深度学习Autoencoder解析:数据压缩与非监督学习
需积分: 10 17 浏览量
更新于2024-09-04
1
收藏 1.52MB DOCX 举报
"本文主要介绍了Autoencoder在深度学习中的应用,将其与PCA进行了对比,并提供了相关的代码示例,包括如何使用MNIST数据进行Autoencoder的训练,以及如何通过编码器将高维数据压缩到二维空间进行可视化。"
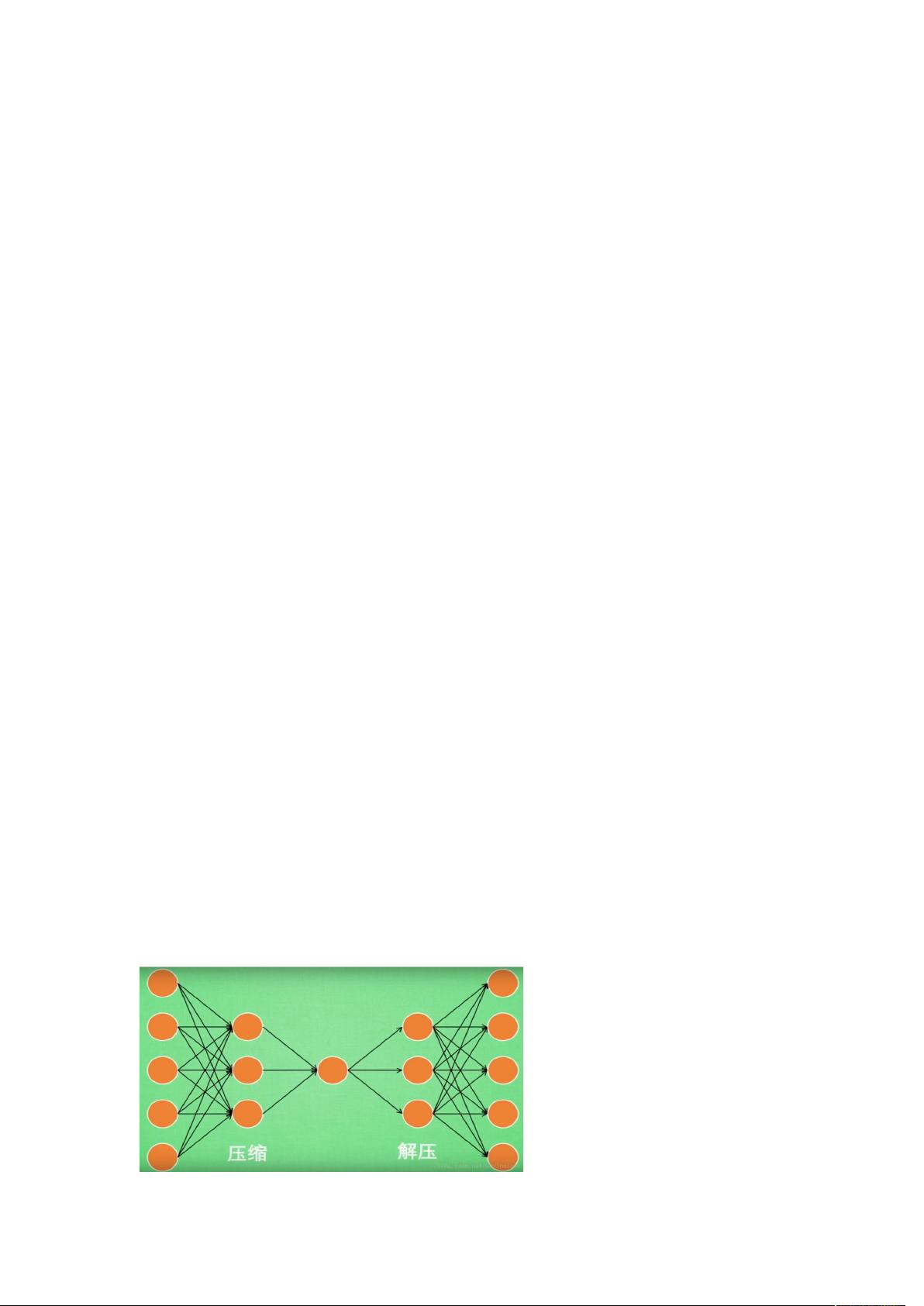
深度学习中的Autoencoder是一种用于数据压缩和降维的神经网络模型,它通过自我编码和解码的过程来学习数据的内在表示。Autoencoder的核心思想是通过一个受限的神经网络结构,使得输入数据经过编码器(Encoder)压缩后得到低维的特征表示,然后再通过解码器(Decoder)尽可能地恢复原始输入,以此实现数据的无监督学习。
非监督学习是Autoencoder的重要特性,不同于传统的有标签监督学习任务,Autoencoder在没有明确类别标签的情况下,通过对输入数据的编码和解码过程,自我学习数据的结构和特征。这与PCA(主成分分析)有一定的相似性,两者都是用于数据降维的方法。PCA通过线性变换找到数据的主要成分,而Autoencoder则采用非线性的神经网络结构,能够捕捉更复杂的数据模式。
在实际应用中,Autoencoder常用于数据预处理,例如在图像处理领域,它可以用来去除噪声或者提取图像的关键特征。文中提到,使用MNIST手写数字数据集进行实验,每个图像包含784个特征(28x28像素)。Autoencoder首先通过两个隐藏层分别将特征数量压缩到256和128,然后通过解码层逐步还原至原始尺寸。通过比较原始数据与解码后的数据,计算损失函数(cost),并据此调整模型参数以提高重构的准确性。
编码器部分可以独立使用,将高维数据压缩成较低维度的向量,这在可视化任务中特别有用。当编码后的特征维度降低到2或3时,可以将数据投影到二维或三维空间,以直观地展示数据分布和类别关系。在文中提到的示例中,不同类别的MNIST图像被编码为二维特征,同色的点代表具有相同标签的数据点,这种方法有助于我们理解数据集的结构。
Autoencoder在深度学习中扮演着重要的角色,它提供了一种非监督学习的数据表示学习方法,不仅可以用于数据压缩和降维,还能在图像去噪、特征提取和数据可视化等方面发挥作用。通过调整网络结构和训练策略,Autoencoder可以适应各种不同的应用场景,是深度学习中一个非常实用且灵活的工具。
深度学习之 Autoencoder (非监督学习)
2018-03-19 17:37:39山水之间 2018阅读数 8124收藏 更多
分类专栏: 深度学习
版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上
原文出处链接和本声明
本文链接:https://blog.csdn.net/Gavinmiaoc/article/details/79612925
Autoencoder简单来说就是将有很多 Feature 的数据进行压缩,之后再进行
解压的过程。
本质上来说,它也是一个对数据的非监督学习,如果大家知道 PCA(Principal
component analysis), 与 Autoencoder 相类似,它的主要功能即对数据
进行非监督学习,并将压缩之后得到的“特征值”,这一中间结果正类似于 PCA
的结果。 之后再将压缩过的“特征值”进行解压,得到的最终结果与原始数据进
行比较,对此进行非监督学习。如果大家还不是非常了解,请观看机器学习简
介系列里的 Autoencoder那一集; 如果对它已经有了一定的了解,那么便可
以进行代码阶段的学习了。大概过程如下图所示:
下载后可阅读完整内容,剩余7页未读,立即下载
2019-07-26 上传
2021-08-16 上传
2023-02-23 上传
2022-06-16 上传
2021-12-23 上传
2022-07-03 上传
2022-06-14 上传
2023-03-07 上传
2024-03-01 上传

weixin_43367808
- 粉丝: 2
- 资源: 3
 我的内容管理
展开
我的内容管理
展开







最新资源
- Protein_x64.3.17.dll
- springbootmysql_springbooteclipse_源码
- HTML5CSS3自定义浮动Select 超炫下拉菜单动画源码.zip
- 基于SSM+vue的校园代购服务订单管理系统.zip
- todomvc-meteor-react:在 React + Meteor 中带有路由器和动画的全功能 TodoMVC
- Python库 | django-user-management-1.1.1.tar.gz
- 100套Java源码-Moving-Through-a-Maze:在Java中使用数字和字符串此编程任务有四个目标:使用Java变量和运算符编
- cods:COdeup部署脚本
- Java-SpringBoot的体育场馆运营管理系统设计与实现毕业设计源码
- PowerPC VxWorks BSP分析_powerpcvxworks_
- HTML5CSS3制作Safari Logo指针动画效果源码.zip
- acadock-monitoring:监控 docker 容器以获取实时 CPUMemoryNetworking
- Python库 | django-user-deletion-0.2.0.tar.gz
- wptalents:wptalents.com的主要插件
- CompileTimer:一组测试基准C ++结构的编译时间
- Java-SpringBoot社区疫情防控信息管理平台毕业设计源码
