使用MPI进行多GPU编程与NVIDIA CUDA MPS
需积分: 5 166 浏览量
更新于2024-07-15
收藏 3.04MB PDF 举报
"S8314_Multi_GPU_Programming_with_MPI.pdf" 是一份关于使用MPI(Message Passing Interface)进行多GPU编程的资料,重点介绍了NVIDIA CUDA Multi-Process Service (MPS)如何加速多进程服务。
在高性能计算领域,GPU(图形处理器)已经成为并行计算的关键组件,特别是NVIDIA的CUDA平台,它为开发者提供了直接编程GPU的能力。MPI是实现分布式计算系统中进程间通信的标准协议,它可以使得多台计算机上的多个进程协同工作,处理大规模计算任务。
本资料中,Cheng Yi,作为NVIDIA的高级解决方案架构师,探讨了如何结合MPI与CUDA来实现跨GPU的通信。图示展示了一个典型的节点网络,每个节点包含CPU、GPU、内存和InfiniBand(高速网络技术)连接,通过PCIe交换机互连。这种架构允许GPU之间的数据交换,而不仅仅是局限于CPU。
文档提到的学习目标包括理解什么是MPI,以及如何利用MPI进行CUDA和OpenACC环境下的GPU间通信。CUDA-aware MPI是一种优化的MPI实现,它能够直接感知GPU内存,从而减少了数据在GPU和CPU之间传输的开销。这提升了效率,因为数据可以直接在GPU之间传递,而不是先回传到CPU再转发。
NVIDIA CUDA Multi-Process Service (MPS) 是一种特殊的服务,它允许多个独立的GPU应用在同一个GPU上同时运行。通过MPS,多个CUDA进程可以共享一个GPU,从而提高资源利用率和并行处理能力。学习如何配置和使用MPS是提升GPU集群性能的重要一环。
此外,资料还将教授如何在MPI环境中使用NVIDIA的工具,这些工具能够帮助开发者更好地调试、性能分析和优化MPI应用。隐藏MPI通信时间是提高整体应用性能的关键,通过智能调度和优化通信模式,可以减少等待时间,增加计算效率。
这份资料深入浅出地介绍了在大规模计算环境中如何有效利用MPI和CUDA MPS进行多GPU编程,对于希望提升GPU并行计算性能的开发者具有极高的参考价值。
14
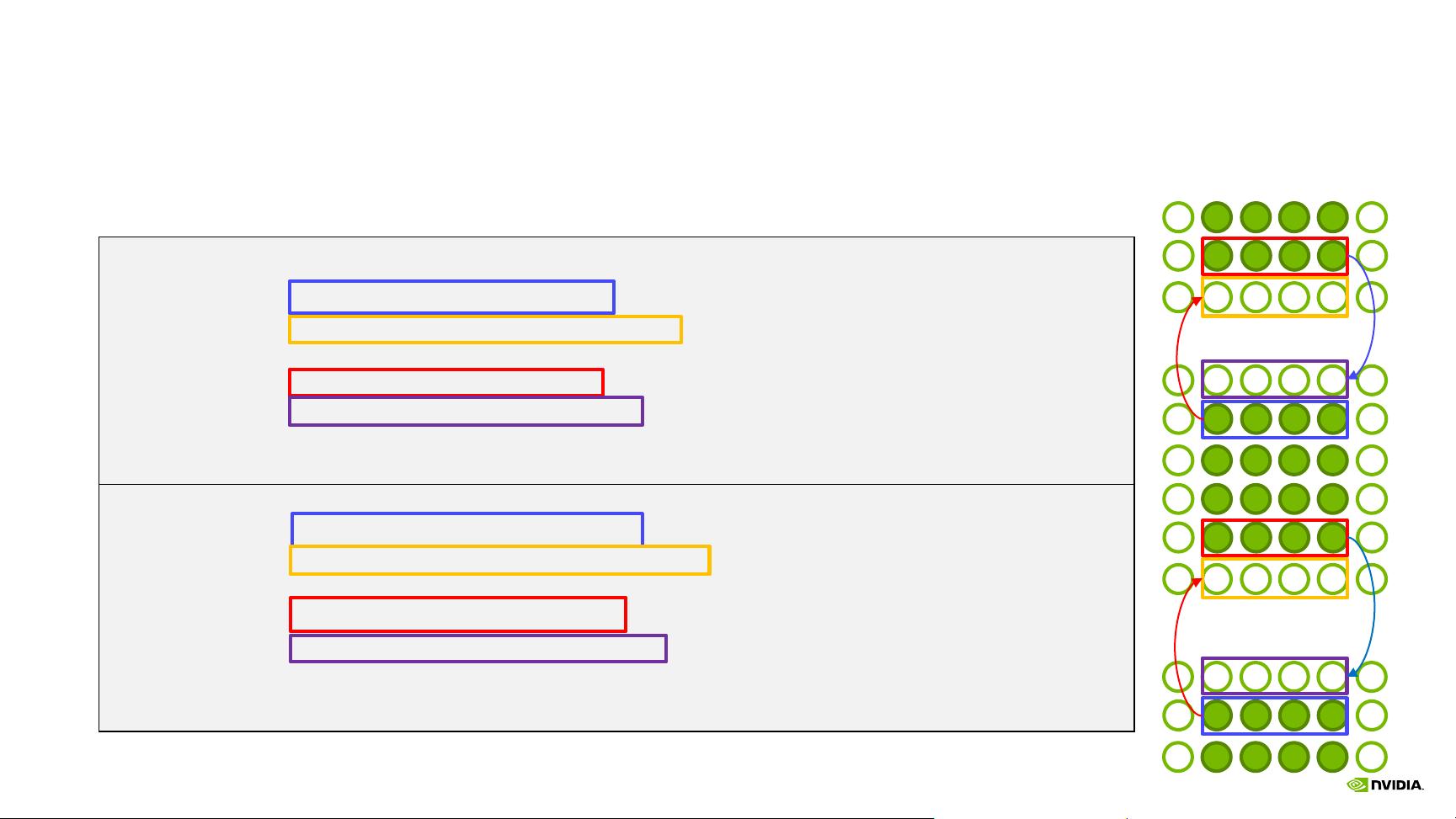
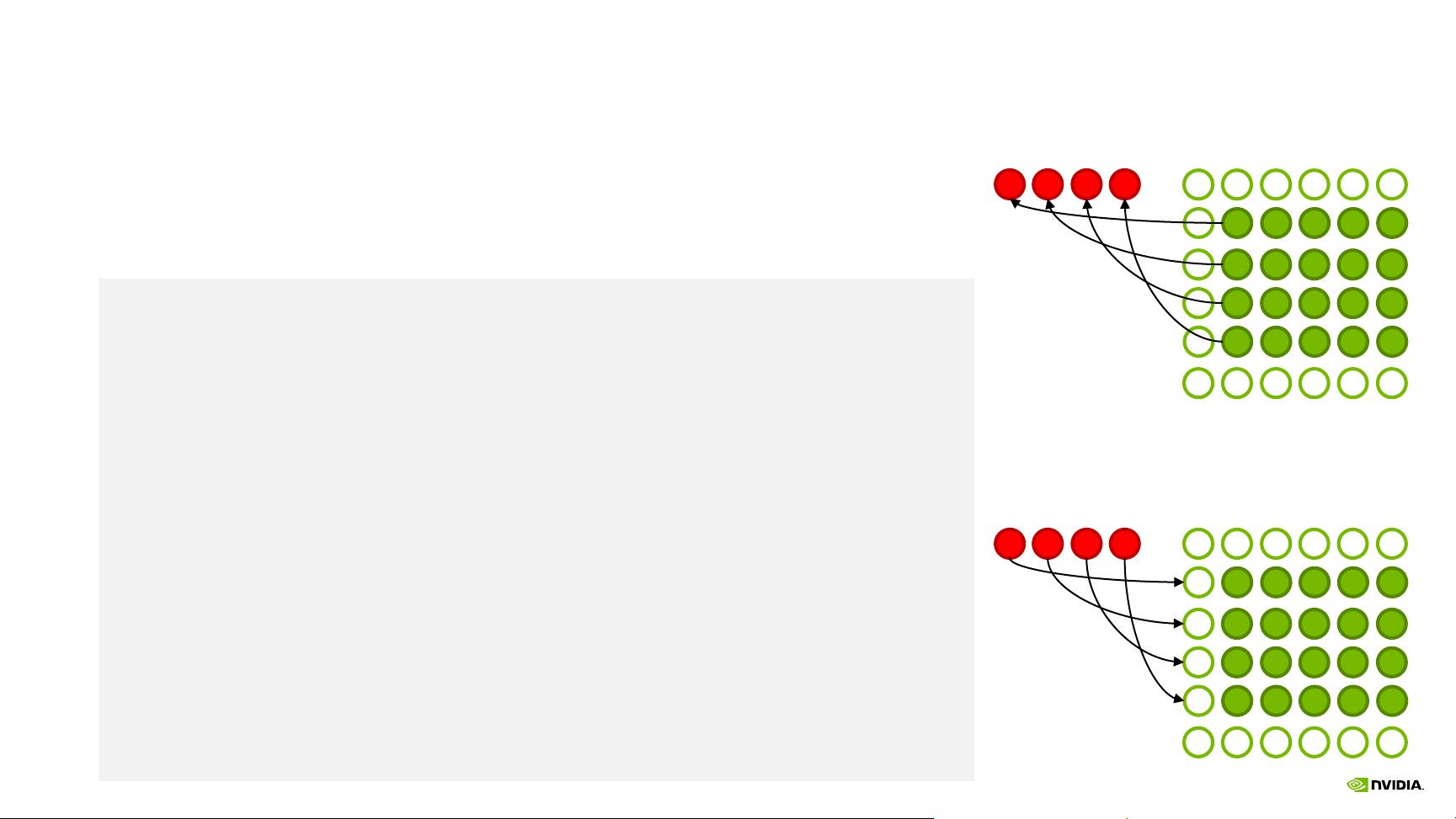
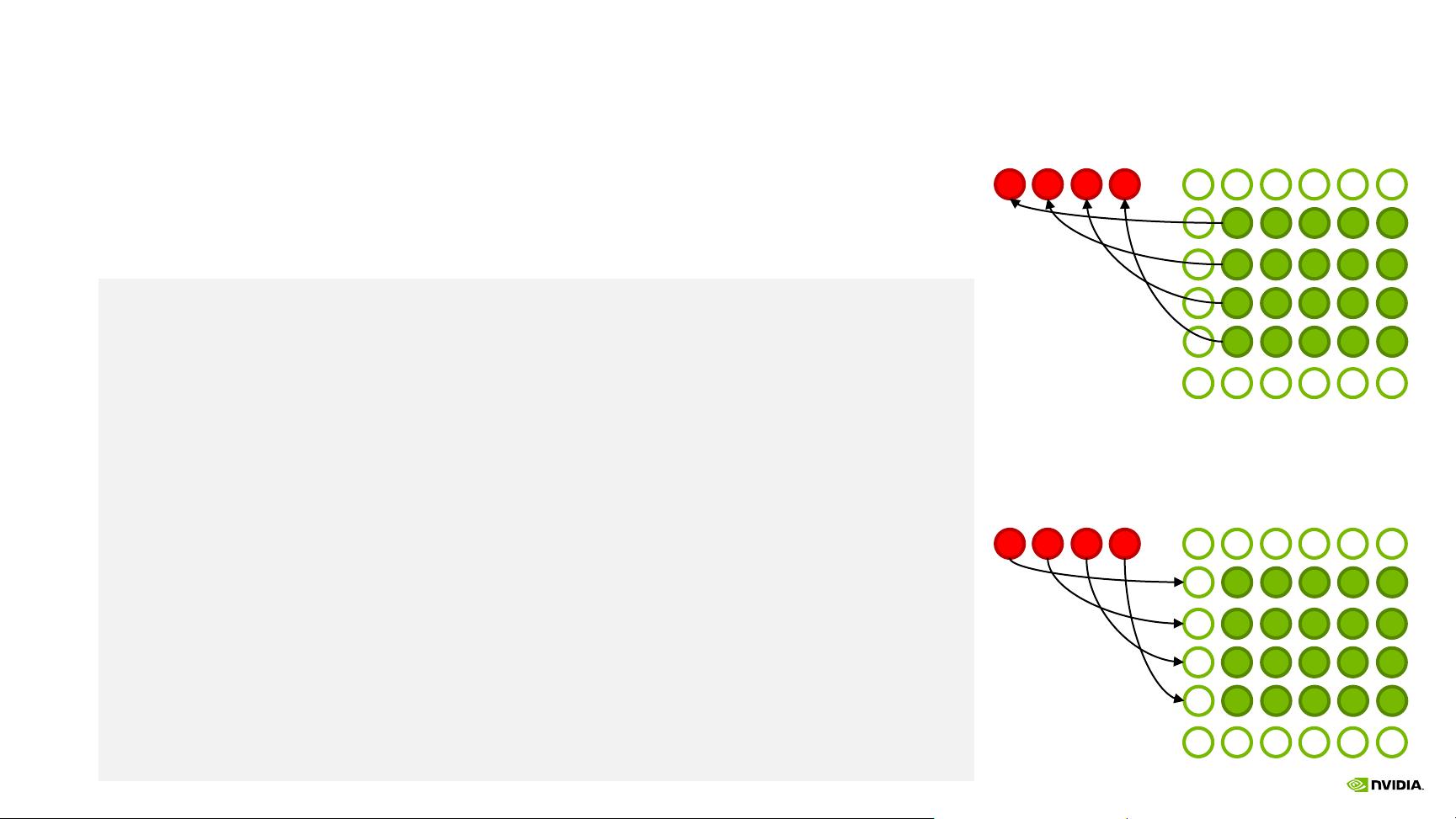
EXAMPLE JACOBI
Top/Bottom Halo
#pragma acc host_data use_device ( u_new ) {
MPI_Sendrecv(u_new+offset_first_row, m-2, MPI_DOUBLE, t_nb, 0,
u_new+offset_bottom_boundary, m-2, MPI_DOUBLE, b_nb, 0,
MPI_COMM_WORLD, MPI_STATUS_IGNORE);
MPI_Sendrecv(u_new+offset_last_row, m-2, MPI_DOUBLE, b_nb, 1,
u_new+offset_top_boundary, m-2, MPI_DOUBLE, t_nb, 1,
MPI_COMM_WORLD, MPI_STATUS_IGNORE);
}
11/26/2018
MPI_Sendrecv(u_new_d+offset_first_row, m-2, MPI_DOUBLE, t_nb, 0,
u_new_d+offset_bottom_boundary, m-2, MPI_DOUBLE, b_nb, 0,
MPI_COMM_WORLD, MPI_STATUS_IGNORE);
MPI_Sendrecv(u_new_d+offset_last_row, m-2, MPI_DOUBLE, b_nb, 1,
u_new_d+offset_top_boundary, m-2, MPI_DOUBLE, t_nb, 1,
MPI_COMM_WORLD, MPI_STATUS_IGNORE);
1
1
2
2
OpenACC
CUDA

剩余83页未读,继续阅读
2022-09-20 上传
2022-09-22 上传
2021-06-19 上传
2015-10-24 上传
2018-04-03 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情
2024-11-13 上传

TracelessLe
- 粉丝: 5w+
- 资源: 466
 我的内容管理
展开
我的内容管理
展开







最新资源
- 黑板风格计算机毕业答辩PPT模板下载
- CodeSandbox实现ListView快速创建指南
- Node.js脚本实现WXR文件到Postgres数据库帖子导入
- 清新简约创意三角毕业论文答辩PPT模板
- DISCORD-JS-CRUD:提升 Discord 机器人开发体验
- Node.js v4.3.2版本Linux ARM64平台运行时环境发布
- SQLight:C++11编写的轻量级MySQL客户端
- 计算机专业毕业论文答辩PPT模板
- Wireshark网络抓包工具的使用与数据包解析
- Wild Match Map: JavaScript中实现通配符映射与事件绑定
- 毕业答辩利器:蝶恋花毕业设计PPT模板
- Node.js深度解析:高性能Web服务器与实时应用构建
- 掌握深度图技术:游戏开发中的绚丽应用案例
- Dart语言的HTTP扩展包功能详解
- MoonMaker: 投资组合加固神器,助力$GME投资者登月
- 计算机毕业设计答辩PPT模板下载
