SparkStreaming:大数据流处理技术解析与应用
100 浏览量
更新于2024-08-28
1
收藏 346KB PDF 举报
"SparkStreaming在大数据处理中的应用与优化"
SparkStreaming是大数据处理领域的一个重要工具,它被设计用于大规模流式数据的实时处理。作为BDAS(Berkeley Data Analytics Stack)的一部分,SparkStreaming旨在解决传统大数据处理框架在处理不同类型任务时的不便,如批量处理、交互式查询和流式处理。通过将流式计算拆分成一系列微小的批处理任务,SparkStreaming能够快速响应实时数据流,提供低延迟的数据处理能力。
SparkStreaming的架构设计巧妙地融合了批处理和流处理的优点。它基于核心的Spark引擎,利用Spark的DAG执行模型和内存计算,显著提升了处理速度。当数据流到达时,SparkStreaming会将数据分成连续的小时间窗口(例如,每秒或每分钟一个窗口),然后将每个窗口内的数据作为一个小批处理作业进行处理。这种微批处理的方式使得SparkStreaming能快速响应,并且易于与其他Spark组件(如Spark SQL和MLlib)集成,实现数据处理的全栈解决方案。
在编程模型上,SparkStreaming提供了简单易用的API,如Discretized Streams (DStreams)。DStreams是SparkStreaming对持续数据流的抽象,它由一系列连续的RDD(弹性分布式数据集)组成,开发者可以通过操作DStreams进行数据处理。这种API设计使得开发者能够轻松地编写复杂的流处理逻辑,而无需关心底层的实现细节。
在实际应用中,SparkStreaming广泛应用于各种场景,如社交媒体分析、网络日志处理、实时交易监控等。例如,通过对实时的社交媒体数据流进行处理,可以迅速分析用户情绪,为企业决策提供及时信息。此外,SparkStreaming还支持多种数据源,如Kafka、Flume、Twitter等,方便接入不同类型的实时数据流。
为了提升性能和效率,SparkStreaming提供了一系列优化策略。例如,通过调整窗口大小和滑动间隔,可以平衡延迟和精度的需求。另外,使用checkpointing来实现容错,确保系统的高可用性。同时,还可以结合Spark的动态资源调度,根据数据量和系统负载自动调整计算资源。
在BDAS框架下,SparkStreaming与Spark SQL和Spark MLlib等组件协同工作,形成了一套全面的大数据分析解决方案。它可以无缝处理批处理、交互式查询和流处理任务,减少了系统间的转换开销,降低了运维成本。此外,由于SparkStreaming支持YARN和Mesos等集群管理器,因此可以在不同环境灵活部署,适应不同的业务需求。
总结来说,SparkStreaming以其高效的微批处理模型、强大的编程接口和灵活的部署选项,成为了大规模流式数据处理的首选工具。通过理解和掌握SparkStreaming的核心原理和最佳实践,开发者可以构建出能够处理海量实时数据的高性能应用,从而在大数据时代抢占先机。
SparkStreaming:大规模流式数据处理的新贵:大规模流式数据处理的新贵
Spark Streaming是大规模流式数据处理的新贵,将流式计算分解成一系列短小的批处理作业。本文阐释了Spark Streaming的
架构及编程模型,并结合实践对其核心技术进行了深入的剖析,给出了具体的应用场景及优化方案。
提到Spark Streaming,我们不得不说一下BDAS(Berkeley Data Analytics Stack),这个伯克利大学提出的关于数据分析的
软件栈。从它的视角来看,目前的大数据处理可以分为如以下三个类型。
1.复杂的批量数据处理(batch data processing),通常的时间跨度在数十分钟到数小时之间。
2.基于历史数据的交互式查询(interactive query),通常的时间跨度在数十秒到数分钟之间。
3.基于实时数据流的数据处理(streaming data processing),通常的时间跨度在数百毫秒到数秒之间。
目前已有很多相对成熟的开源软件来处理以上三种情景,我们可以利用MapReduce来进行批量数据处理,可以用Impala来进
行交互式查询,对于流式数据处理,我们可以采用Storm。对于大多数互联网公司来说,一般都会同时遇到以上三种情景,那
么在使用的过程中这些公司可能会遇到如下的不便。
1.三种情景的输入输出数据无法无缝共享,需要进行格式相互转换。
2.每一个开源软件都需要一个开发和维护团队,提高了成本。
3.在同一个集群中对各个系统协调资源分配比较困难。
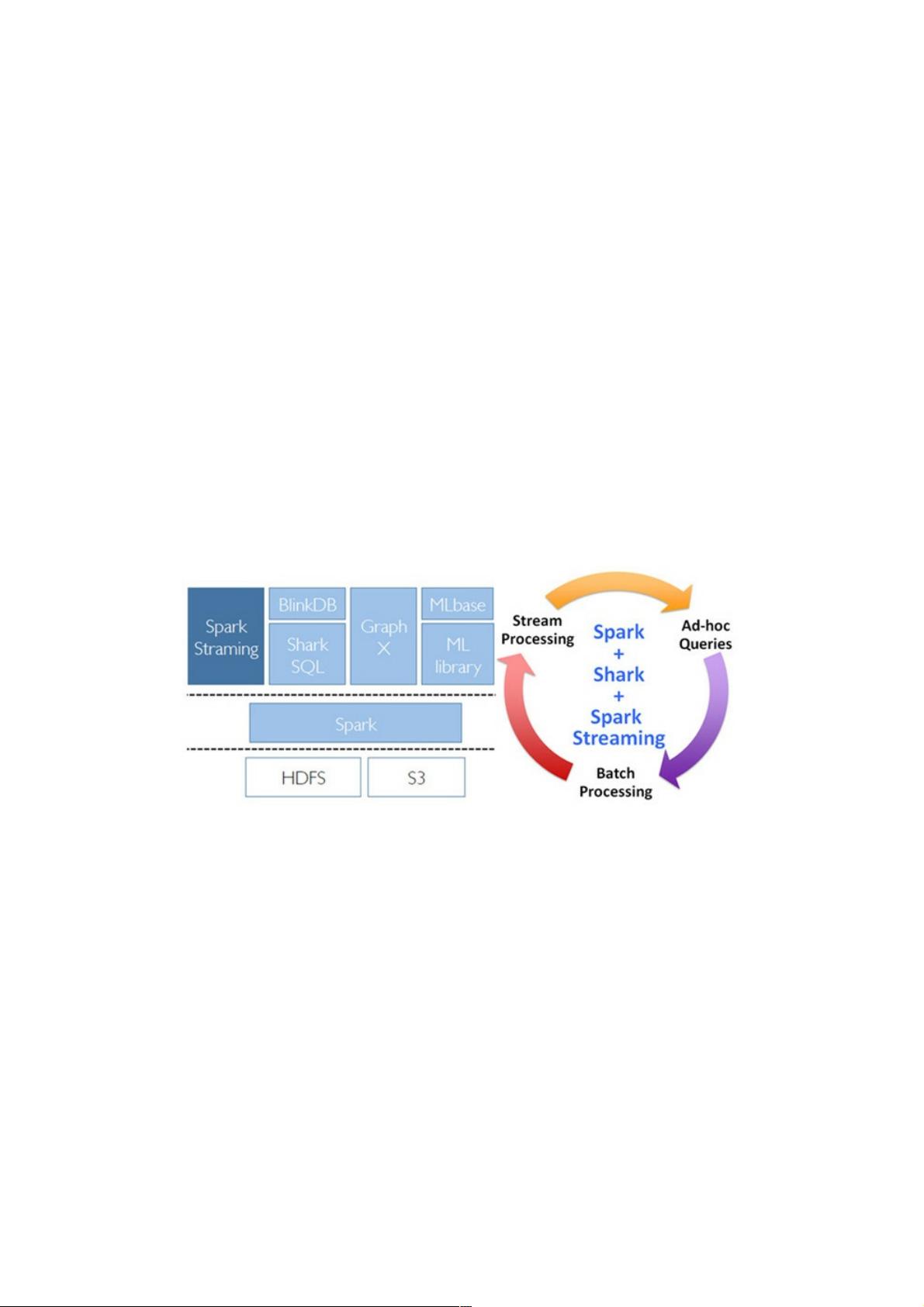
BDAS就是以Spark为基础的一套软件栈,利用基于内存的通用计算模型将以上三种情景一网打尽,同时支持Batch、
Interactive、Streaming的处理,且兼容支持HDFS和S3等分布式文件系统,可以部署在YARN和Mesos等流行的集群资源管理
器之上。BDAS的构架如图1所示,其中Spark可以替代MapReduce进行批处理,利用其基于内存的特点,特别擅长迭代式和
交互式数据处理;Shark处理大规模数据的SQL查询,兼容Hive的HQL。本文要重点介绍的Spark Streaming,在整个BDAS中
进行大规模流式处理。
图1 BDAS软件栈
Spark Streaming构架
计算流程:Spark Streaming是将流式计算分解成一系列短小的批处理作业。这里的批处理引擎是Spark,也就是把Spark
Streaming的输入数据按照batch size(如1秒)分成一段一段的数据(Discretized Stream),每一段数据都转换成Spark中的
RDD(Resilient Distributed Dataset),然后将Spark Streaming中对DStream的Transformation操作变为针对Spark中对RDD
的Transformation操作,将RDD经过操作变成中间结果保存在内存中。整个流式计算根据业务的需求可以对中间的结果进行叠
加,或者存储到外部设备。图2显示了Spark Streaming的整个流程。
下载后可阅读完整内容,剩余4页未读,立即下载
2023-09-26 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情

weixin_38529951
- 粉丝: 6
- 资源: 881
 我的内容管理
展开
我的内容管理
展开







最新资源
- Java毕业设计项目:校园二手交易网站开发指南
- Blaseball Plus插件开发与构建教程
- Deno Express:模仿Node.js Express的Deno Web服务器解决方案
- coc-snippets: 强化coc.nvim代码片段体验
- Java面向对象编程语言特性解析与学生信息管理系统开发
- 掌握Java实现硬盘链接技术:LinkDisks深度解析
- 基于Springboot和Vue的Java网盘系统开发
- jMonkeyEngine3 SDK:Netbeans集成的3D应用开发利器
- Python家庭作业指南与实践技巧
- Java企业级Web项目实践指南
- Eureka注册中心与Go客户端使用指南
- TsinghuaNet客户端:跨平台校园网联网解决方案
- 掌握lazycsv:C++中高效解析CSV文件的单头库
- FSDAF遥感影像时空融合python实现教程
- Envato Markets分析工具扩展:监控销售与评论
- Kotlin实现NumPy绑定:提升数组数据处理性能
