知识图谱:词汇挖掘与实体提取——第2章详解
版权申诉
189 浏览量
更新于2024-06-28
收藏 8.66MB PDF 举报
本资源是一份关于知识图谱概念与技术的深入讲解,特别是针对第二章“词汇挖掘与实体挖掘”的内容。在信息化时代,非结构化文本数据占据了组织内约80%的数据量,这使得词汇挖掘和实体挖掘成为关键的技术环节。知识图谱,如Google的Knowledge Graph,是机器理解和利用这些海量文本数据的关键工具,它通过识别和连接实体(如人、地点、事件等)、属性以及它们之间的关系来构建一个有组织的知识网络。
章节的核心内容包括:
1. **Unstructured Text Data**:强调了非结构化文本的重要性,这是知识图谱构建的基础,因为大部分现实世界的信息都以自由格式的文字形式存在。
2. **知识获取与洞察**:通过挖掘文本中的知识,可以提取出有价值的信息,帮助企业和个人获得更深层次的理解和洞见,例如引用Chakraborty (2016)的研究表明了这一价值。
3. **知识图谱的构建**:讲解了知识图谱的基本构成,包括实体(如Leonardo da Vinci)、属性(如出生日期、死亡日期)和关系(如画家与画作之间的创作关系),这些都是构建知识图谱的重要元素。
4. **结构化挖掘**:详细阐述了如何从大量文本中提取出这些结构化的信息,例如提及的《蒙娜丽莎》画像及其相关信息,展示了实体挖掘的过程,包括命名实体识别和属性值抽取。
5. **大规模文本语料库**:列举了一系列实际应用案例,如百老汇表演、剧院、公园等,说明了如何从这些实际场景的文本中进行词汇和实体的挖掘。
6. **自然语言处理的应用**:最后提到使用自然语言处理技术(NLP)在TripAdvisor工程中找到相关信息的实例,展示了技术在实际场景中的实用性和效果。
本资源聚焦于知识图谱构建过程中至关重要的词汇和实体挖掘技术,强调了其在信息时代数据处理和知识获取中的核心作用,并通过实例和案例来加深理解。
13
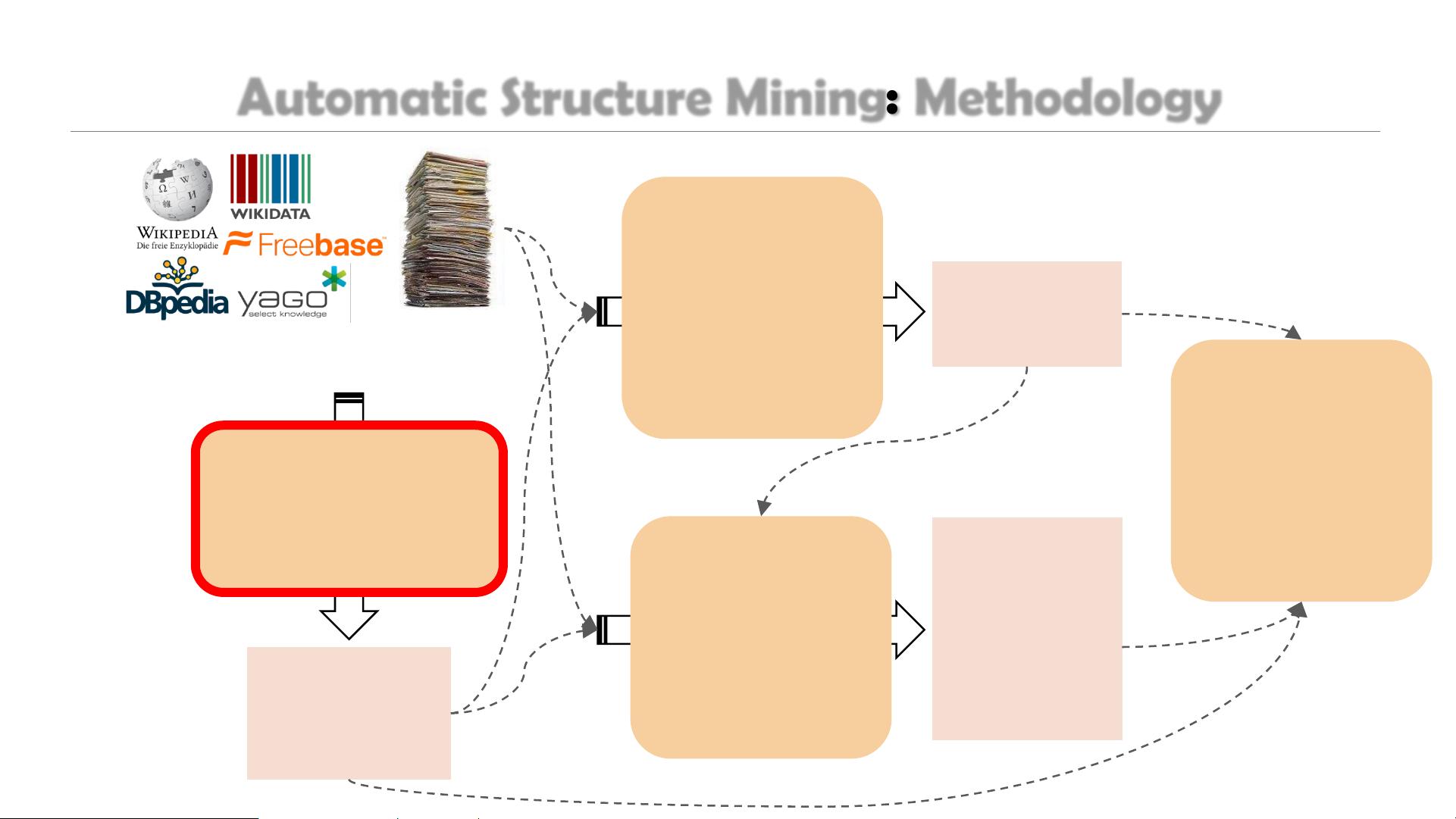
Automatic Structure Mining: Methodology
Automatic Phrase
Mining Methods
(SIGMOD’15, arXiv’17)
Entity Names
& Context
Units
Typing and
Relation
Extraction
Methods
(KDD’15, KDD’16,
EMNLP’16,
WWW’17)
Typed Entity &
Relations
Knowledge Bases Massive Text
Corpus
Meta Pattern-
Driven Attribute
Name & Value
Discovery
Methods
(KDD’17)
Attribute
Names &
Values, more
General
Relations
Other Tasks and
Applications
(ECMLPKDD’17,
KDD’17,
WWW’16)


剩余79页未读,继续阅读
2020-02-07 上传
2023-07-19 上传
2012-01-10 上传
2023-07-12 上传
2024-10-05 上传
2023-05-10 上传
2023-05-24 上传
2024-09-24 上传
2023-03-30 上传

每天读点书学堂
- 粉丝: 1039
- 资源: 1万+
 我的内容管理
展开
我的内容管理
展开







最新资源
- JDK 17 Linux版本压缩包解压与安装指南
- C++/Qt飞行模拟器教员控制台系统源码发布
- TensorFlow深度学习实践:CNN在MNIST数据集上的应用
- 鸿蒙驱动HCIA资料整理-培训教材与开发者指南
- 凯撒Java版SaaS OA协同办公软件v2.0特性解析
- AutoCAD二次开发中文指南下载 - C#编程深入解析
- C语言冒泡排序算法实现详解
- Pointofix截屏:轻松实现高效截图体验
- Matlab实现SVM数据分类与预测教程
- 基于JSP+SQL的网站流量统计管理系统设计与实现
- C语言实现删除字符中重复项的方法与技巧
- e-sqlcipher.dll动态链接库的作用与应用
- 浙江工业大学自考网站开发与继续教育官网模板设计
- STM32 103C8T6 OLED 显示程序实现指南
- 高效压缩技术:删除重复字符压缩包
- JSP+SQL智能交通管理系统:违章处理与交通效率提升
