编译原理实验:自顶向下预测分析法
需积分: 9 90 浏览量
更新于2024-08-13
1
收藏 339KB DOC 举报
"本次实验是关于编译原理的课程设计,重点在于理解预测分析器的工作原理,特别是自顶向下的预测语法分析方法。学生需要掌握手工构建预测语法分析程序的技巧,通过使用C语言和Codeblocks编译器来实现。实验内容包括设计清晰的程序模块,构建预测分析表,并定义相关变量以实现分析过程。"
在编译原理中,预测分析器是一种用于语法分析的工具,它基于文法规则预测下一步的操作。实验的目的在于让学习者深入理解预测分析器的构造,特别是自顶向下的方法,这种方法是从文法的起始符号开始,逐步推导出输入串的语法结构。在这个过程中,预测分析器需要能够决定在遇到某个非终结符时应该选择哪个产生式继续解析。
实验中,首先介绍了文法G[S]及其预测分析表。这个文法描述了一个简单的算术表达式,包括加法、乘法、括号和常数。预测分析表用于指导分析器在遇到特定的非终结符或终结符时应如何行动。例如,当分析器处于状态S时,如果遇到终结符'T',它应当进行AT的推导;如果遇到非终结符'B',则进行BU的推导。预测分析表是预测分析器的核心,它的正确构建直接影响到语法分析的准确性。
实验设计上,要求将程序分解成多个模块,每个模块负责特定的任务。例如,可能会有模块用于处理文法的输入,有的用于构造预测分析表,还有的用于执行实际的分析操作。结构体的定义是程序实现的关键部分,它们存储文法规则和预测分析表的信息。实验中提到了两个关键的结构体变量:一是用来存储文法规则,另一个用于分析栈中的元素。
分析串和剩余串是语法分析过程中重要的数据结构。分析串代表了分析栈的当前状态,通常以#开头,表示起始符号。剩余串则是未被分析的部分,初始状态为输入的字符串加上#作为结束标记。在分析过程中,这两个串会不断更新,反映分析的进度。
此外,实验中还涉及到一些辅助变量,如标记变量flag用于判断栈顶元素是否为终结符,finish用于标记程序的结束,计数变量k和b分别跟踪分析过程中的步骤和终结符位置,而m和n则用于在预测分析表中定位产生式。
这个实验是一个综合性的实践项目,涵盖了编译原理中的重要概念,包括预测分析、文法表示、分析表构造和程序模块化设计。通过完成这个实验,学生不仅能深入理解编译器的工作原理,还能提高编程和问题解决的能力。
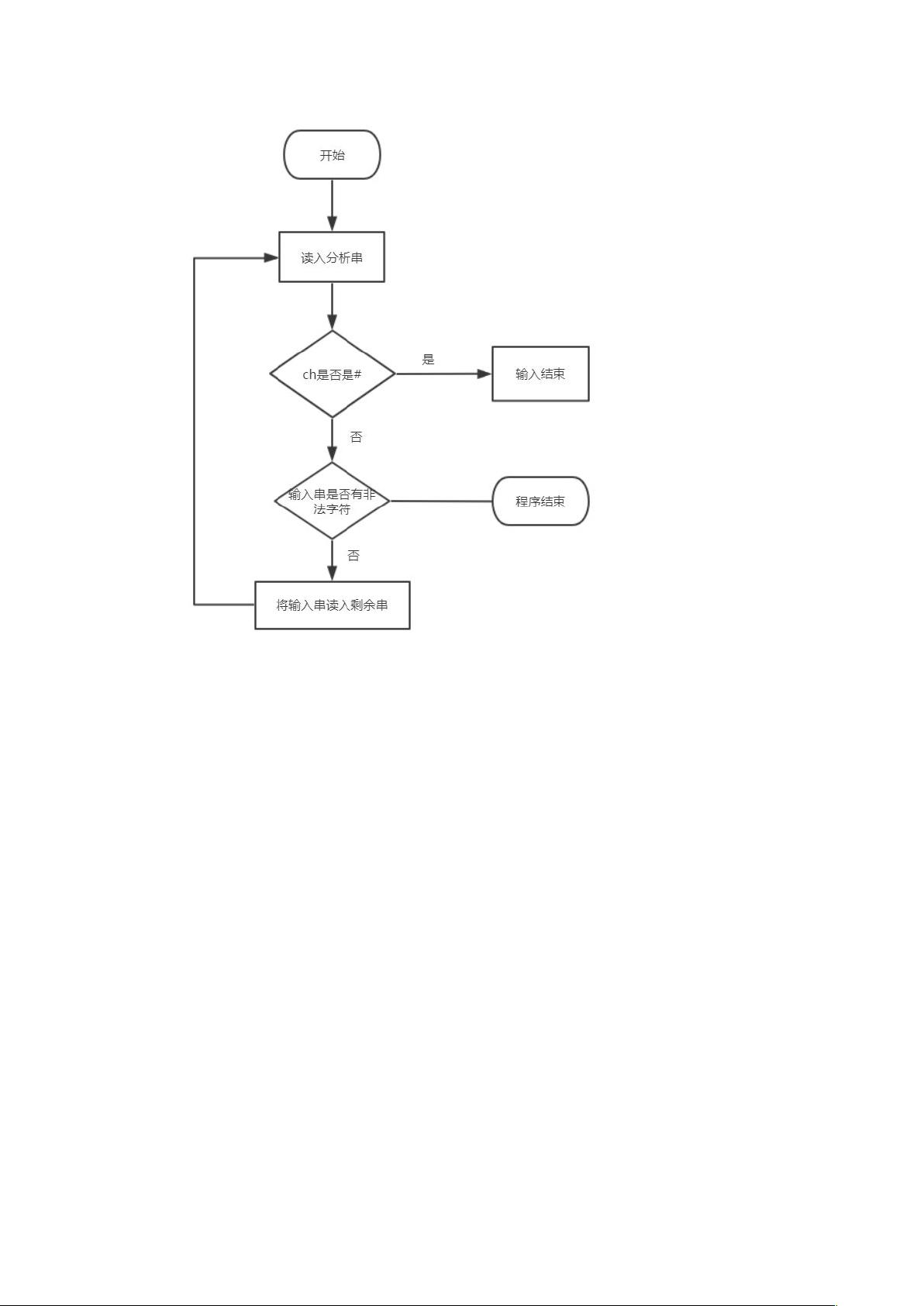
(4)判断栈顶是否是终结符 :
判断栈顶字符是否是终结符。用 x 记录当前栈顶字符,然后将栈顶字符弹出(即将栈
顶指针做减一操作)。判断 x 是否是终结符所在 char 数组 v1[20]中的元素,是则进行(5)
中函数的操作,不是则进行(6)中函数的操作。用标记变量 flag 实现这里的跳转。每执行
一次,记录步骤的变量 k 做加一操作并输出。
(5)如果是终结符:
首先判断栈顶字符是否是结束符#(初始化的栈是#S,栈顶字符为 S),因此如果栈顶
字符为结束符并且剩余串均为#,则输入串合法,输出提示信息并退出程序。如果当前分析
字符是除#之外的终结符,输出分析栈和剩余串以及匹配的字符。
用 ch 存放当前需要分析的字符(均为终结符),将剩余串的第 b 个字符 B[b]赋值给
ch(b 初始化为 0),在每次分析完一个输入字符之后执行 b 加一操作,然后再将下一个
需要分析的字符赋给 ch。
出错处理:在分析表的一行输出分析栈和剩余串,输出分析栈和剩余串,并输出不合
法的字符,然后提示“输入串不合法”。
(6)如果不是终结符,非终结符处理:
在预测分析表中找到非终结符对应的行号,记为 m,用当前分析字符 ch(终结符)找
到预测分析表中对应的列号,记为 n,将行号 m 和列号 n 对应的产生式赋值给结构体变量
cha。
然后判断 cha 是否为空,即对应位置是否已有产生式,如果没有,则进行出错处理,
输出分析串和剩余串,并输出出错的非终结符,然后输出报错信息“出错了!”。如果 cha 不
为空,打印出分析栈和剩余串,打印出产生式的左边和右边,然后将产生式的右边逆序赋
剩余11页未读,继续阅读
点击了解资源详情
点击了解资源详情
点击了解资源详情
2024-05-23 上传
2021-03-28 上传
2020-09-29 上传
2023-09-06 上传
2023-08-27 上传
2021-08-13 上传

比目鱼~
- 粉丝: 10
- 资源: 9
 我的内容管理
展开
我的内容管理
展开







最新资源
- 火炬连体网络在MNIST的2D嵌入实现示例
- Angular插件增强Application Insights JavaScript SDK功能
- 实时三维重建:InfiniTAM的ros驱动应用
- Spring与Mybatis整合的配置与实践
- Vozy前端技术测试深入体验与模板参考
- React应用实现语音转文字功能介绍
- PHPMailer-6.6.4: PHP邮件收发类库的详细介绍
- Felineboard:为猫主人设计的交互式仪表板
- PGRFileManager:功能强大的开源Ajax文件管理器
- Pytest-Html定制测试报告与源代码封装教程
- Angular开发与部署指南:从创建到测试
- BASIC-BINARY-IPC系统:进程间通信的非阻塞接口
- LTK3D: Common Lisp中的基础3D图形实现
- Timer-Counter-Lister:官方源代码及更新发布
- Galaxia REST API:面向地球问题的解决方案
- Node.js模块:随机动物实例教程与源码解析
