腾讯TDW:构建超大规模Hadoop集群的数据仓库
144 浏览量
更新于2024-08-28
收藏 333KB PDF 举报
“腾讯TDW是腾讯构建的大型分布式数据仓库,基于Hadoop和Hive,针对腾讯的大数据量和复杂计算需求进行了优化。它服务腾讯的大部分业务,拥有4400台服务器的集群规模,存储容量达100PB,每日处理100多万作业,计算量4PB,具有高并发能力。TDW包含Hive、MapReduce、HDFS、TDBank和Lhotse等多个功能模块,提供存储、计算和查询服务。TDBank用于数据采集,Lhotse则作为任务调度系统。构建单个大规模集群是为了实现数据共享、计算资源共享以及降低运营成本和负担。”
腾讯TDW作为腾讯的核心离线数据处理平台,其设计和实施考虑了以下几个关键技术点:
1. **分布式存储** - TDW基于Hadoop的HDFS,提供了可扩展的分布式存储解决方案,确保了大规模数据的高效存储和检索。通过优化,实现了高达83%的存储利用率。
2. **并行计算** - 使用MapReduce框架,TDW能够处理复杂的计算任务,支持大量作业并发执行,作业并发数可达2000左右,满足大数据场景下的计算需求。
3. **数据仓库查询** - Hive作为查询引擎,提供了SQL-like接口,使得非技术背景的用户也能方便地进行数据分析。TDW对Hive进行了定制化,以适应腾讯的业务特性。
4. **数据集成** - TDBank作为数据采集工具,统一了数据接入,支持多种数据源,简化了数据处理流程,提高了数据一致性。
5. **任务调度** - Lhotse任务调度系统是TDW的神经系统,负责整个集群的任务分配和管理,确保作业的高效执行和资源的合理利用。
6. **集群规模与效率** - 单一大规模集群的设计减少了跨IDC的数据传输,降低了网络带宽压力,同时通过资源共享,解决了计算资源紧张的问题,降低了运营成本。
7. **高可用与稳定性** - 考虑到运营维护的压力,单个大集群可以简化管理,统一版本升级和监控,增强了系统的整体稳定性和运维效率。
8. **性能优化** - 针对腾讯的特定需求,TDW在存储、计算和网络等方面进行了深度优化,如提高CPU利用率至85%,提升了整个系统的性能。
腾讯TDW通过构建大规模的Hadoop集群,整合了数据存储、计算和查询能力,为腾讯的海量数据处理提供了强大的支撑,有效地解决了数据共享、计算资源管理和运营成本等问题,展现了大数据处理领域的先进实践。
腾讯腾讯TDW:大型大型Hadoop集群应用集群应用
TDW(Tencent distributed Data Warehouse,腾讯分布式数据仓库)基于开源软件Hadoop和Hive进行构建,打破了传统数据
仓库不能线性扩展、可控性差的局限,并且根据腾讯数据量大、计算复杂等特定情况进行了大量优化和改造。
TDW服务覆盖了腾讯绝大部分业务产品,单集群规模达到4400台,CPU总核数达到10万左右,存储容量达到100PB;每日作
业数100多万,每日计算量4PB,作业并发数2000左右;实际存储数据量80PB,文件数和块数达到6亿多;存储利用率83%左
右,CPU利用率85%左右。经过四年多的持续投入和建设,TDW已经成为腾讯最大的离线数据处理平台。
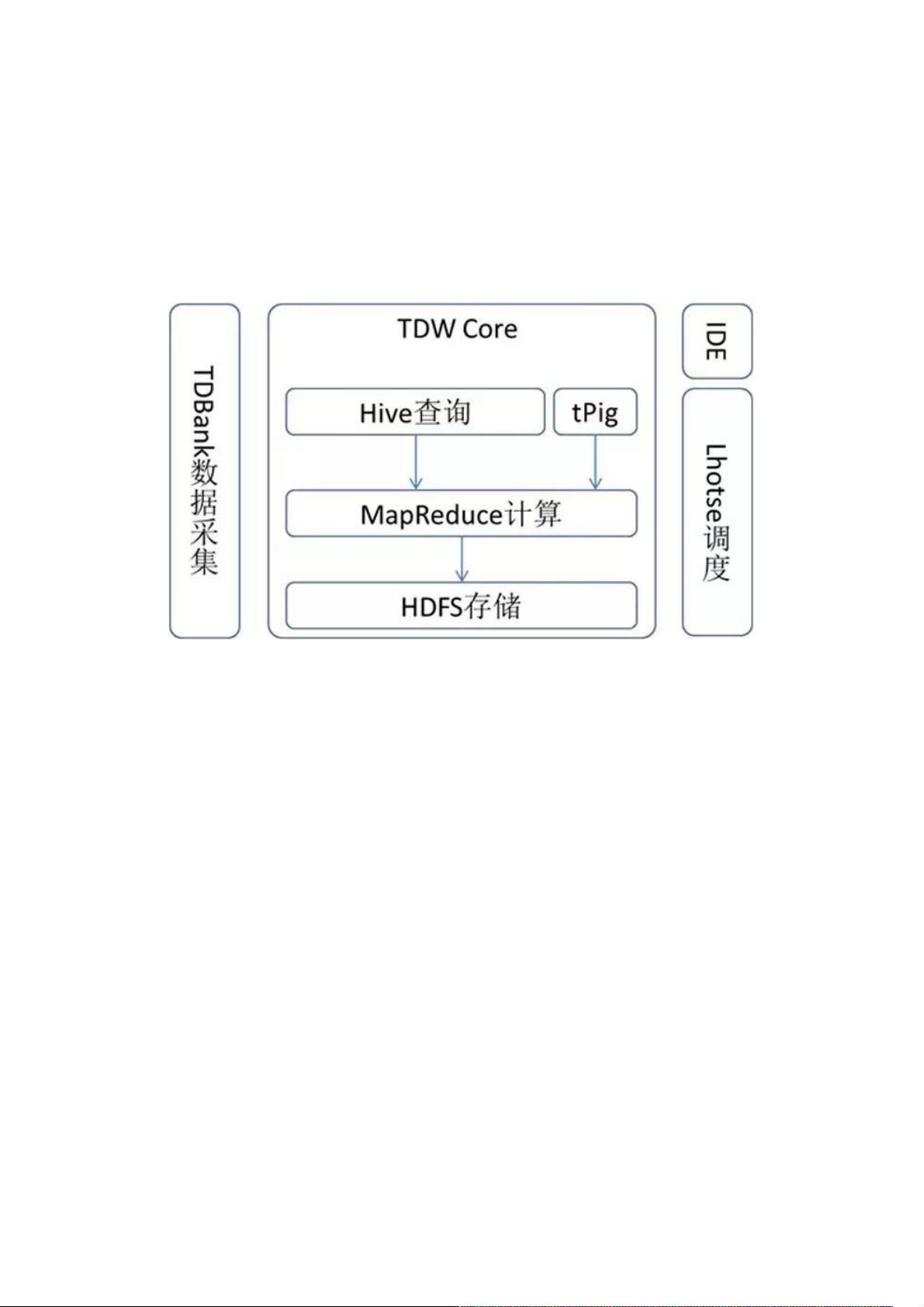
TDW的功能模块主要包括:Hive、MapReduce、HDFS、TDBank、Lhotse等,如图1所示。TDW Core主要包括存储引擎
HDFS、计算引擎MapReduce、查询引擎Hive,分别提供底层的存储、计算、查询服务,并且根据公司业务产品的应用情况
进行了很多深度订製。TDBank负责数据采集,旨在统一数据接入入口,提供多样的数据接入方式。Lhotse任务调度係统是整
个数据仓库的总管,提供一站式任务调度与管理。
图1 TDW的功能模块
建设单个大规模集群的塬因
随着业务的快速增长,TDW的节点数也在增加,对单个大规模Hadoop集群的需求也越来越强烈。TDW需要做单个大规模集
群,主要是从数据共享、计算资源共享、减轻运营负担和成本等叁个方麵考虑。
1. 数据共享。TDW之前在多个IDC部署数十个集群,主要是根据业务分别部署,这样当一个业务需要其他业务的数据,或者
需要公共数据时,就需要跨集群或者跨 IDC访问数据,这样会占用IDC之间的网络带宽。为了减少跨IDC的数据传输,有时会
将公共数据冗余分布到多个IDC的集群,这样又会带来存储空间浪费。
2. 计算资源共享。当一个集群的计算资源由于某些塬因变得紧张时,例如需要数据补录时,这个集群的计算资源就捉襟见
肘,而同时,另一个集群的计算资源可能空闲,但这两者之间没有做到互通有无。
3. 减轻运营负担和成本。十几个集群同时需要稳定运营,而且当一个集群的问题解决时,也需要解决其他集群已经出现的或
者潜在的问题。一个Hadoop版本要在十几个集群逐一变更,监控係统也要在十几个集群上部署。这些都给运营带来了很大负
担。此外,分散的多个小集群,资源利用率不高,机器成本较大。
建设单个大规模集群的方案及优化
麵临的挑战
TDW从单集群400台规模建设成单集群4000台规模,麵临的最大挑战是Hadoop架构的单点问题:计算引擎单点JobTracker负
载重,使得调度效率低、集群扩展性不好;存储引擎单点NameNode没有容灾,使得重启耗时长、不支持灰度变更、具有丢
失数据的风险。TDW单点瓶颈导致平台的高可用性、高效性、高扩展性叁方麵都有所欠缺,将无法支撑4000台规模。为了解
决单点瓶颈,TDW主要进行了JobTracker分散化和 NameNode高可用两方麵的实施。
JobTracker分散化
1.单点JobTracker的瓶颈
TDW以前的计算引擎是传统的两层架构,单点JobTracker负责整个集群的资源管理、任务调度和任务管理,TaskTracker负责
任务执行。JobTracker的叁个功能模块耦合在一起,而且全部由一个Master节点负责执行,当集群并发任务数较少时,这种
架构可以正常运行,但当集群并发任务数达到2000、节点数达到4000时,任务调度就会出现瓶颈,节点心跳处理迟缓,集群
扩展也会遇到瓶颈。
下载后可阅读完整内容,剩余4页未读,立即下载
113 浏览量
2014-03-25 上传
160 浏览量
点击了解资源详情
223 浏览量
132 浏览量
点击了解资源详情
点击了解资源详情
点击了解资源详情

weixin_38685521
- 粉丝: 4
- 资源: 935
 我的内容管理
展开
我的内容管理
展开







最新资源
- NCRE二级C语言程序设计辅导
- basic linux command
- Java笔试时可能出现问题及其答案.doc
- 同济大学线性代数第四版课后习题答案
- A Guide to MATLAB for Beginners and Experienced Users - Hunt Lipsman & Rosenberg
- Oracle9i:SQL Ed 2.0.pdf
- ejb3.0实例教程
- oracle-commands-zh-cn
- inno setup 脚本集
- IT服务能力成熟度模型
- PCB转原理图方法攻略
- PHP登录注册制作过程
- 硬件工程师手册_华为资料
- 神奇的-----ant的使用
- XILINXSPARTAN_start_kit_3manual.pdf
- R1762_R2632_R2700 RGNOS10.2配置指南_第一部分 基础配置指南
