深度学习高效处理教程:架构与技术综览
需积分: 50 2 浏览量
更新于2024-07-17
收藏 5.13MB PDF 举报
本文档深入探讨了"Efficient Processing of Deep Neural Networks: A Tutorial and Survey",它作为深度学习领域的重要参考资料,提供了对自本世纪初以来深度学习技术迅猛发展及其在硬件加速方面的最新进展进行全面的概述。深度神经网络(DNNs)凭借其在计算机视觉、语音识别和机器人技术等人工智能应用中的卓越性能,已成为行业的标准。然而,其高度计算复杂性使得能源效率和吞吐量的提升成为亟待解决的问题,同时还需要维持或提高性能准确性和控制硬件成本。
文章首先介绍了深度神经网络的基本概念和原理,强调了在AI系统中广泛应用DNNs所面临的挑战,即如何在保持高性能的同时实现计算效率的提升。接下来,作者详细梳理了各类支持DNN的平台和架构,包括云端服务器、嵌入式设备、专用硬件如GPU和TPU,以及FPGA和ASIC等,这些硬件的不同特性决定了它们在处理深度学习任务时的优势和局限性。
重点部分深入讨论了近期在提高DNN效率方面的主要技术趋势。这包括但不限于:
1. **模型优化**:通过对神经网络结构进行剪枝、量化和蒸馏,降低模型的参数数量和计算复杂度,从而减少运算需求,提高执行速度。
2. **硬件加速**:通过硬件设计的专门化,如GPU的并行计算能力、TPU的矩阵运算优化,以及定制芯片(ASIC)的低延迟和高能效,来加速深度学习任务的处理。
3. **近似计算**:利用近似计算和低精度计算技术,允许在一定程度上牺牲精确度以换取更高的性能,这对于实时应用和移动设备尤其关键。
4. **硬件-software协同**:通过软件层面的优化,如数据预处理、模型编译和硬件调度策略,以及硬件和软件之间的协同工作,来进一步提升整体效率。
5. **动态调度和适应性**:通过动态调整网络执行策略,根据任务需求和硬件资源实时改变计算负载,实现资源的高效利用。
6. **可扩展性和灵活性**:研究如何在不同的硬件环境下实现深度学习模型的无缝迁移,以适应不同场景的需求。
这篇文章是一份宝贵的指南,对于研究人员、工程师和开发者来说,它不仅提供了深度学习基础的回顾,还提供了关于如何在实际应用中实现高效处理DNNs的实用策略和趋势分析,为推动AI系统的广泛应用和发展奠定了坚实的基础。
6
the output. In these networks, some intermediate operations
generate values that are stored internally to the network and
used as inputs to other operations in conjunction with the
processing of a later input. In this article, we will focus on
feed-forward networks as to-date little attention has been given
to hardware acceleration specifically of recurrent networks.
DNNs can be composed of fully-connected (FC, also referred
to as multi-layer perceptrons) as shown in the leftmost layer
of Fig. 2(d). In a fully-connected layer, all output activations
are composed of a weighted sum of all input activations
(i.e., all outputs are connected to all inputs). This requires a
significant amount of storage and computation. Thankfully, in
many applications, we can remove some connections between
the activations by setting the weights to zero without affecting
accuracy. This results in a sparsely-connected layer. A sparsely
connected layer is illustrated in the rightmost layer of Fig. 2(d).
We can also make the computation more efficient by limiting
the number of weights that contribute to an output. This sort of
structured sparsity can arise if each output is only a function
of a fixed-size window of inputs. Even further efficiency can
be gained if the same set of weights are used in the calculation
of every output. This weight sharing can significantly reduce
the storage requirements for weights.
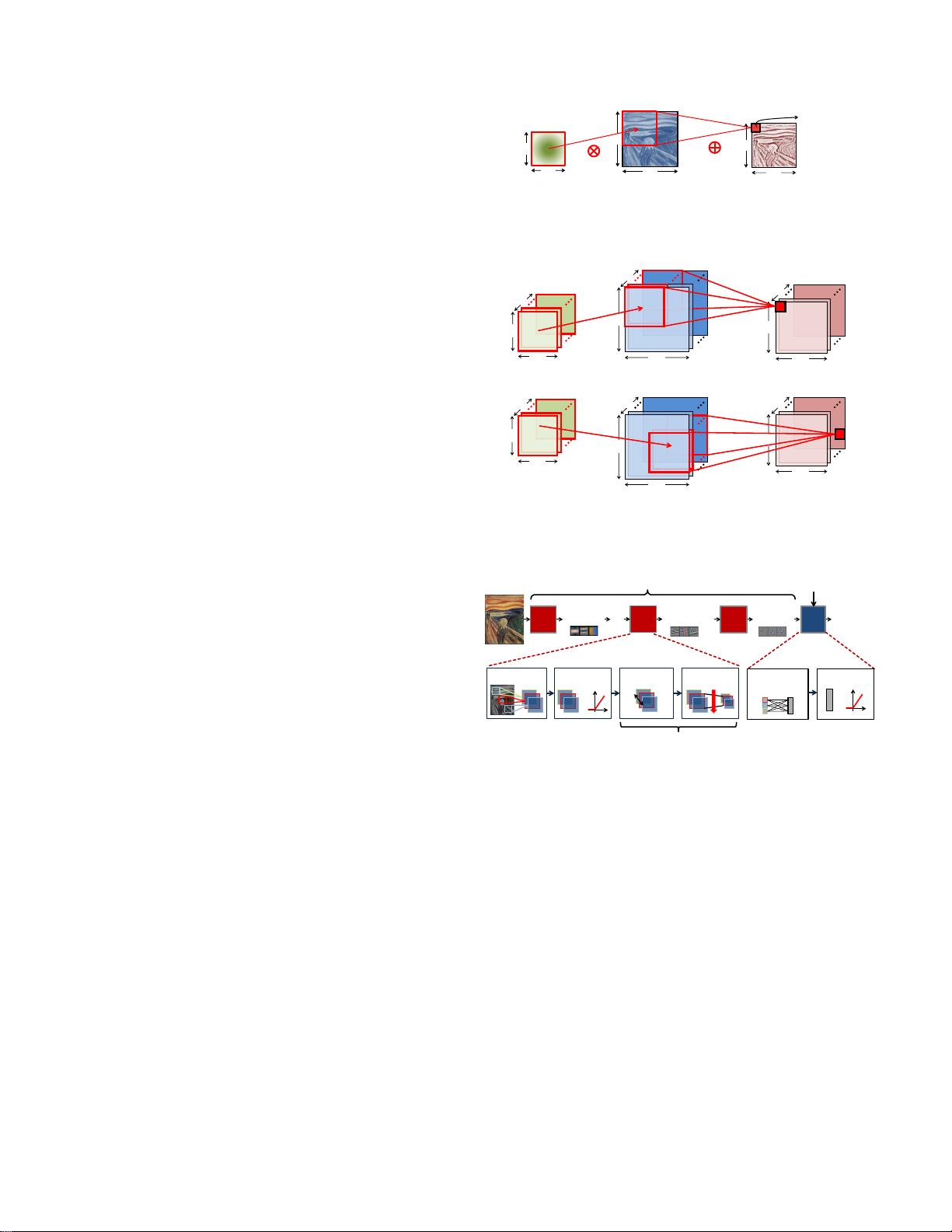
An extremely popular windowed, weight-shared network
arises by structuring the computation as a convolution, as
shown in Fig. 6(a), where the output is computed using only
a small neighborhood of activations for the weighted sum (i.e.,
the filter has a limited receptive field, and all weights beyond
a certain distance from the input is set to zero), and where
the same set of weights are shared for every output (i.e., the
filter is space invariant). This is a form of structured sparsity
is orthogonal to the sparsity that occurs from network pruning
as described in Section
VII-B
2. Accordingly, a convolutional
neural network (CNN) is a popular form of DNN [35].
1) Convolutional Neural Networks (CNNs): CNNs are
composed of multiple convolutional layers (CONV), as shown
in Fig. 7, where each layer generates a higher-level abstraction
of the input data, called a feature map (fmap), that preserves
essential yet unique information. Modern CNNs are able
to achieve superior performance by employing a very deep
hierarchy of layers. CNN, also known as ConvNets, are
widely used in a variety of applications including image
understanding [
3
], speech recognition [
36
], game play [
6
],
robotics [
28
], etc. The paper will focus on its use in image
processing, specifically for the task of image classification [
3
].
Each of the CONV layers in the CNN is primarily composed
of high-dimensional convolutions as shown in Fig. 6(b). In this
computation there are a set of 2-D input feature maps (ifmaps),
each of which is called a channel. Each channel is convolved
with a distinct 2-D filter from the stack of filters, one for
each channel. The results of the convolution at each point are
summed across all the channels. In addition, a 1-D bias can be
added to the filtering results, but some recent networks [
11
]
remove its usage from part of the layers. The result of this
computation is one channel of output feature map (ofmap).
Additional stacks of 2-D filters can be used on the same input
to create additional output channels. Finally, multiple stacks
of input feature maps may be processed together as a batch to
R
filter (weights)
S
E
F
Partial Sum (psum)
Accumulation
input fmap output fmap
Element-wise
Multiplication
H
W
an output
activation
(a) 2-D convolution in traditional image processing
Input fmaps
Filters
Output fmaps
R
S
C
…
H
W
C
…
E
F
M
E
F
M
…
R
S
C
H
W
C
1
N
1
M
1
N
(b) High dimensional convolutions in CNNs
Fig. 6. Dimensionality of convolutions.
Modern Deep CNN: 5 – 1000 Layers
Class
Scores
FC
Layer
CONV
Layer
Low-Level
Features
CONV
Layer
High-Level
Features
…
1 – 3 Layers
Convolu'on(
Non-linearity(
×(
Normaliza'on(
Pooling(
Optional
Fully(
Connected(
×(
Non-linearity(
CONV
Layer
Mid-Level
Features
Fig. 7. Convolutional Neural Networks.
potentially improve reuse of the filter weights.
Given the shape parameters in Table I, the computation of
a CONV layer is defined as
O[z][u][x][y] = B[u] +
C−1
X
k=0
R−1
X
i=0
R−1
X
j=0
I[z][k][Ux + i][Uy + j] × W[u][k][i][j],
0 ≤ z < N, 0 ≤ u < M, 0 ≤ x, y < E, E = (H − R + U)/U.
(1)
O
,
I
,
W
and
B
are the matrices of the ofmaps, ifmaps, filters
and biases, respectively.
U
is a given stride size. Fig. 6(b)
shows a visualization of this computation (ignoring biases).
To align the terminology of CNNs with the generic DNN,
• filters are composed of weights (i.e., synapses)
• input images are composed of pixels (i.e., input neurons
to first layer)
•
input and output feature maps (ifmaps, ofmaps) are
composed of activations (i.e., input and output neurons)
剩余30页未读,继续阅读
点击了解资源详情
点击了解资源详情
点击了解资源详情
2020-05-08 上传
2017-09-05 上传
2024-01-23 上传
2024-01-22 上传
2021-09-23 上传
2021-09-25 上传

Dongxu_Lv
- 粉丝: 1507
- 资源: 5
 我的内容管理
展开
我的内容管理
展开







最新资源
- iec61850:IEC 61850 协议实现
- PID-Control-System,数字转字符串c语言源码实现,c语言程序
- george-connect:George Connect-与您的同事保持联系
- device_xiaomi_phoenix:POCO X2Redmi K30的设备树
- portfolio
- hltv-rs:(WIP)非官方的HLTV Rust API
- github-slideshow:机器人提供动力的培训资料库
- TextComparer:文本比较器
- eslint-plugin-class-prefer-methods:eslint插件报告不需要的箭头功能而不是类方法的用法
- ARM-DEV,c语言生成xml格式的源码,c语言程序
- snapnet
- 软件开发项目企业官网模板
- Online-Music-Sharing
- 三色灯控制开发Demo
- mission-extract-bit
- son_jay:结构化数据和 JSON 之间的对称转换
