支持向量机(SVM)基础与理论解析
"支持向量机(SVM)是一种监督学习模型,主要用于分类和回归分析。在本PPT中,它详细介绍了SVM的基本概念、应用以及如何通过优化找到最佳分类边界。"
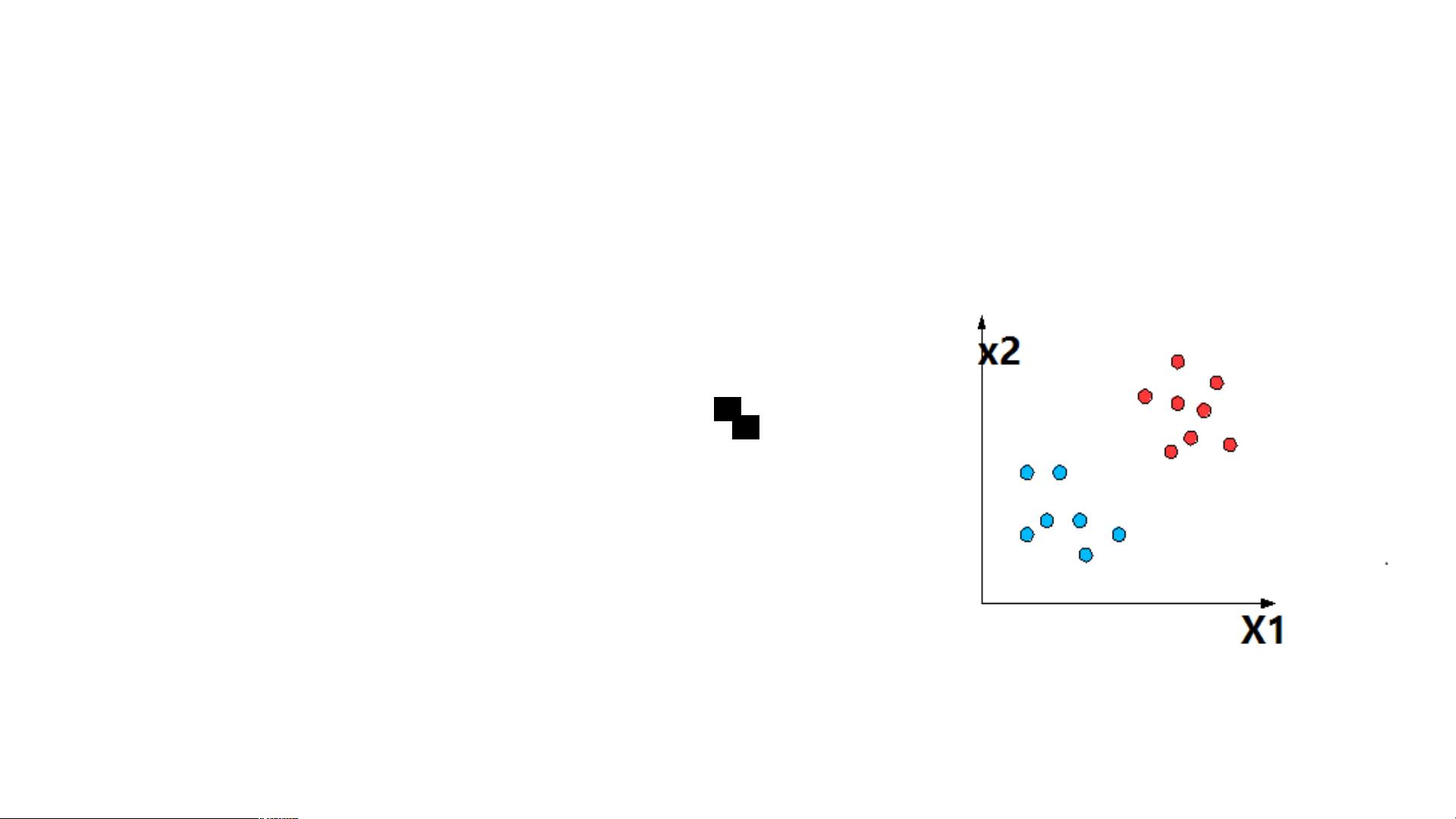
支持向量机(SVM)的核心是解决分类问题,特别是那些可以通过超平面进行划分的数据集。在SVM中,超平面被定义为距离各类别最近的样本点(支持向量)具有最大间隔的边界。这个间隔最大化的原则确保了模型对新样本的泛化能力,因为分类器试图找到一个能够最好地区分两类样本的决策边界。
SVM首先从一个线性分类问题开始,假设数据可以由一条直线完美划分。这条直线可以用方程Z = aX1 + bX2表示,其中a和b是待确定的参数。寻找最优分类器的问题转化为寻找使得所有样本点都正确分类,并且间隔最大的a和b值。这可以通过最大化似然函数和利用最大似然估计来实现。
在二维空间中,当决策边界Y = 0时,即h(z) = 0.5,这意味着落在该边界上的样本有50%的概率属于任一类。在预测阶段,SVM会根据新样本点与超平面的距离(函数间隔γ)来决定其所属类别。
然而,当数据不是线性可分时,SVM引入了核函数的概念。核函数能够将原始特征空间映射到一个高维空间,在那里原本非线性的数据可能变得线性可分。通过这种方式,SVM能够在保持分类性能的同时处理非线性问题。
为了找到最优的超平面,SVM采用拉格朗日乘子法来处理等式约束,构建拉格朗日函数,并解决由此产生的对偶问题。对偶问题的解不仅提供了分类权重,还揭示了哪些训练样本(支持向量)对构建决策边界最重要。这些支持向量是离决策边界最近的样本点,它们决定了超平面的位置。
总结来说,SVM是一种强大的机器学习工具,尤其适用于小样本和高维数据集。它的关键优势在于能够找到最优分类边界,通过核函数处理非线性问题,并且仅依赖于少数关键样本(支持向量)进行决策,这有助于减少过拟合的风险。SVM的应用广泛,包括图像分类、文本分类、生物信息学等领域。
怎么分类?
•
回顾 logisc Regression
•
是一个分类问题
•
已知
•
训练集中有 15 个样本
•
每个样本的 X1 , X2 , y 的值
•
可以被一条直线分割
•
直线可以表示为 Z = aX1 + bX2
•
未知
•
a
•
b
剩余16页未读,继续阅读
2009-09-15 上传
2011-05-21 上传
2023-11-21 上传
2023-03-29 上传
2024-03-26 上传
2024-04-06 上传
2023-11-27 上传
2023-09-09 上传

公良将
- 粉丝: 2
- 资源: 9
 我的内容管理
展开
我的内容管理
展开







最新资源
- C语言快速排序算法的实现与应用
- KityFormula 编辑器压缩包功能解析
- 离线搭建Kubernetes 1.17.0集群教程与资源包分享
- Java毕业设计教学平台完整教程与源码
- 综合数据集汇总:浏览记录与市场研究分析
- STM32智能家居控制系统:创新设计与无线通讯
- 深入浅出C++20标准:四大新特性解析
- Real-ESRGAN: 开源项目提升图像超分辨率技术
- 植物大战僵尸杂交版v2.0.88:新元素新挑战
- 掌握数据分析核心模型,预测未来不是梦
- Android平台蓝牙HC-06/08模块数据交互技巧
- Python源码分享:计算100至200之间的所有素数
- 免费视频修复利器:Digital Video Repair
- Chrome浏览器新版本Adblock Plus插件发布
- GifSplitter:Linux下GIF转BMP的核心工具
- Vue.js开发教程:全面学习资源指南
