腾讯TDW:大规模Hadoop集群优化与实践
80 浏览量
更新于2024-08-28
收藏 371KB PDF 举报
“腾讯大规模Hadoop集群实践,包括TDW的介绍、建设原因、优化方案以及面临的挑战。”
在腾讯的大规模Hadoop集群实践中,TDW(Tencent Distributed Data Warehouse)扮演了核心角色,它是一个基于Hadoop和Hive的分布式数据仓库系统。TDW解决了传统数据仓库扩展性和可控性的难题,特别针对腾讯的海量数据和复杂计算需求进行了定制优化。集群规模庞大,拥有超过4400台服务器,总计约10万个CPU核心,存储容量达到100PB,每天处理100多万个作业,日计算量高达4PB,同时支持2000左右的作业并发执行。
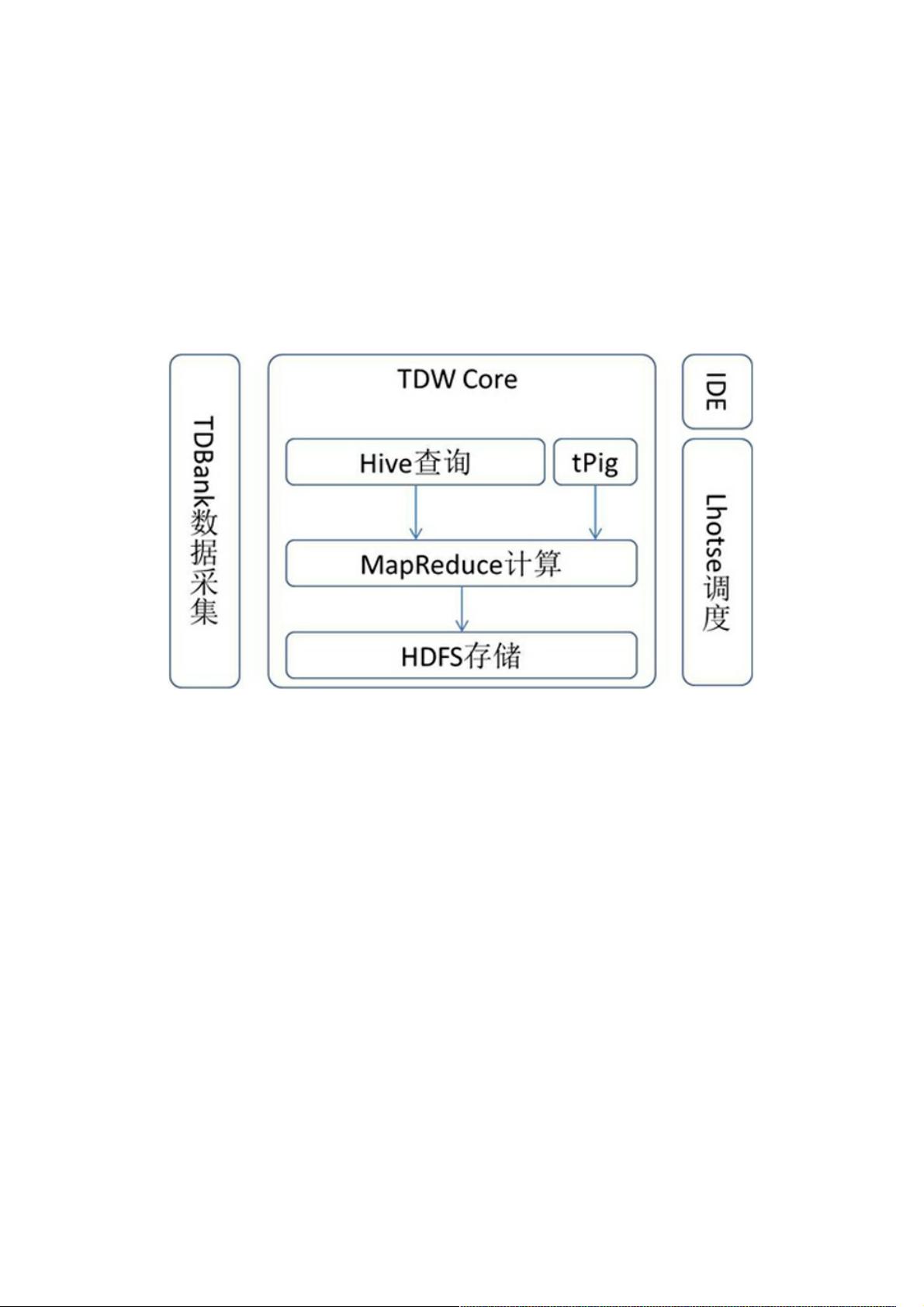
TDW由多个功能模块构成,包括Hive、MapReduce、HDFS、TDBank和Lhotse。HDFS是存储引擎,MapReduce是计算引擎,Hive则提供查询服务,TDBank负责数据的采集与接入,而Lhotse是任务调度系统,统一管理所有任务。这些模块共同协作,为腾讯的各类业务提供高效稳定的数据处理能力。
建设单个大规模Hadoop集群的主要动机有三个:首先,数据共享是关键,跨IDC或跨集群的数据访问会消耗大量网络带宽,甚至可能导致存储浪费。其次,计算资源共享能提高效率,避免某些集群资源紧张而其他集群资源闲置。最后,通过整合集群,可以减轻运营压力,降低成本,提高整体运维效率。
在面对如此大规模的集群时,TDW实施了两个关键优化策略:JobTracker的分散化和NameNode的高可用。JobTracker分散化是为了提升任务调度的效率和集群的容错能力,通过将JobTracker职责分散到多个节点,降低了单点故障的风险,同时也均衡了系统的负载。NameNode高可用则是为了保证数据存储系统的稳定性,通过设置热备NameNode,确保在主NameNode故障时能迅速切换,避免数据访问中断。
未来,腾讯将继续优化TDW,可能涉及的领域包括但不限于进一步提升集群的扩展性、提高计算效率、优化数据处理流程、增强系统监控和自动化运维能力,以及探索更先进的大数据处理技术,以应对不断增长的业务需求和数据挑战。腾讯的大规模Hadoop集群实践展现了其在大数据处理领域的领先地位和技术实力,为业界提供了宝贵的实践经验。
腾讯大规模腾讯大规模Hadoop集群实践集群实践
摘要:TDW是腾讯最大的离线数据处理平台。本文主要从需求、挑战、方案和未来计划等方面,介绍了TDW在建设单个大规
模集群中采取的JobTracker分散化和NameNode高可用两个优化方案。
TDW(Tencent distributed Data Warehouse,腾讯分布式数据仓库)基于开源软件Hadoop和Hive进行构建,打破了传统数据
仓库不能线性扩展、可控性差的局限,并且根据腾讯数据量大、计算复杂等特定情况进行了大量优化和改造。
TDW服务覆盖了腾讯绝大部分业务产品,单集群规模达到4400台,CPU总核数达到10万左右,存储容量达到100PB;每日作
业数100多万,每日计算量4PB,作业并发数2000左右;实际存储数据量80PB,文件数和块数达到6亿多;存储利用率83%左
右,CPU利用率85%左右。经过四年多的持续投入和建设,TDW已经成为腾讯最大的离线数据处理平台。
TDW的功能模块主要包括:Hive、MapReduce、HDFS、TDBank、Lhotse等,如图1所示。TDW Core主要包括存储引擎
HDFS、计算引擎MapReduce、查询引擎Hive,分别提供底层的存储、计算、查询服务,并且根据公司业务产品的应用情况
进行了很多深度订制。TDBank负责数据采集,旨在统一数据接入入口,提供多样的数据接入方式。Lhotse任务调度系统是整
个数据仓库的总管,提供一站式任务调度与管理。
图1 TDW的功能模块
建设单个大规模集群的原因
随着业务的快速增长,TDW的节点数也在增加,对单个大规模Hadoop集群的需求也越来越强烈。TDW需要做单个大规模集
群,主要是从数据共享、计算资源共享、减轻运营负担和成本等三个方面考虑。
1. 数据共享。TDW之前在多个IDC部署数十个集群,主要是根据业务分别部署,这样当一个业务需要其他业务的数据,或者
需要公共数据时,就需要跨集群或者跨IDC访问数据,这样会占用IDC之间的网络带宽。为了减少跨IDC的数据传输,有时会
将公共数据冗余分布到多个IDC的集群,这样又会带来存储空间浪费。
2. 计算资源共享。当一个集群的计算资源由于某些原因变得紧张时,例如需要数据补录时,这个集群的计算资源就捉襟见
肘,而同时,另一个集群的计算资源可能空闲,但这两者之间没有做到互通有无。
3. 减轻运营负担和成本。十几个集群同时需要稳定运营,而且当一个集群的问题解决时,也需要解决其他集群已经出现的或
者潜在的问题。一个Hadoop版本要在十几个集群逐一变更,监控系统也要在十几个集群上部署。这些都给运营带来了很大负
担。此外,分散的多个小集群,资源利用率不高,机器成本较大。
建设单个大规模集群的方案及优化
面临的挑战
TDW从单集群400台规模建设成单集群4000台规模,面临的最大挑战是Hadoop架构的单点问题:计算引擎单点JobTracker负
载重,使得调度效率低、集群扩展性不好;存储引擎单点NameNode没有容灾,使得重启耗时长、不支持灰度变更、具有丢
失数据的风险。TDW单点瓶颈导致平台的高可用性、高效性、高扩展性三方面都有所欠缺,将无法支撑4000台规模。为了解
决单点瓶颈,TDW主要进行了JobTracker分散化和NameNode高可用两方面的实施。
JobTracker分散化
1.单点JobTracker的瓶颈
TDW以前的计算引擎是传统的两层架构,单点JobTracker负责整个集群的资源管理、任务调度和任务管理,TaskTracker负责
任务执行。JobTracker的三个功能模块耦合在一起,而且全部由一个Master节点负责执行,当集群并发任务数较少时,这种
下载后可阅读完整内容,剩余4页未读,立即下载
2014-08-20 上传
2014-05-29 上传
140 浏览量
2014-05-29 上传
点击了解资源详情
点击了解资源详情
2021-02-26 上传
点击了解资源详情
点击了解资源详情

weixin_38678498
- 粉丝: 3
- 资源: 914
 我的内容管理
展开
我的内容管理
展开







最新资源
- php-microservice-cqrs-es:使用CQRS + Event SourcingPHP Microservice样板
- xMovingMap:适用于X-Plane的Android移动地图
- layout_style-it-up
- gitcommands:有用的 Git 命令
- ArpSpoof
- wetch-frontend:TFM UOC
- 毕业设计&课设-行人检测系统的MatLab代码.zip
- 睡眠教学助手:OS项目:使用互斥锁和信号灯的睡眠教学助手
- liczby_pierwsze
- Spider-Programmes:Here is a collection of my web crawler repositories.(汇聚了我的爬虫程序仓库)
- keystone:梯形飞地(QEMU + HiFive Unleashed)
- lumen-api-query-parser:基于laravel流明框架的REST-API查询解析器
- reticulate:R与Python的接口
- 客户端-服务器-聊天-对等之间:套接字编程的C#GUI应用程序,两个客户端通过同一ip和端口进行双方聊天
- LogiKM:一站式Apache Kafka集群指标监控与运维管控平台
- 毕业设计&课设-基于Matlab的物体轨迹仿真.zip
