异构系统间数据一致性:挑战与解决方案
版权申诉
183 浏览量
更新于2024-08-07
收藏 1.03MB DOC 举报
"异构系统间数据一致性是一个重要的技术挑战,尤其在多方合作的项目中。本文通过一个具体的会议项目案例,探讨了如何在不同系统间保持数据的一致性。项目涉及三个主要参与者:面向用户的A方、数据中间B方以及会议数据同步C方(作者所在公司)。系统间通过API交互,但在数据同步过程中存在请求无序、循环更新和排错困难等问题,影响了系统的稳定性和效率。"
详细说明:
在多系统协作的环境中,数据一致性至关重要,因为它确保了信息的准确性和可靠性。在这个会议项目中,A方负责用户报名,B方作为ISP处理数据存储和流转,而C方则执行数据导入、更新、审核和注销等操作,并与B方保持双向同步。这种架构虽然满足了项目的实际需求,但由于数据冗余和异步交互,导致了一些问题。
首先,请求无序的问题在于,B方接收到的报名数据可能没有按照预期的顺序到达,这可能是因为网络延迟或并发处理导致的。当C方依赖特定顺序(如主会报名先于子会报名)时,这种无序可能会引起逻辑错误。
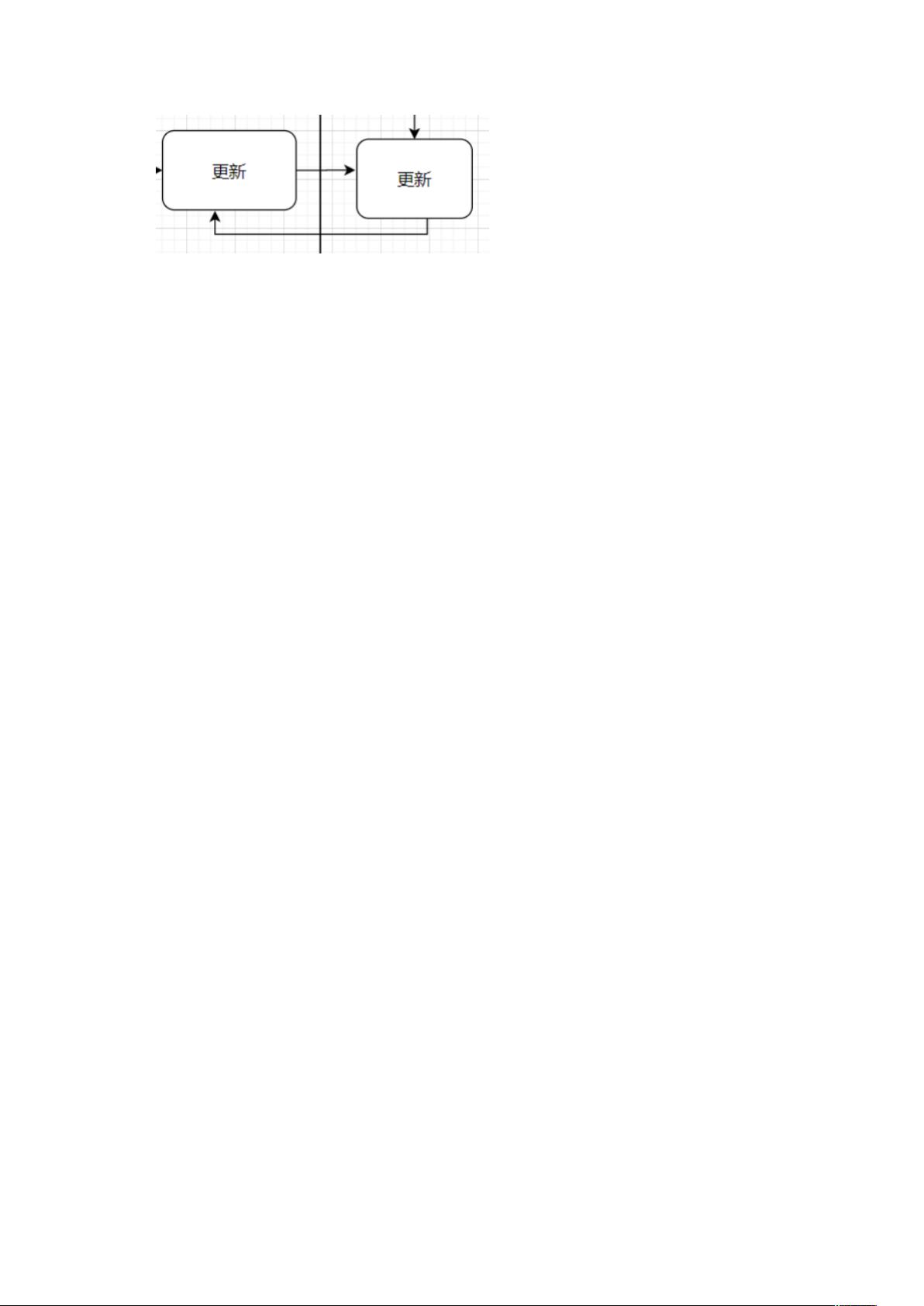
其次,循环更新的问题源于B方和C方之间的双向同步。当任何一方的数据发生变化时,都会通知对方进行更新,这可能导致不必要的重复更新,甚至陷入无限循环。虽然已经采取了一些措施防止这种情况,但仍然存在潜在风险。
再者,由于缺乏合适的开发环境和调试工具,排查问题变得非常困难。在没有日志分析工具支持的情况下,定位故障点需要手动追踪调用链,效率低下,尤其是在高并发环境下,可能出现的bug更难以定位和修复。
为了解决这些问题,可以采取以下策略:
1. 引入消息队列:通过使用消息队列(如RabbitMQ、Kafka)可以有序地处理请求,确保数据处理的顺序性。
2. 增加同步控制机制:例如引入版本号或乐观锁,避免无谓的循环更新。
3. 提升排错能力:搭建测试环境进行联调,采用日志收集和分析工具(如ELK Stack或Logstash)进行集中式的日志管理和故障排查。
4. 高并发优化:针对并发场景进行压力测试,优化接口设计,减少冲突和异常的发生。
总结来说,实现异构系统间数据一致性需要对系统架构进行深入理解和优化,通过引入适当的中间件、提高同步策略的智能性以及提升排错能力,可以有效地降低数据不一致性的风险,从而提高整个系统的稳定性和用户体验。
排错困难
无开发环境,需盲写代码,发到测试环境进行联调测试。调用链太长,日志过多,排错时
需要根据调用各服务接口来判断走到了哪步,出现了一个问题。调用链能查到一些问题,但
不容批量定位问题。单个查太难。
bug
高并发下,redis 组件出现各种问题(timeout 等)token 问题数据丢失更新失效数据重复队
列积压接口请求时间超长其他问题...
数据很大,也很小
大部分数据能对上,偶尔几十个或断断续续产生新问题的数据需要及时人工修复。功能有
缺陷,人工也是一种交付办法,但不可持续,太他妈的累了。数据不一致,也是导致通宵核
对/修复数据的一大原因。如果数据全一致,就不会那么辛苦了。
解决思路
管理层
明确项目是要继续做的目标产品化/更方便维护方向发展。一团队养一项目。有改进想法
提出来,拉会推进缺人,招人(遥遥无期...)
技术层
针对请求无序问题,引入延时队列,先处理主会、子会延迟几秒钟在处理。针对循环更新
问题,记录 B 方数据来源,非必要情况下,不回更 B 方。必须终止掉。【冤冤相报何时了】
针对排错困难问题,引入 mysql 记录新增报名的请求以及处理结果,可以更快查询处理结果。
针对 bug,测试根据各测试场景进行复测,按 10/100/1000/3000/万级规模压测。提前发下问题。
推进客户方一起做必要去重逻辑。
其他因素
无论是标准产品还是交付项目,做任何改动都要评估。
多沟通,大家都是站在一条线的。有利于事情解决的方案认同度会更高。预估花多少时间,
有多少资源。能挤出来的空窗期有多久,客户方/产品方对于需求的急迫性有多强。基于场
景测试,把缺陷优先级先列出来,根据空窗期先修复紧急缺陷。
把紧急且影响范围广的问题解决了,风险就小了很多了。80%的问题是由 20%的因素造成
的。 这也正符合程序优化中的时间/空间局部性。
“
进程运行时,在一段时间里,程序的执行往往呈现高度的局部性,
剩余13页未读,继续阅读
2021-09-24 上传
2023-07-08 上传
2021-09-18 上传
2023-07-07 上传
2022-07-05 上传
2022-12-23 上传
2022-06-12 上传
2021-11-26 上传
2022-12-17 上传

书博教育
- 粉丝: 1
- 资源: 2837
 我的内容管理
展开
我的内容管理
展开







最新资源
- Fisher Iris Setosa数据的主成分分析及可视化- Matlab实现
- 深入理解JavaScript类与面向对象编程
- Argspect-0.0.1版本Python包发布与使用说明
- OpenNetAdmin v09.07.15 PHP项目源码下载
- 掌握Node.js: 构建高性能Web服务器与应用程序
- Matlab矢量绘图工具:polarG函数使用详解
- 实现Vue.js中PDF文件的签名显示功能
- 开源项目PSPSolver:资源约束调度问题求解器库
- 探索vwru系统:大众的虚拟现实招聘平台
- 深入理解cJSON:案例与源文件解析
- 多边形扩展算法在MATLAB中的应用与实现
- 用React类组件创建迷你待办事项列表指南
- Python库setuptools-58.5.3助力高效开发
- fmfiles工具:在MATLAB中查找丢失文件并列出错误
- 老枪二级域名系统PHP源码简易版发布
- 探索DOSGUI开源库:C/C++图形界面开发新篇章
