Spark运行架构详解:Driver, Executor与ClusterManager的作用
135 浏览量
更新于2024-08-28
收藏 1.68MB PDF 举报
"Spark运行架构概述,包括Application、Driver、Executor和ClusterManager的定义与功能,以及Spark在不同集群管理器下的运行方式。"
Spark是一个分布式计算框架,它以其高效、弹性以及对迭代计算的良好支持而闻名。Spark的运行架构是理解其性能和工作原理的关键。以下是关于Spark运行架构的详细解析:
1. **Application(应用程序)**
Spark Application与Hadoop MapReduce中的应用程序概念相似,指的是用户编写的Spark程序,这个程序由两部分组成:一部分是运行在Driver上的代码,这部分包含了应用程序的main()函数;另一部分是分布在集群多个Worker节点上的Executor代码,这些Executor负责执行实际的计算任务。
2. **Driver(驱动器)**
Driver程序是Application的起点,它执行main()函数并创建SparkContext。SparkContext是Spark应用程序的核心,它与ClusterManager通信,负责资源的申请、任务调度以及监控整个应用程序的执行状态。Driver程序在整个应用程序执行完毕后,会关闭SparkContext。
3. **Executor(执行器)**
Executor是在Worker节点上运行的一个进程,每个Executor可以并行运行多个Task,具体数量取决于分配给它的CPU核心数。Executor负责执行Task,同时在内存或磁盘上存储数据。在Spark on Yarn模式下,Executor进程被称为CoarseGrainedExecutorBackend,它将Task包装成taskRunner,并从线程池中选择线程执行。
4. **ClusterManager(集群管理器)**
ClusterManager是负责在集群上分配和管理资源的服务。Spark支持多种集群管理器:
- Standalone:Spark自带的资源管理系统,由Master节点负责资源调度。
- Hadoop YARN:在这种模式下,资源分配由YARN的ResourceManager处理。
5. **Worker(工作节点)**
Worker是能够运行Application代码的集群节点。在Standalone模式中,Worker由配置在Slave文件中的节点组成;而在Spark on Yarn模式下,Worker相当于YARN的NodeManager,负责运行Executor。
6. **作业(Job)与Task**
作业(Job)是Spark中的基本执行单元,由多个Task组成,它们可以并行执行。Job通常由Spark的“Action”操作触发,如`save`、`collect`等,这些操作会导致实际的数据计算和输出。
Spark的运行架构设计使得它能够快速地处理大量数据,通过DAG(有向无环图)任务调度和内存计算优化,实现高效的数据处理和分析。了解这些基础概念有助于更好地理解和优化Spark应用程序的性能。
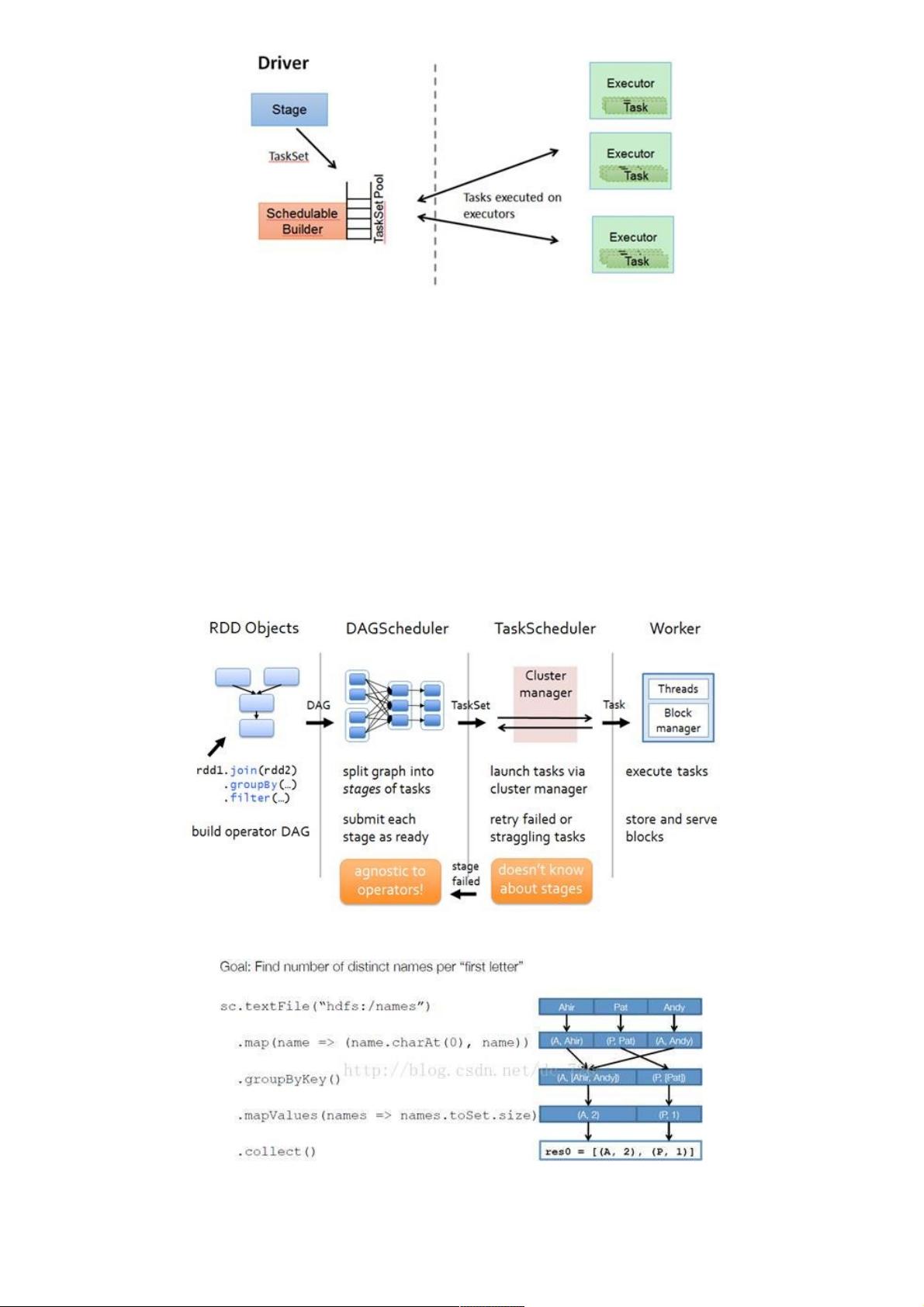
在不同运行模式中任务调度器具体为:
Spark on Standalone模式为TaskScheduler;
YARN-Client模式为YarnClientClusterScheduler
YARN-Cluster模式为YarnClusterScheduler
1.3 RDD运行原理
那么 RDD在Spark架构中是如何运行的呢?总高层次来看,主要分为三步:
1.创建 RDD 对象
2.DAGScheduler模块介入运算,计算RDD之间的依赖关系。RDD之间的依赖关系就形成了DAG
3.每一个JOB被分为多个Stage,划分Stage的一个主要依据是当前计算因子的输入是否是确定的,如果是则将其分在同一个
Stage,避免多个Stage之间的消息传递开销。
以下面一个按 A-Z 首字母分类,查找相同首字母下不同姓名总个数的例子来看一下 RDD 是如何运行起来的。
步骤 1 :创建 RDD 上面的例子除去最后一个 collect 是个动作,不会创建 RDD 之外,前面四个转换都会创建出新的 RDD 。
因此第一步就是创建好所有 RDD( 内部的五项信息 ) 。
步骤 2 :创建执行计划 Spark 会尽可能地管道化,并基于是否要重新组织数据来划分 阶段 (stage) ,例如本例中的 groupBy()
转换就会将整个执行计划划分成两阶段执行。最终会产生一个 DAG(directed acyclic graph ,有向无环图 ) 作为逻辑执行计
剩余13页未读,继续阅读
893 浏览量
点击了解资源详情
210 浏览量
点击了解资源详情
153 浏览量
839 浏览量
806 浏览量
145 浏览量
1399 浏览量

weixin_38606019
- 粉丝: 4
- 资源: 935
 我的内容管理
展开
我的内容管理
展开







最新资源
- Pandas
- Platformer:仅具有浏览器功能的应用
- ssm海尔集团商务系统的设计毕业设计程序
- 手机接收单片机数据例程.zip
- notify-monitor:REST API可以观察任何新广告的给定URL,并将其发送到notify-client。 堆
- pgsync:将数据从一个Postgres数据库同步到另一个数据库
- Klaverjas Score-开源
- Simple Web Paint Application using JavaScrip
- Incremental-Adventure-Genesis:网页游戏(WIP)
- NET3.5 LINQ操作数据库实例_aspx开发教程.rar
- stm32 跑马灯实验+例程
- python之knnk近邻算法实现属性为连续性及混淆矩阵评估.zip
- g30l0:地理定位应用程序,用于在培训之前测试ESDK
- Kifu Generator-开源
- css-essentials-css-issue-bot-9000-midtown-web-071519
- chargeTracker
