概率隐语义分析(PLSA)深度解析与应用
需积分: 18 152 浏览量
更新于2024-09-07
1
收藏 878KB PDF 举报
"这篇文档详细介绍了PLSA(概率隐语义分析)模型,这是一种用于文本建模的生成模型,能够解决多词一义和一词多义的问题。文中还对比了生成模型和判别模型的区别,并阐述了Unigram和Mixture of Unigrams模型作为PLSA的背景知识。"
PLSA模型详解:
PLSA模型是由Hoffman在1999年提出的一种概率模型,主要用于文本挖掘和信息检索领域,目的是通过分析文档中的词汇分布来揭示隐藏的主题结构。它假设每个文档是由多个主题混合而成,每个主题又对应一个词汇分布,从而解决了单一主题模型的局限性。
1. Unigram模型:
Unigram模型是最简单的文本建模方式,它假设文档中的每个单词都是独立生成的,不考虑单词之间的关联。生成一篇文档的概率是文档中每个单词出现概率的乘积。然而,这种模型忽略了词序和上下文信息,无法表达复杂的语言结构。
2. Mixture of Unigrams模型:
为了解决Unigram模型的局限,Mixture of Unigrams引入了主题概念。每篇文档被赋予一个主题,然后根据该主题的词汇分布生成文档中的单词。这样,文档的概率是所有主题生成概率的加权和,但每篇文档只允许有一个主题,限制了模型的表达能力。
3. PLSA模型:
PLSA模型进一步扩展了Mixture of Unigrams,允许每篇文档由多个主题混合生成。在PLSA中,文档被看作是主题的混合,而主题则是一个词汇分布。模型的两个关键步骤是:
a) 首先,按照预设的文档主题分布(p(d|z))选择一个主题z;
b) 然后,根据选定主题的词汇分布(p(w|z))生成文档中的每个单词w。
整个文档集合的生成概率是所有文档概率的乘积,其中每个文档的概率是其所有主题的生成概率的加权和。这样,PLSA能够捕捉到文档中多个主题的并存,以及单词在不同主题下的不同重要性。
在实际应用中,PLSA通过最大似然估计或EM算法来估计模型参数。尽管PLSA模型有其优势,但它也有一些局限性,例如主题解释的模糊性、参数估计的困难以及无法处理主题间的依赖关系。后续的LDA(Latent Dirichlet Allocation)模型就是在PLSA的基础上改进,引入了Dirichlet先验来更好地处理这些问题。
PLSA模型是理解和分析大量文本数据的有效工具,通过揭示隐藏的主题结构,有助于信息检索、文本分类、推荐系统等多个领域的研究和应用。
PLSA 介绍与推导
概率隐语义分析(
PLSA
)是一个著名的针对文本建模的模型,是一个生成模型。因为加入了主题模型,
所以可以很大程度上改善多词一义和一词多义的问题。
数学基础:
生成模型:
预测模型的公式是
P(y|x)
,即给定输入,输出给定输入的概率分布,就要学习联合分布
P(x,y)
,
所以还要先求出
P(x)
,反应的数据本身的相似度。
这样的方法之所以称为生成方法,是因为模型表示了给
定输入
X
产生输出
Y
的生成关系。用于随机生成的观察值建模,特别是在给定某些隐藏参数情况下。典型
的生成模型有:朴素贝叶斯和隐马尔科夫模型等。(但是朴素贝叶斯没有体现词之间的关系!)
而判别模型:没有中间过程,直接对样本学习出概率
P(y|x)
,也可写作
P(y|x
;
θ),
可以理解为给定
θ
值
的情况下根据特征值来预测概率,想想
LR
就是这样的。我们只不过要先梯度下降求出
θ
罢了,如
svm
,
LR
对
于分类任务常用。
1.
生成文档(文本建模)
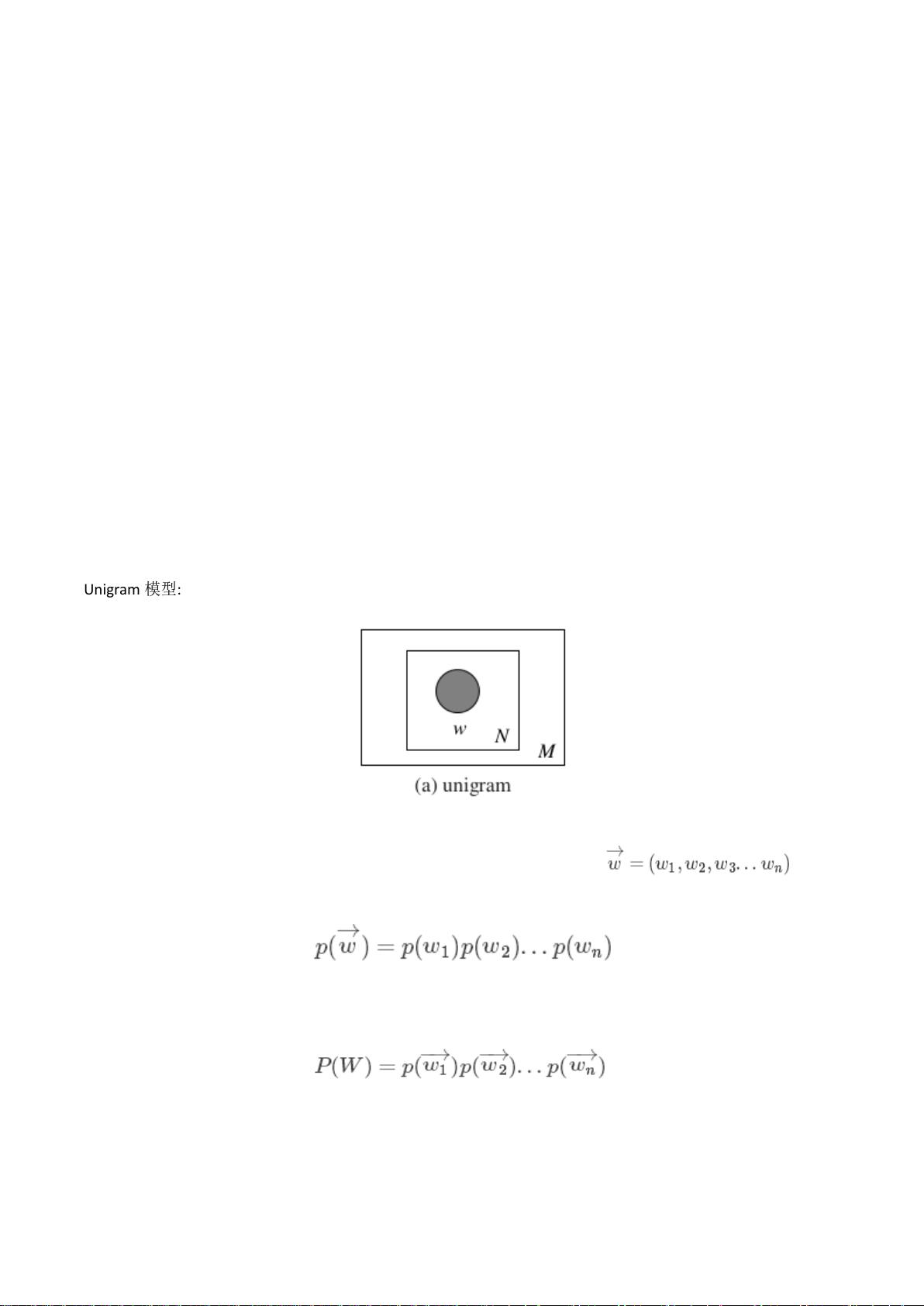
Unigram
模型
:
对于
Unigram
模型,生成一篇文档的方法就是随机的从这个词袋中抽取单词组成。而这篇文档的被生
成的概率就是被抽出每个词概率(首发球员)的乘积
。所以生成一篇文档 的概率
就是:
假设语料库中有多篇文档,而且文档与文档之间是独立的,那么整个语料库的生成概率就是就是
n
篇
文档概率之积:
这个模型里面没有主题的概念
独立语料库之间的概率都是"相乘"的关系!
下载后可阅读完整内容,剩余7页未读,立即下载
324 浏览量
422 浏览量
413 浏览量
433 浏览量
144 浏览量
346 浏览量
2016-04-28 上传
7237 浏览量
324 浏览量

xiaqian369
- 粉丝: 2
 我的内容管理
展开
我的内容管理
展开







最新资源
- 计算机组成原理期末试题及答案(2011参考)
- 均值漂移算法深入解析及实践应用
- 掌握npm与yarn在React和pg库中的使用
- C++开发学生信息管理系统实现多功能查询
- 深入解析SIMATIC NET OPC服务器与PLC的S7连接技术
- 离心式水泵原理与Matlab仿真教程
- 实现JS星级评论打分与滑动提示效果
- VB.NET图书馆管理系统源码及程序发布
- C#实现程序A监控与自动启动机制
- 构建简易Android拨号功能的应用开发教程
- HTML技术在在线杂志中的应用
- 网页开发中的实用树形菜单插件应用
- 高压水清洗技术在储罐维修中的关键应用
- 流量计校正方法及操作指南
- WinCE系统下SD卡磁盘性能测试工具及代码解析
- ASP.NET学生管理系统的源码与数据库教程
