Kudu:实时数据分析与分布式存储解决方案
129 浏览量
更新于2024-08-28
收藏 337KB PDF 举报
"kudu原理与使用"
Kudu是一种列式存储的分布式数据库,设计目标是在保持数据实时更新的同时,提供快速的数据分析能力。它填补了HDFS和HBase在特定场景下的不足,既具备比HDFS更好的实时写入和更新性能,又在批处理速度上优于HBase,更适合在线分析(OLAP)和实时写入需求。
1. Kudu的出现背景
在大数据存储领域,HDFS虽然适合离线分析,但不支持单条记录级别的更新,且随机读写性能较差;而HBase则擅长随机读写,但不适用于复杂的SQL查询和大批量数据获取。Kudu的诞生就是为了平衡这两者,它提供了快速的更新和查询能力,支持实时分析和批量操作。
2. Kudu架构
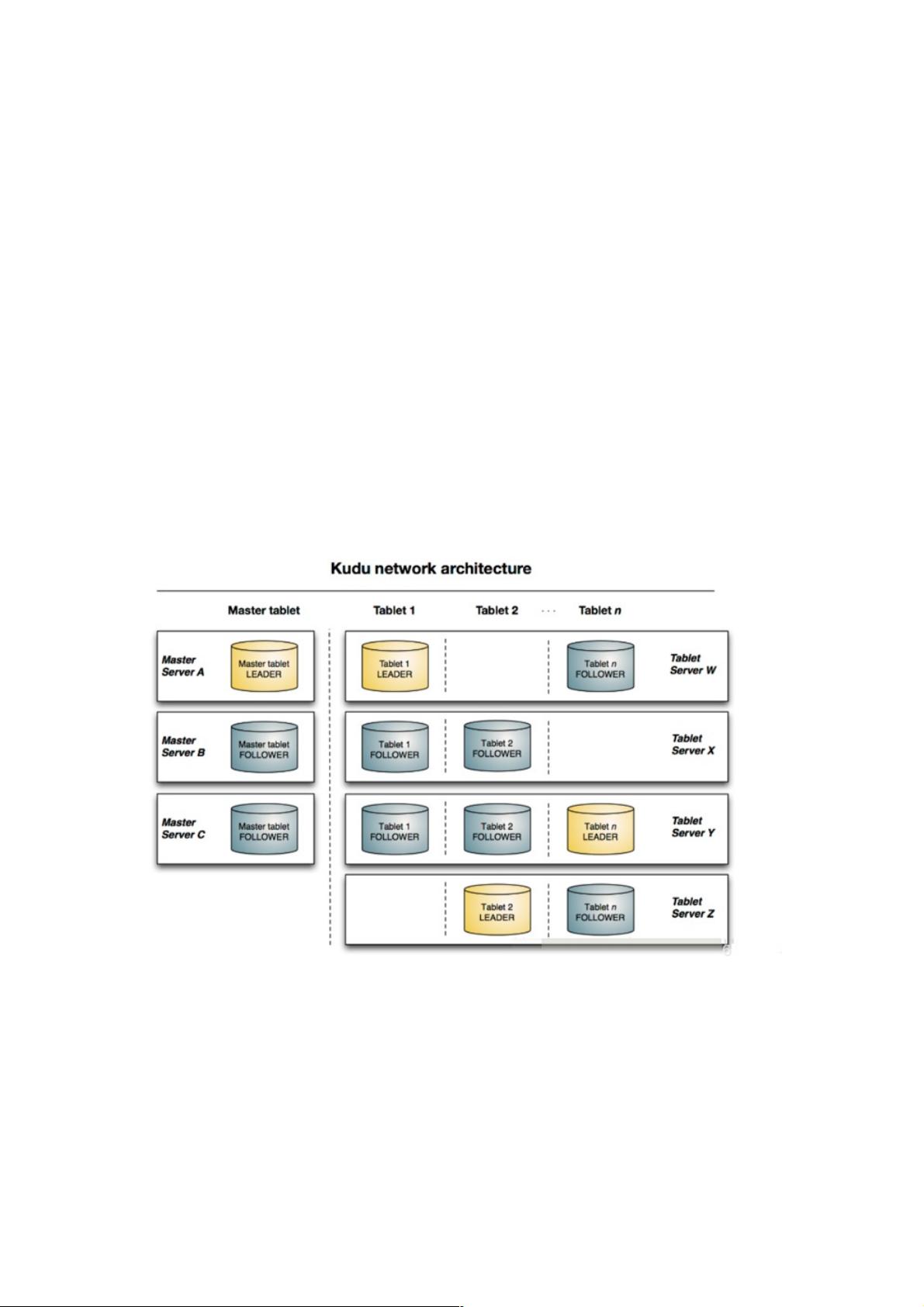
- Table:是数据存储的单位,拥有schema和全局有序的primary key。Table被分割成多个Tablet。
- Tablet:类似于分区,是Table的一段连续数据,有副本机制,包括一个Leader Tablet和多个Follower Tablet。
- Tablet Server:存储Tablet并提供客户端服务,每个Tablet在一个Tablet Server上作为Leader,其他Server作为Follower,仅Leader接受写请求,所有副本都参与读请求。
- Master:管理元数据,如tablet和表的信息,监控Tablet Server状态,元数据存储在Catalog Table中。
3. Kudu的优势
- 高效的更新与查询:Kudu支持低延迟的插入、更新和删除操作,同时能进行快速的范围扫描,适合实时分析。
- 弹性扩展:通过增加Tablet Server数量可线性扩展存储和处理能力。
- 数据一致性:通过多副本机制确保数据一致性,即使在节点故障时也能保证服务不中断。
- 分布式事务:支持多版本并发控制(MVCC),确保并发操作的正确性。
- SQL支持:Kudu可以与SQL接口集成,如Apache Impala和Apache Spark,便于数据分析。
4. 使用场景
Kudu适用于需要实时分析的场景,例如在线日志分析、实时报表生成、流处理以及需要快速响应更新的应用。由于其特性,它特别适合那些需要频繁更新和实时查询的数据应用。
Kudu是一个兼顾实时写入和高效分析的数据库系统,它的设计旨在满足现代大数据环境中的混合工作负载需求,特别是在需要快速响应更新和分析的场景下,Kudu提供了优于HDFS和HBase的解决方案。
kudu原理与使用原理与使用
1、 kudu简介
1.1、kudu是什么?
简单来说:dudu是一个与hbase类似的列式存储分布式数据库。
官方给kudu的定位是:在更新更及时的基础上实现更快的数据分析
1.2、为什么需要kudu?
1.2.1、hdfs与hbase数据存储的缺点
目前数据存储有了HDFS与hbase,为什么还要额外的弄一个kudu呢?
HDFS:使用列式存储格式Apache Parquet,Apache ORC,适合离线分析,不支持单条纪录级别的update操作,随机读写性
能差
HBASE:可以进行高效随机读写,却并不适用于基于SQL的数据分析方向,大批量数据获取时的性能较差。
正因为HDFS与HBASE有上面这些缺点,KUDU较好的解决了HDFS与HBASE的这些缺点,它不及HDFS批处理快,也不及
HBase随机读写能力强,但是反过来它比HBase批处理快(适用于OLAP的分析场景),而且比HDFS随机读写能力强(适用
于实时写入或者更新的场景),这就是它能解决的问题。
2、架构介绍
2.1、基本架构
2.1.1、概念
Table(表):一张table是数据存储在kudu的位置。Table具有schema和全局有序的primary key(主键)。Table被分为很多
段,也就是tablets.
Tablet (段):一个tablet是一张table连续的segment,与其他数据存储引擎或关系型数据的partition相似。Tablet存在副本机
制,其中一个副本为leader tablet。任何副本都可以对读取进行服务,并且写入时需要在所有副本对应的tablet server之间达成
一致性。
Tablet server:存储tablet和为tablet向client提供服务。对于给定的tablet,一个tablet server充当leader,其他tablet server充
当该tablet的follower副本。只有leader服务写请求,leader与follower为每个服务提供读请求。
Master:主要用来管理元数据(元数据存储在只有一个tablet的catalog table中),即tablet与表的基本信息,监听tserver的状态
Catalog Table: 元数据表,用来存储table(schema、locations、states)与tablet(现有的tablet列表,每个tablet及其副本所处
tserver,tablet当前状态以及开始和结束键)的信息。
下载后可阅读完整内容,剩余4页未读,立即下载
点击了解资源详情
点击了解资源详情
点击了解资源详情
2021-01-27 上传
2019-03-20 上传
2022-01-04 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情

weixin_38656103
- 粉丝: 0
- 资源: 956
 我的内容管理
展开
我的内容管理
展开







