Elasticsearch 2.x权威指南:从入门到深度实践
需积分: 9 115 浏览量
更新于2024-07-21
收藏 3.65MB PDF 举报
《Elasticsearch权威指南2.x版本》是一本详尽的文档,专为IT专业人士设计,深入介绍了Elasticsearch这款强大的分布式搜索引擎。该书旨在帮助读者理解、安装、配置和操作Elasticsearch,以便在实际项目中高效利用其功能。
首先,本书以引言和前言为引导,介绍了作者写作这本书的初衷和目标读者群体——那些寻求在大数据处理和实时分析场景下提升搜索性能的专业人士。书中特别关注了2.x版本,确保内容与当时的最新技术保持同步。
"Getting Started"章节带领读者快速上手,从为什么要选择Elasticsearch,如其文档导向的架构和在搜索效率上的优势,到实际安装和运行环境的设置。这里会介绍如何搭建一个基本的Elasticsearch实例,并演示如何与之交互。
随着对Elasticsearch基础概念的掌握,读者将学习如何进行文档操作,包括索引(Indexing)、检索(Retrieving)、创建、更新和删除文档。例如,"Indexing Employee Documents"部分展示了如何将结构化的员工数据存储到Elasticsearch中,而"Updating a Whole Document"则涵盖了如何全面修改文档内容。
"Search with Query DSL"是核心章节,讲解了查询语言(Query DSL)的强大功能,允许用户执行复杂的搜索操作,包括全文本搜索、短语搜索以及高级搜索技巧。同时,"Highlighting Our Searches"部分介绍了如何在搜索结果中高亮显示相关关键词,提升用户体验。
对于数据分析和实时分析,"Analytics"部分探讨了如何通过Elasticsearch进行数据挖掘和聚合,以及如何在搜索结果中嵌入统计信息。此外,书中的教程在实践环节结束后,总结了学到的关键点,并鼓励读者进一步探索Elasticsearch的分布式特性。
"Distributed Nature"深入讨论了Elasticsearch集群的工作原理,包括空集群的初始化、添加新节点、水平扩展以及故障恢复策略。读者将了解到如何确保数据的一致性和可靠性,以及如何应对各种可能的数据进出场景。
《Elasticsearch权威指南2.x版本》不仅提供了一个实用的学习路径,还包含了大量的代码示例和实践经验,帮助读者逐步精通这个现代搜索引擎的核心功能。无论是初学者还是经验丰富的开发者,都能从中找到提升技能和解决实际问题所需的资源。
Full-Text Search
that performs a range search, and reused the same match query as before. Now our results show only one employee who
happens to be 32 and is named Jane Smith:
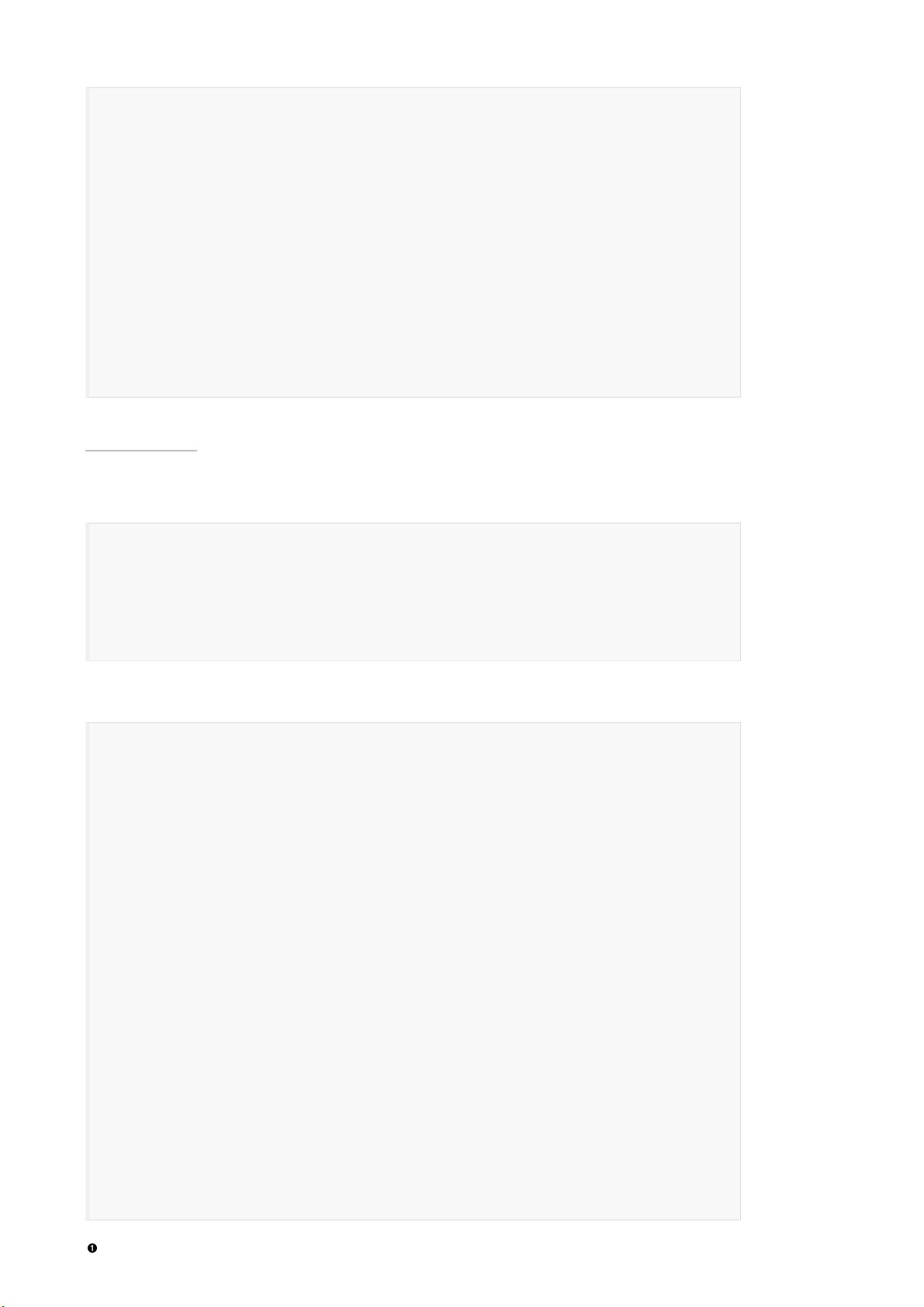
{
...
"hits": {
"total": 1,
"max_score": 0.30685282,
"hits": [
{
...
"_source": {
"first_name": "Jane",
"last_name": "Smith",
"age": 32,
"about": "I like to collect rock albums",
"interests": [ "music" ]
}
}
]
}
}
The searches so far have been simple: single names, filtered by age. Let’s try a more advanced, full-text search—a task that
traditional databases would really struggle with.
We are going to search for all employees who enjoy rock climbing:
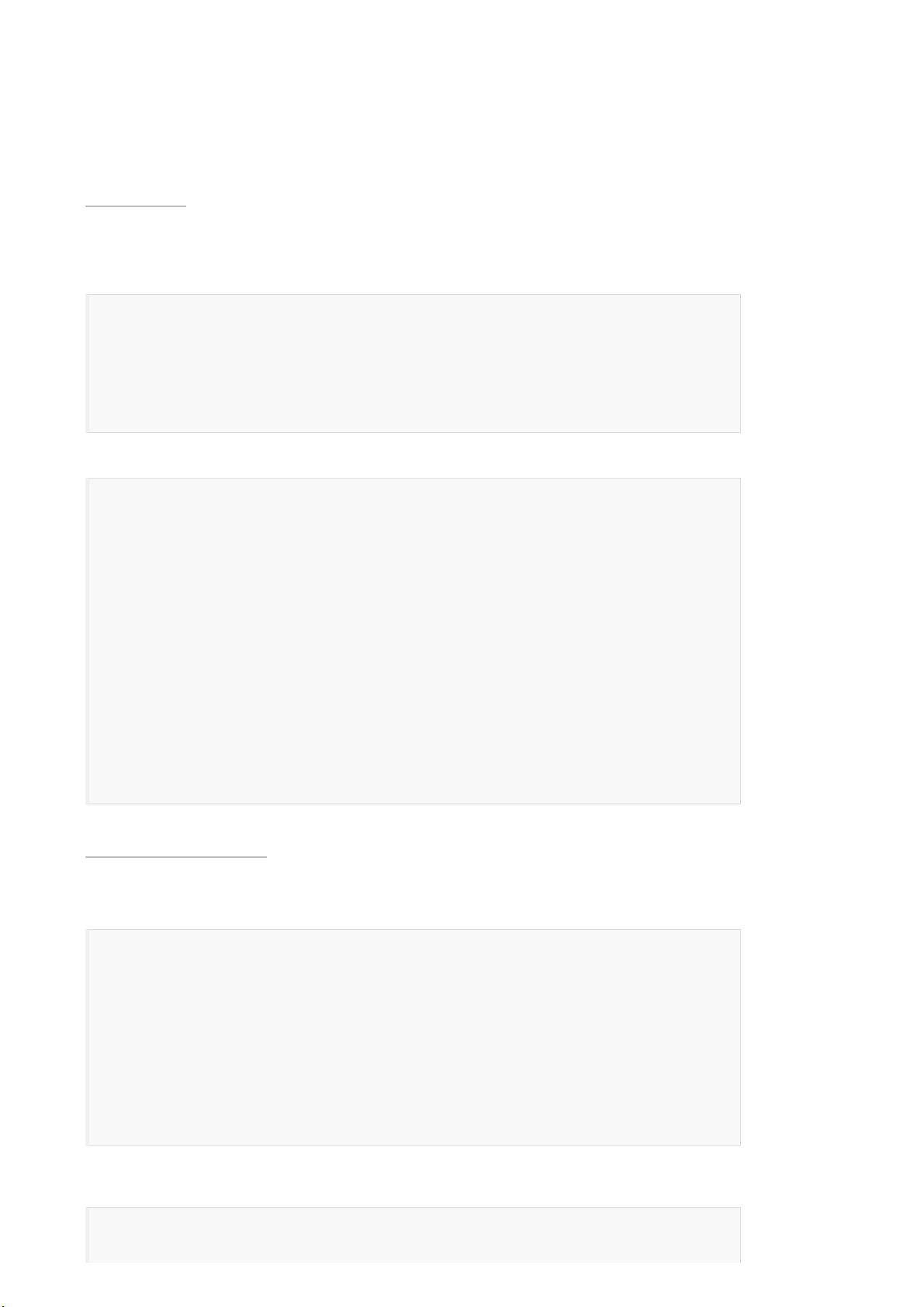
GET /megacorp/employee/_search
{
"query" : {
"match" : {
"about" : "rock climbing"
}
}
}
You can see that we use the same match query as before to search the about field for “rock climbing.” We get back two
matching documents:
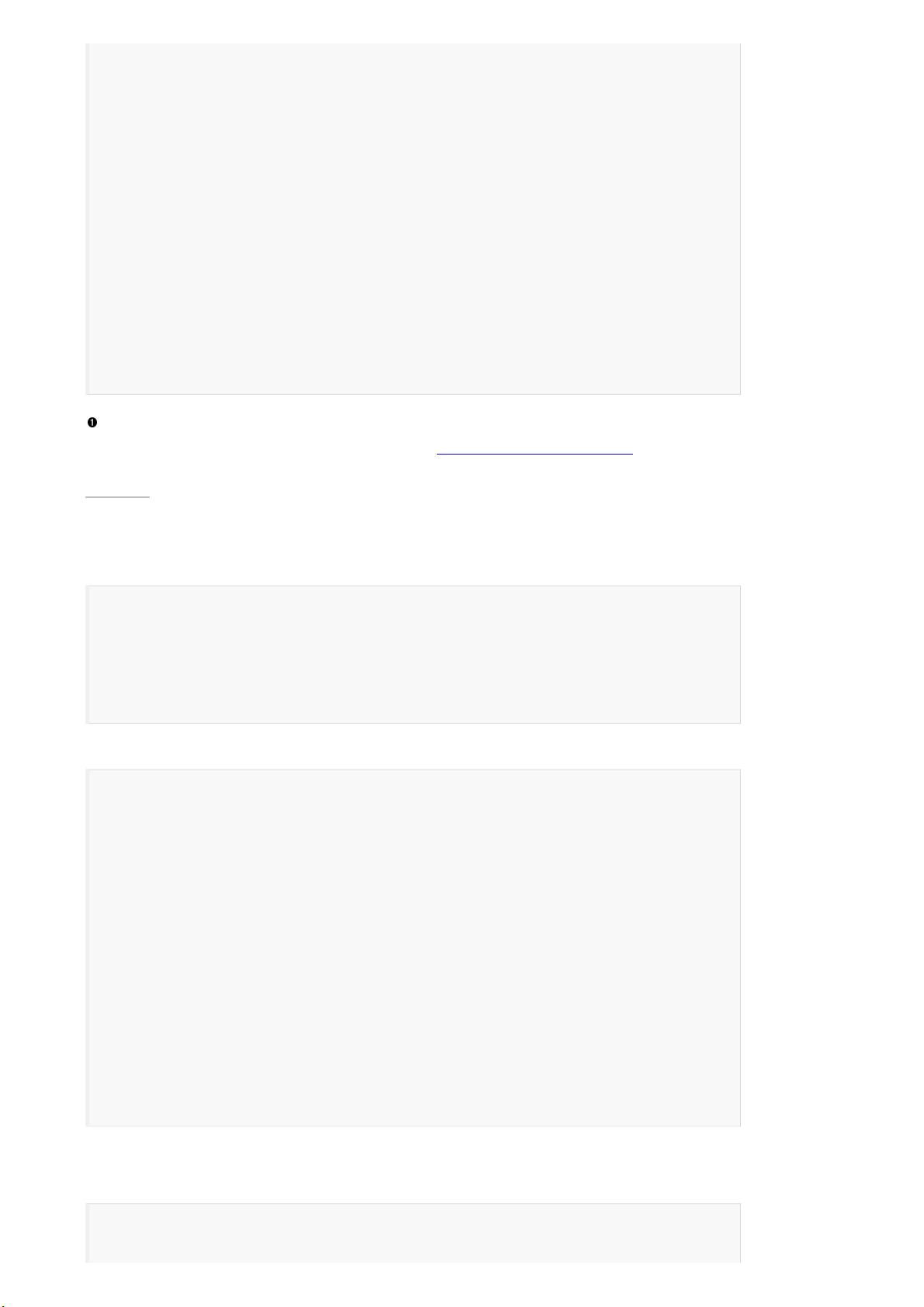
{
...
"hits": {
"total": 2,
"max_score": 0.16273327,
"hits": [
{
...
"_score": 0.16273327, <1>
"_source": {
"first_name": "John",
"last_name": "Smith",
"age": 25,
"about": "I love to go rock climbing",
"interests": [ "sports", "music" ]
}
},
{
...
"_score": 0.016878016, <1>
"_source": {
"first_name": "Jane",
"last_name": "Smith",
"age": 32,
"about": "I like to collect rock albums",
"interests": [ "music" ]
}
}
]
}
}
The relevance scores

剩余336页未读,继续阅读
点击了解资源详情
点击了解资源详情
点击了解资源详情
2015-04-03 上传
2018-01-02 上传
2018-07-22 上传
2019-06-18 上传
2018-08-22 上传
2020-08-13 上传

哥的世界你不懂
- 粉丝: 17
- 资源: 12
 我的内容管理
展开
我的内容管理
展开







最新资源
- Windows_Server_2003_R2之文件服务器资源管理器及文件服务器管理
- 基于遗传算法度约束的最小生成树问题的研究
- 基于像素置乱的加密算法的设计
- On Secret Reconstruction in Secret Sharing Schemes
- XORs in the Air: Practical Wireless Network Coding
- Tomcat实用配置
- On Practical Design for Joint Distributed Source and Network Coding
- Efficient Broadcasting Using Network Coding
- C++中extern “C”含义深层探索.doc
- 用PLC实现道路十字路口交通灯的模糊控制
- pragmatic-ajax
- 使用JSP处理用户注册和登陆
- vi Quick Reference
- 华为交换机使用手册quidway
- 在线考试系统论文.doc在线考试系统论文.doc(1).doc
- Linux操作系统下C语言编程
