文件扫描流程
- 掌握JavaScript中的算法技巧
- Rails+React打造MF员工租房解决方案
- Utsanjan:自学成才的UI/UX设计师与技术博客作者
- CMake 3.25.2版本发布,支持Windows x86_64架构
- AR_RENTAL平台:HTML技术在增强现实领域的应用
