Kafka入门教程:概念、配置与集群搭建解析
168 浏览量
更新于2024-08-27
收藏 287KB PDF 举报
"kafka入门教程,涵盖Kafka的基本概念、使用场景、设计原理、主要配置以及集群搭建步骤。"
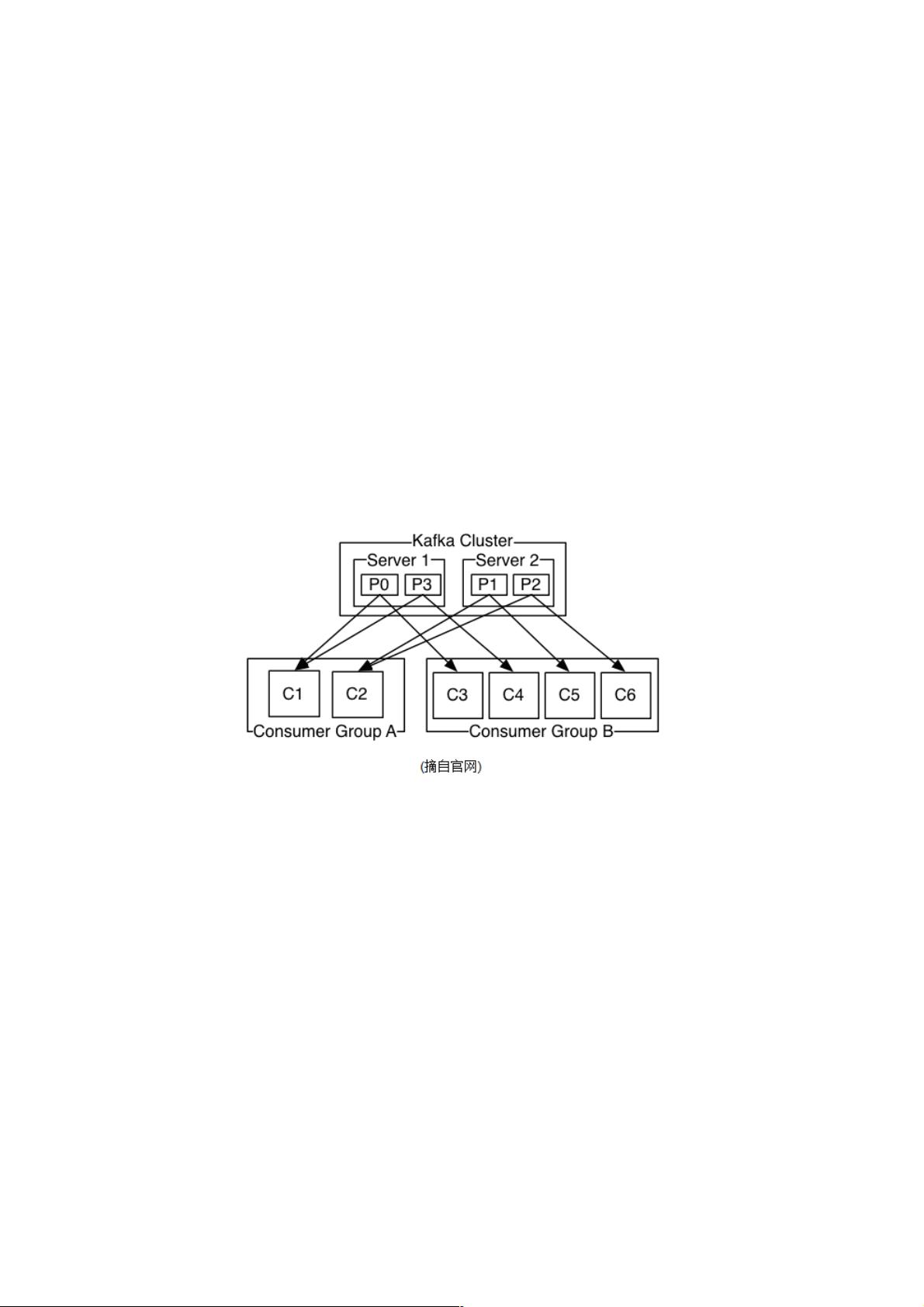
Kafka是一种分布式、分区化、复制的日志服务,它提供了类似JMS(Java Message Service)的功能,但其设计与实现方式与JMS完全不同,并不遵循JMS规范。Kafka的核心概念包括生产者(Producer)、消费者(Consumer)和主题(Topic)。生产者负责发送消息,消费者接收消息,而主题则将消息分类。每个主题可以被划分为多个分区(Partition),每个分区是一个追加操作的日志文件,消息按照到达的顺序添加到日志的末尾,并用一个全局唯一的偏移量(Offset)来标识。
Kafka集群由多个Kafka实例(Broker)组成,它们之间通过ZooKeeper协调,确保系统的高可用性和一致性。ZooKeeper用于存储元数据信息,如主题、分区和消费者组的状态等。每个分区都有一个主副本(Leader)和零个或多个从副本(Follower),保证了数据的冗余和容错能力。如果主副本故障,从副本会自动接管。
在Kafka中,消息被持久化到磁盘,并且在被消费后并不会立即删除。日志文件会根据配置保留一定时间后才被清除,这不同于JMS实现如ActiveMQ,后者通常在消息被消费后立即删除。这种设计使得Kafka可以在消息消费后释放磁盘空间,同时减少对已消费消息的修改操作,降低了磁盘I/O。
消费者通过保存并更新自己的消费偏移量(Offset)来跟踪消息的消费进度。消费者可以自由选择消息的消费顺序,只需调整Offset即可。消费偏移量通常保存在ZooKeeper中,这样即使消费者宕机,重启后也能恢复到之前的状态,继续消费消息。
配置方面,Kafka允许用户定制各种参数,如每个分区的副本数量、消息保留时间、清理策略等。集群搭建涉及安装Kafka和ZooKeeper,配置服务器之间的通信,创建主题以及设置消费者和生产者的连接参数。
Kafka适用于大数据流处理、实时日志收集、网站活动追踪等多种场景。它的高性能、可扩展性和低延迟特性使其成为大规模分布式环境下的理想消息中间件。通过理解Kafka的基本原理和配置,开发者能够有效地利用Kafka构建高效的消息传递系统。
种压缩方式.
3、生产者
负载均衡: producer将会和Topic下所有partition leader保持socket连接;消息由producer直接通过socket发送到broker,中间不会
经过任何"路由层".事实上,消息被路由到哪个partition上,有producer客户端决定.比如可以采用"random""key-hash""轮询"等,如
果一个topic中有多个partitions,那么在producer端实现"消息均衡分发"是必要的.
其中partition leader的位置(host:port)注册在zookeeper中,producer作为zookeeper client,已经注册了watch用来监听partition
leader的变更事件.
异步发送:将多条消息暂且在客户端buffer起来,并将他们批量的发送到broker,小数据IO太多,会拖慢整体的网络延迟,批
量延迟发送事实上提升了网络效率。不过这也有一定的隐患,比如说当producer失效时,那些尚未发送的消息将会丢失。
4、消费者
consumer端向broker发送"fetch"请求,并告知其获取消息的offset;此后consumer将会获得一定条数的消息;consumer端也可以
重置offset来重新消费消息.
在JMS实现中,Topic模型基于push方式,即broker将消息推送给consumer端.不过在kafka中,采用了pull方式,即consumer在和
broker建立连接之后,主动去pull(或者说fetch)消息;这中模式有些优点,首先consumer端可以根据自己的消费能力适时的去fetch
消息并处理,且可以控制消息消费的进度(offset);此外,消费者可以良好的控制消息消费的数量,batch fetch.
其他JMS实现,消息消费的位置是有prodiver保留,以便避免重复发送消息或者将没有消费成功的消息重发等,同时还要控制消息
的状态.这就要求JMS broker需要太多额外的工作.在kafka中,partition中的消息只有一个consumer在消费,且不存在消息状态的
控制,也没有复杂的消息确认机制,可见kafka broker端是相当轻量级的.当消息被consumer接收之后,consumer可以在本地保存
最后消息的offset,并间歇性的向zookeeper注册offset.由此可见,consumer客户端也很轻量级.
5、消息传送机制
对于JMS实现,消息传输担保非常直接:有且只有一次(exactly once).在kafka中稍有不同:
1) at most once: 最多一次,这个和JMS中"非持久化"消息类似.发送一次,无论成败,将不会重发.
2) at least once: 消息至少发送一次,如果消息未能接受成功,可能会重发,直到接收成功.
3) exactly once: 消息只会发送一次.
at most once: 消费者fetch消息,然后保存offset,然后处理消息;当client保存offset之后,但是在消息处理过程中出现了异常,导致部
分消息未能继续处理.那么此后"未处理"的消息将不能被fetch到,这就是"at most once".
at least once: 消费者fetch消息,然后处理消息,然后保存offset.如果消息处理成功之后,但是在保存offset阶段zookeeper异常导致
保存操作未能执行成功,这就导致接下来再次fetch时可能获得上次已经处理过的消息,这就是"at least once",原因offset没有及
时的提交给zookeeper,zookeeper恢复正常还是之前offset状态.
exactly once: kafka中并没有严格的去实现(基于2阶段提交,事务),我们认为这种策略在kafka中是没有必要的.
通常情况下"at-least-once"是我们搜选.(相比at most once而言,重复接收数据总比丢失数据要好).
6、复制备份
kafka将每个partition数据复制到多个server上,任何一个partition有一个leader和多个follower(可以没有);备份的个数可以通过
broker配置文件来设定.leader处理所有的read-write请求,follower需要和leader保持同步.Follower和consumer一样,消费消息并
保存在本地日志中;leader负责跟踪所有的follower状态,如果follower"落后"太多或者失效,leader将会把它从replicas同步列表中
删除.当所有的follower都将一条消息保存成功,此消息才被认为是"committed",那么此时consumer才能消费它.即使只有一个
replicas实例存活,仍然可以保证消息的正常发送和接收,只要zookeeper集群存活即可.(不同于其他分布式存储,比如hbase需
剩余10页未读,继续阅读
2018-07-27 上传
2017-02-07 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情
2018-03-06 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情

weixin_38746515
- 粉丝: 15
- 资源: 944
 我的内容管理
展开
我的内容管理
展开







最新资源
- 常用算法设计 强烈推荐
- Ant使用指南(不管你用没用过看了以后都有收益)
- 好的论文 洗衣机控制器
- cmd 命令大全 初学者
- 网络管理员----电子教程
- 计算机专科专业英语试卷
- head first c# 第二章(中文版)
- I2C总线规范(中文)
- 附录6-TurboC常用库函数.doc
- 无线传感器网络自组网协议的实现方法.pdf
- 无线Adhoc网络中QoS路由协议的研究.pdf
- 无线Adhoc网络MAC层吞吐量分析.pdf
- 双重认证Adhoc网络安全路由协议设计.pdf
- 基于多维Hash链的无线Ad_hoc安全路由数字签名方案.pdf
- 基于AdHoc的网络管理的研究与实现.pdf
- Linux内核源码情景分析.pdf
