Kafka入门:架构、功能与集群配置详解
57 浏览量
更新于2024-08-29
收藏 280KB PDF 举报
Kafka入门指南深入探讨了这个分布式、分区和复制的日志服务的基本概念。首先,Kafka作为一款消息队列系统,不同于传统的JMS解决方案,如ActiveMQ,它的设计思想独特,不遵循JMS规范。Kafka的核心概念包括:
1. **简介**:
- Kafka是一个分布式系统,通过将消息分发到多个分区(partitions)来处理高吞吐量和容错性。每个分区都有自己的持久化日志,每个消息都有唯一的偏移量(offset)进行标识。
- 发送消息者称为生产者(Producer),接收消息者称为消费者(Consumer)。它们都需要Zookeeper来协调和维护元数据,确保系统的可用性和一致性。
2. **Topics与Logs**:
- Topics是消息的分类,类似主题,每个主题下可以有多个分区。消息按照主题发送,并且以顺序追加的方式写入对应的分区日志文件。
- Kafka强调消息的持久性,即使消息被消费,也不立即从日志中删除,而是根据broker配置保留一段时间,例如2天。这有助于磁盘空间管理,避免频繁的磁盘I/O操作。
- 消费者负责管理消息消费的offset,可以选择顺序消费或指定offset位置重新开始消费。这些offset信息通常保存在Zookeeper中,便于管理和维护。
3. **依赖与架构**:
- Kafka的集群由多个实例(broker)组成,这些实例通过Zookeeper进行元数据同步,如分区分配、消费者组管理等,从而确保服务的可靠性和扩展性。
- 生产者和消费者的客户端并不直接维护状态信息,这些信息全部由Zookeeper管理,简化了系统的复杂性。
Kafka以其高效、可扩展的特性在大数据处理和实时流处理领域广泛应用。理解和掌握其核心概念、设计原理以及配置和集群搭建是使用Kafka的基础。对于实际应用来说,熟练配置参数、监控性能以及故障恢复策略都是非常重要的环节。
kafka入门:简介、使用场景、设计原理、主要配置及集群搭入门:简介、使用场景、设计原理、主要配置及集群搭
建建
一、入门
1、简介
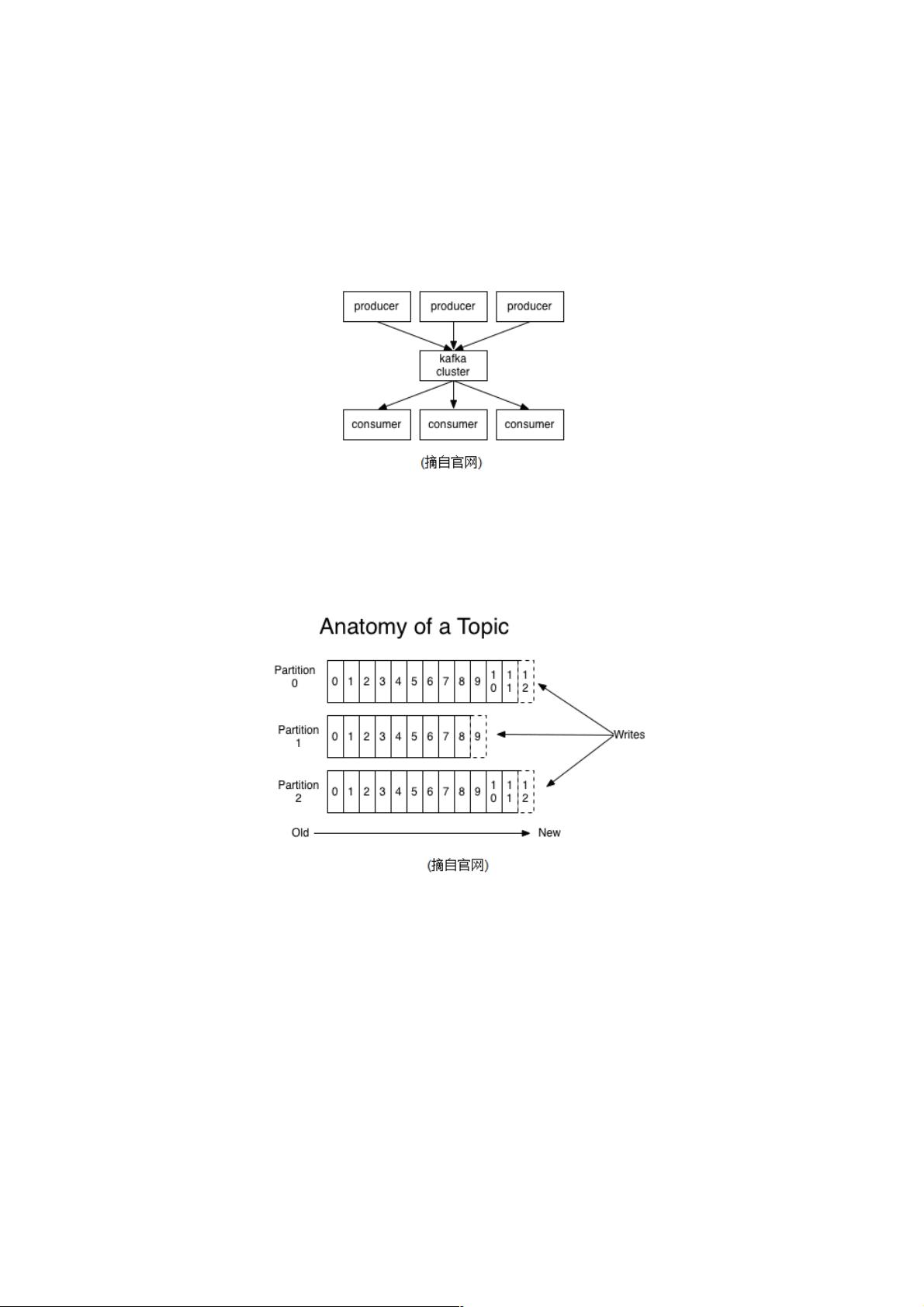
Kafka is a distributed,partitioned,replicated commit logservice。它提供了类似于JMS的特性,但是在设计实现上完全不同,
此外它并不是JMS规范的实现。kafka对消息保存时根据Topic进行归类,发送消息者成为Producer,消息接受者成为Consumer,
此外kafka集群有多个kafka实例组成,每个实例(server)成为broker。无论是kafka集群,还是producer和consumer都依赖于
zookeeper来保证系统可用性集群保存一些meta信息。
2、Topics/logs
一个Topic可以认为是一类消息,每个topic将被分成多个partition(区),每个partition在存储层面是append log文件。任何发布到
此partition的消息都会被直接追加到log文件的尾部,每条消息在文件中的位置称为offset(偏移量),offset为一个long型数
字,它是唯一标记一条消息。它唯一的标记一条消息。kafka并没有提供其他额外的索引机制来存储offset,因为在kafka中几
乎不允许对消息进行“随机读写”。
kafka和JMS(Java Message Service)实现(activeMQ)不同的是:即使消息被消费,消息仍然不会被立即删除.日志文件将会根
据broker中的配置要求,保留一定的时间之后删除;比如log文件保留2天,那么两天后,文件会被清除,无论其中的消息是否被消
费.kafka通过这种简单的手段,来释放磁盘空间,以及减少消息消费之后对文件内容改动的磁盘IO开支.
对于consumer而言,它需要保存消费消息的offset,对于offset的保存和使用,有consumer来控制;当consumer正常消费消息
时,offset将会"线性"的向前驱动,即消息将依次顺序被消费.事实上consumer可以使用任意顺序消费消息,它只需要将offset重置
为任意值..(offset将会保存在zookeeper中,参见下文)
kafka集群几乎不需要维护任何consumer和producer状态信息,这些信息有zookeeper保存;因此producer和consumer的客户端
实现非常轻量级,它们可以随意离开,而不会对集群造成额外的影响.
partitions的设计目的有多个.最根本原因是kafka基于文件存储.通过分区,可以将日志内容分散到多个server上,来避免文件尺寸
达到单机磁盘的上限,每个partiton都会被当前server(kafka实例)保存;可以将一个topic切分多任意多个partitions,来消息保存/消
费的效率.此外越多的partitions意味着可以容纳更多的consumer,有效提升并发消费的能力.(具体原理参见下文).
3、Distribution
一个Topic的多个partitions,被分布在kafka集群中的多个server上;每个server(kafka实例)负责partitions中消息的读写操作;此外
kafka还可以配置partitions需要备份的个数(replicas),每个partition将会被备份到多台机器上,以提高可用性.
基于replicated方案,那么就意味着需要对多个备份进行调度;每个partition都有一个server为"leader";leader负责所有的读写操作,
下载后可阅读完整内容,剩余8页未读,立即下载
点击了解资源详情
点击了解资源详情
点击了解资源详情
2017-02-07 上传
2018-03-06 上传
2018-07-27 上传
2023-08-06 上传
点击了解资源详情
点击了解资源详情

weixin_38746442
- 粉丝: 8
- 资源: 960
 我的内容管理
展开
我的内容管理
展开







最新资源
- MATLAB实现小波阈值去噪:Visushrink硬软算法对比
- 易语言实现画板图像缩放功能教程
- 大模型推荐系统: 优化算法与模型压缩技术
- Stancy: 静态文件驱动的简单RESTful API与前端框架集成
- 掌握Java全文搜索:深入Apache Lucene开源系统
- 19计应19田超的Python7-1试题整理
- 易语言实现多线程网络时间同步源码解析
- 人工智能大模型学习与实践指南
- 掌握Markdown:从基础到高级技巧解析
- JS-PizzaStore: JS应用程序模拟披萨递送服务
- CAMV开源XML编辑器:编辑、验证、设计及架构工具集
- 医学免疫学情景化自动生成考题系统
- 易语言实现多语言界面编程教程
- MATLAB实现16种回归算法在数据挖掘中的应用
- ***内容构建指南:深入HTML与LaTeX
- Python实现维基百科“历史上的今天”数据抓取教程
