Python与Sklearn的机器学习实战:从线性模型到决策树
需积分: 9 9 浏览量
更新于2024-07-19
收藏 2.43MB DOC 举报
"该文档详细介绍了使用Python和Scikit-learn(Sklearn)库进行机器学习的基本概念和方法,涵盖了从线性模型到决策树、再到最邻近算法等多个方面。"
在机器学习领域,Python与Scikit-learn库是进行数据分析和建模的常用工具。文档首先讲解了广义线性模型,包括普通最小二乘法(Ordinary Least Squares, OLS)的原理和应用。线性回归是一种基本的预测模型,用于拟合数据点,找到最佳直线关系。文档中通过实例展示了如何使用Scikit-learn实现线性回归,并分析了其计算复杂度。
接下来,文档转向逻辑回归,这是一种二分类模型,常用于预测事件发生的概率。正则化是防止过拟合的重要手段,文档提到了岭回归(Ridge Regression),并展示了如何通过调整正则化参数来控制模型复杂度。此外,还介绍了广义交叉验证(Generalized Cross-Validation)这一选择正则化参数的方法。
文档还涉及了Lasso回归,它能自动进行特征选择,适用于处理稀疏信号。Lasso与弹性网络(Elastic Net)是两种常用的正则化技术,它们在压缩感知中的应用,如基于L1正则化的断层重建,也有所提及。
在模型选择部分,文档讨论了多任务Lasso,这是一种能同时优化多个相关任务的正则化方法,适合处理有多个目标变量的问题。
决策树(Decision Trees)是另一种常见的学习模型,用于分类和回归任务。文档展示了在鸢尾花数据集上如何构建和可视化决策树的决策边界,这有助于理解模型的决策过程。
最后,文档探讨了最邻近算法(Nearest Neighbors),包括无监督的邻近邻居寻找方法,以及如何利用KDTree和BallTree数据结构提高效率。此外,还详细介绍了最近邻算法在分类(KNN)和回归任务中的应用。
这份文档提供了一个全面的入门指南,涵盖了Python和Scikit-learn库在机器学习中的基本操作,包括线性模型、逻辑回归、正则化、决策树和最邻近算法等核心概念,对于初学者来说是极好的学习资源。
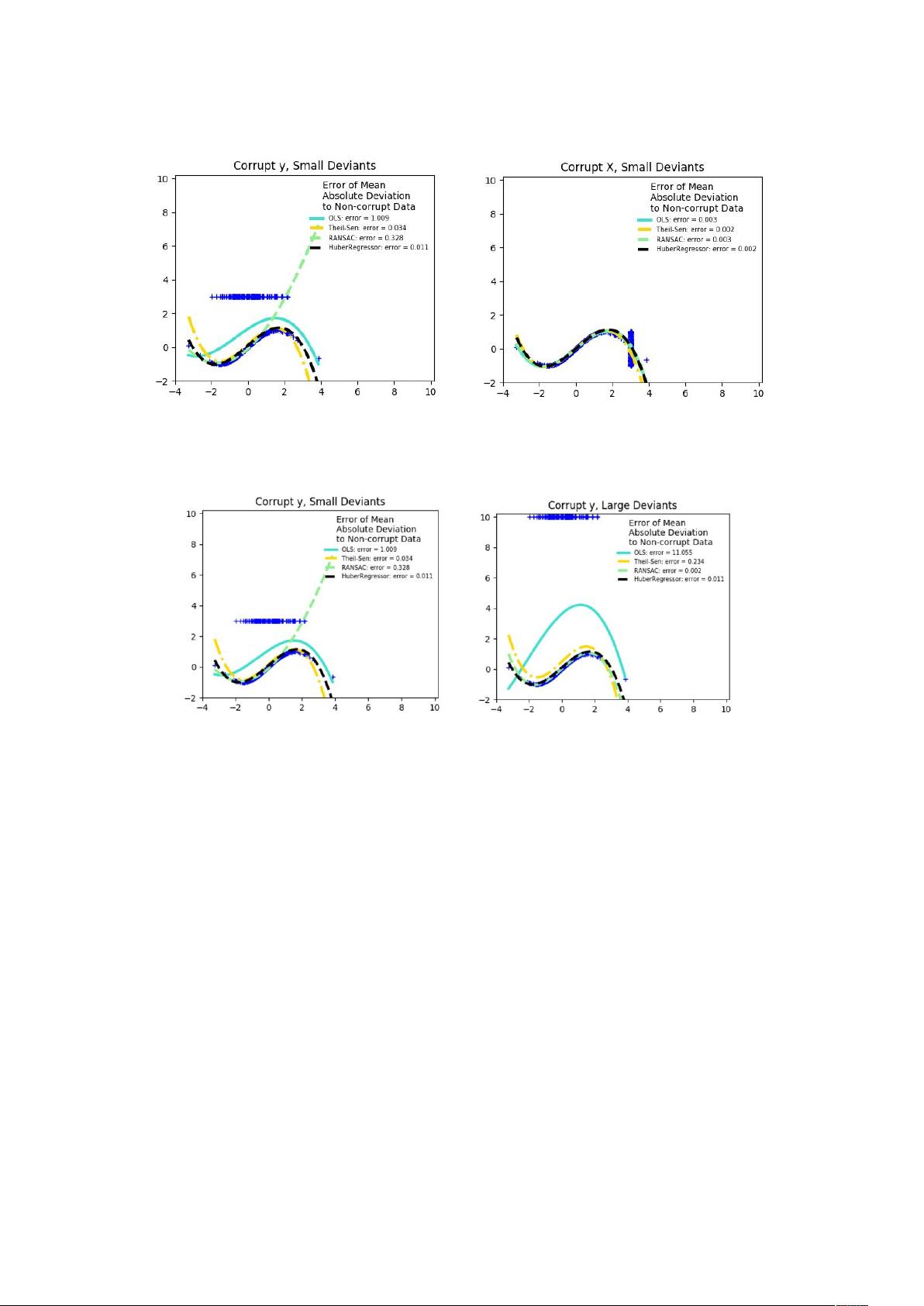
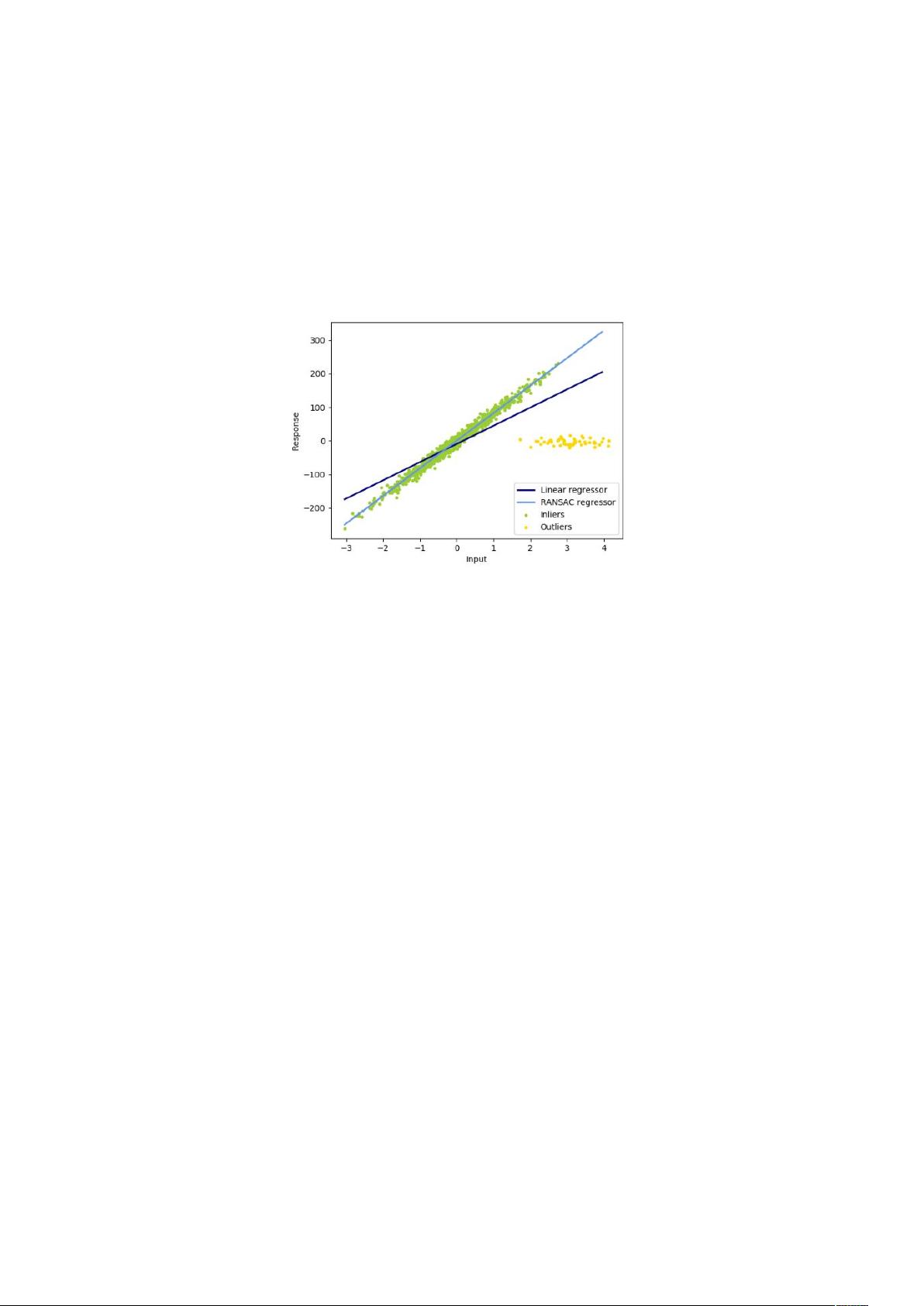
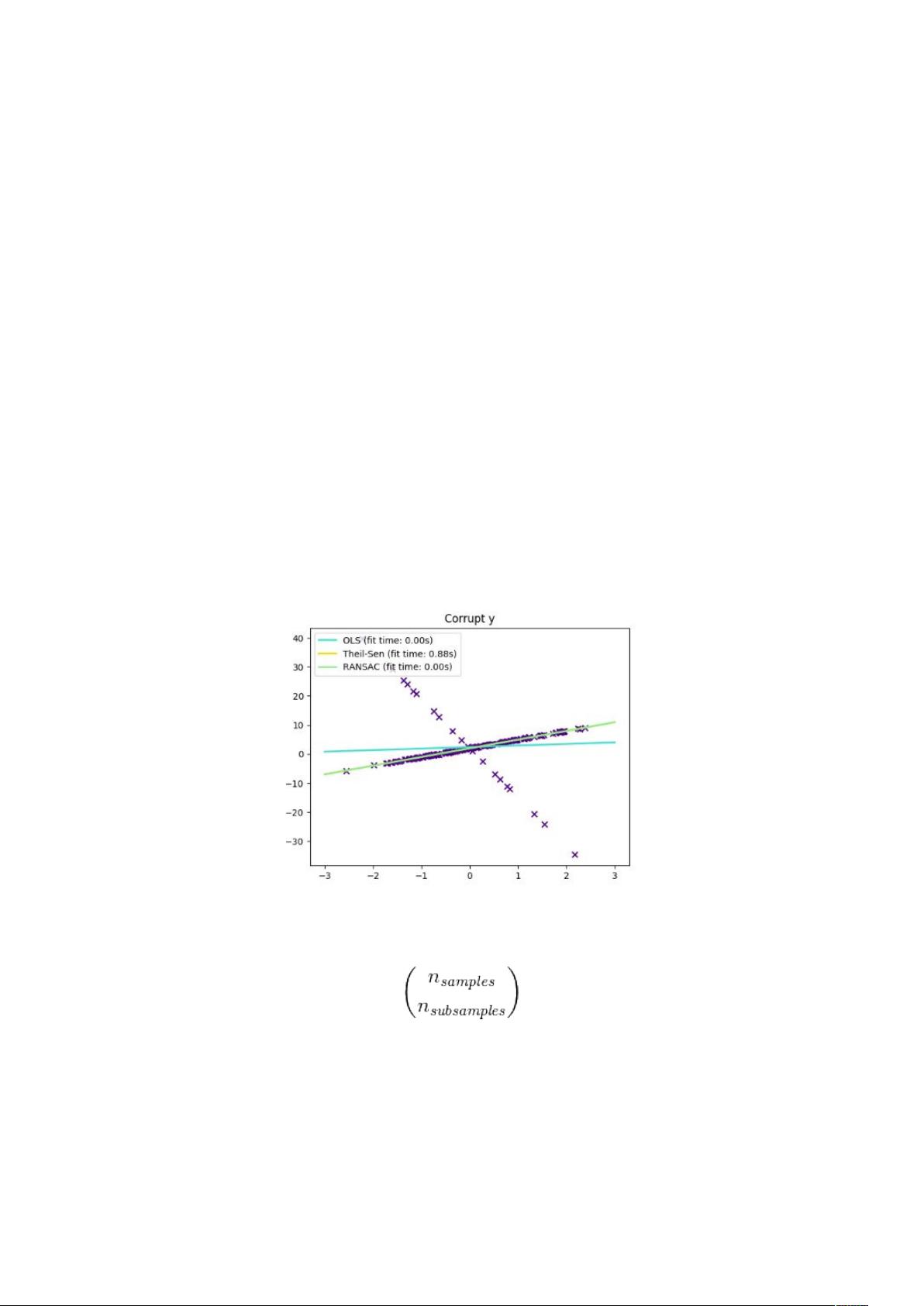
异常值在 方向 异常值在 方向
异常值与误差幅度的分数
离岸点的数量很重要,但也是离群点多少。
小异常值 大异常值
稳健拟合的一个重要概念就是分解点:可以离开的数据的分数,以适合开始丢
失内部数据。
注意,一般来说,在高维度设置(大 )中的鲁棒拟合非常困难。
这里的健壮模型可能无法在这些设置中使用。
权衡:哪个估计?
# 学习提供了 = 个鲁棒的回归估计:-,-!,8; 和
F &
F & 应该比 -,-! 和 8; 更快,除非样本数量非常大,
即 GG 。这是因为 -,-! 和 8; 适合较小
的数据子集。不过,8; 和 -,-! 都不太可能像 F &
一样强大的默认参数。
-,-! 比 8; 快,随着样品数量的增加而增加
-,-! 将在 方向处理更大的异常值(最常见的情况)
8; 将在 方向处理中等大小的异常值,但是这个属性将在大尺寸设置
中消失。
如有疑问,请使用 -,-!
2%。 -,-!:-,-!
剩余45页未读,继续阅读
2015-05-31 上传
2023-06-11 上传
2023-06-14 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情

阿卡蒂奥
- 粉丝: 1025
- 资源: 38
 我的内容管理
展开
我的内容管理
展开







最新资源
- 前端面试必问:真实项目经验大揭秘
- 永磁同步电机二阶自抗扰神经网络控制技术与实践
- 基于HAL库的LoRa通讯与SHT30温湿度测量项目
- avaWeb-mast推荐系统开发实战指南
- 慧鱼SolidWorks零件模型库:设计与创新的强大工具
- MATLAB实现稀疏傅里叶变换(SFFT)代码及测试
- ChatGPT联网模式亮相,体验智能压缩技术.zip
- 掌握进程保护的HOOK API技术
- 基于.Net的日用品网站开发:设计、实现与分析
- MyBatis-Spring 1.3.2版本下载指南
- 开源全能媒体播放器:小戴媒体播放器2 5.1-3
- 华为eNSP参考文档:DHCP与VRP操作指南
- SpringMyBatis实现疫苗接种预约系统
- VHDL实现倒车雷达系统源码免费提供
- 掌握软件测评师考试要点:历年真题解析
- 轻松下载微信视频号内容的新工具介绍
