数据仓库与数据挖掘:概念、技术与应用解析
版权申诉
"数据仓库与数据挖掘应用.ppt"
数据仓库是信息技术领域的重要组成部分,它是一种专注于特定主题、集成化、非易失性且随时间变化的数据集合,旨在支持管理层的决策过程。这一概念最早由W.H. Inmon在1996年提出,他将数据仓库定义为面向主题的、集成的、非易失的和时间相关的数据集合。而J. Ladley在1997年的观点中强调,数据仓库是一系列方法、技术和工具的组合,用于创建一个提供整合平台上的数据给最终用户的过程。
数据仓库体系结构通常包括多个组件,如数据源、ETL(抽取、转换、加载)工具、数据存储(例如关系型数据库管理系统)、数据模型和元数据管理。数据仓库设计阶段需要考虑业务需求、数据源分析、数据清洗、数据建模(例如星型或雪花型模型)以及性能优化。
数据仓库与数据库技术的主要区别在于其目的和设计原则。数据库通常用于事务处理和实时操作,而数据仓库则用于分析和报告,其数据经过预处理和汇总,以提供高效的查询性能。此外,数据仓库的数据结构和数据库可能不同,前者往往更注重读取性能而非写入速度。
数据仓库的性能受到多个因素影响,包括硬件配置、数据分布、索引策略、查询复杂性和并发用户数量等。优化这些因素可以提升数据仓库的响应时间和数据处理能力。
数据仓库的应用广泛,常见于金融领域的业绩分析、零售业的销售趋势分析、医疗保健的病患记录研究等。通过整合来自多个系统的数据,数据仓库能提供全面的业务视图,帮助决策者制定战略。
数据挖掘是数据仓库应用的一个关键方面,它涉及到从大量数据中发现有价值的信息和模式。数据挖掘技术包括分类、聚类、关联规则学习、序列模式挖掘和预测等。随着大数据和人工智能的发展,数据挖掘的趋势正朝着深度学习、流数据挖掘和半监督学习等方向发展。
数据挖掘应用平台通常是集成工具,如RapidMiner、SPSS Modeler等,它们提供图形化的界面,让用户无需编写代码即可进行数据预处理、模型构建和结果评估。这些平台在科学研究、市场营销、风险评估等领域都有广泛应用,并且经常与数据仓库系统结合,形成端到端的数据分析解决方案。
总结来说,数据仓库与数据挖掘是现代企业决策支持系统的核心组成部分。通过理解并有效地利用这两个领域的理论和技术,企业可以提升数据驱动的洞察力,从而提高竞争力。
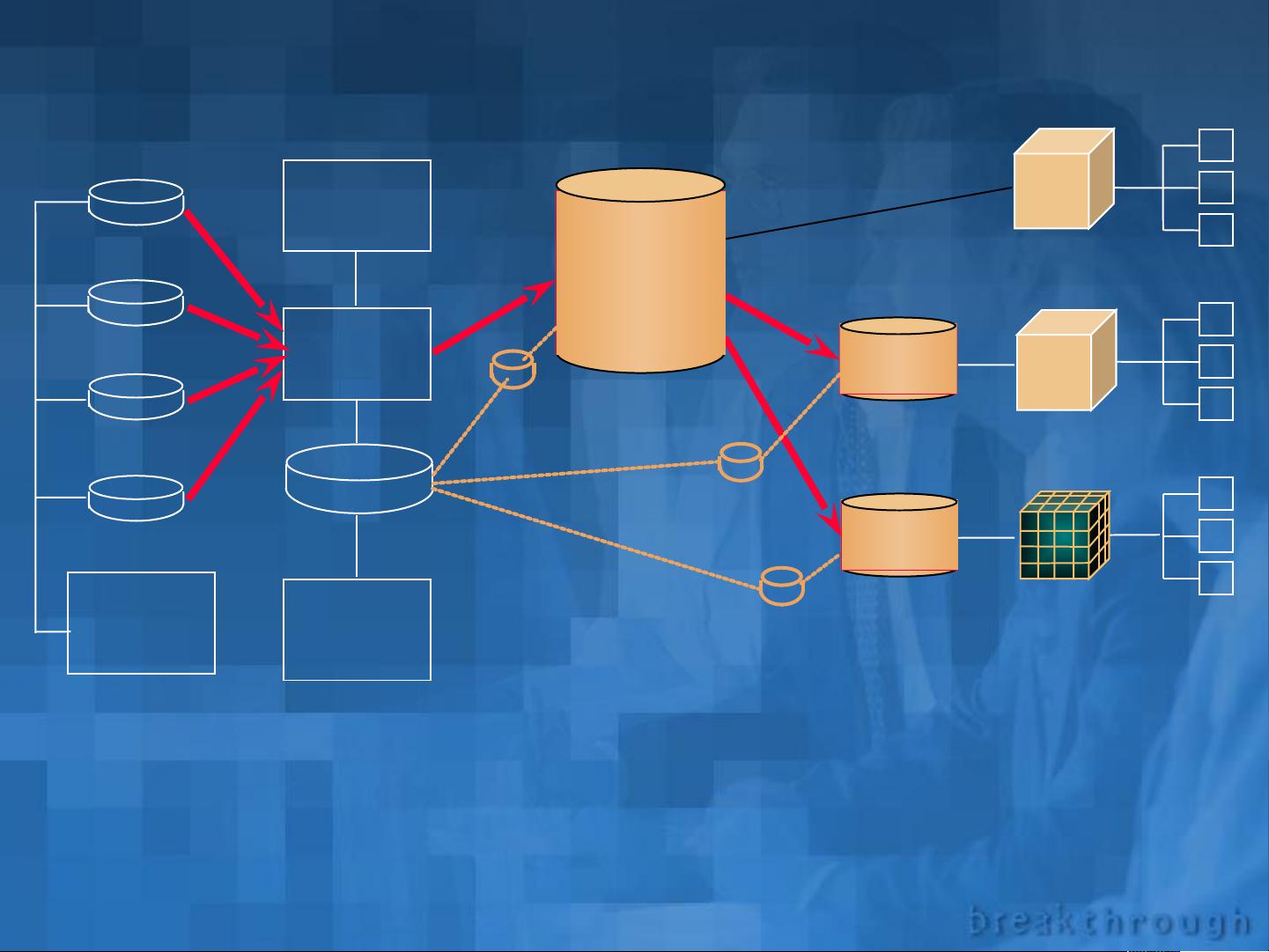
体系结构
体系结构
[
[
Pieter ,1998
Pieter ,1998
]
]
Source
Databases
Data Extraction,
Transformation, load
Warehouse
Admin.
Tools
Extract,
Transform
and Load
Data
Modeling
Tool
Central
Metadata
Architected
Data Marts
Data Access
and
Analysis
End-User
DW Tools
Central Data
Warehouse
Central
Data
Warehouse
Mid-
Tier
Mid-
Tier
Data
Mart
Data
Mart
Local
Metadata
Local
Metadata
Local
Metadata
Metadata
Exchange
MDB
Data
Cleansing
Tool
Relational
Appl. Package
Legacy
External
RDBMS
RDBMS

剩余63页未读,继续阅读
2021-09-06 上传
2021-10-08 上传
2023-06-13 上传
2022-07-02 上传
2023-07-13 上传
点击了解资源详情
2022-07-10 上传
2021-10-12 上传
2023-06-13 上传

安全方案
- 粉丝: 2196
- 资源: 3907
 我的内容管理
展开
我的内容管理
展开







最新资源
- MATLAB新功能:Multi-frame ViewRGB制作彩色图阴影
- XKCD Substitutions 3-crx插件:创新的网页文字替换工具
- Python实现8位等离子效果开源项目plasma.py解读
- 维护商店移动应用:基于PhoneGap的移动API应用
- Laravel-Admin的Redis Manager扩展使用教程
- Jekyll代理主题使用指南及文件结构解析
- cPanel中PHP多版本插件的安装与配置指南
- 深入探讨React和Typescript在Alias kopio游戏中的应用
- node.js OSC服务器实现:Gibber消息转换技术解析
- 体验最新升级版的mdbootstrap pro 6.1.0组件库
- 超市盘点过机系统实现与delphi应用
- Boogle: 探索 Python 编程的 Boggle 仿制品
- C++实现的Physics2D简易2D物理模拟
- 傅里叶级数在分数阶微分积分计算中的应用与实现
- Windows Phone与PhoneGap应用隔离存储文件访问方法
- iso8601-interval-recurrence:掌握ISO8601日期范围与重复间隔检查
