剖析ConcurrentHashMap底层实现与性能优化
版权申诉
89 浏览量
更新于2024-08-06
收藏 616KB DOC 举报
在【面试普通人VS高手系列】中,ConcurrentHashMap的底层实现是一个重要的面试话题。ConcurrentHashMap是Java集合框架中用于并发访问的高效哈希映射表,它是HashMap的一个并发版本。对于普通面试者,他们可能仅仅了解到ConcurrentHashMap使用数组和链表(或红黑树)来处理hash冲突,但在深入理解上有所欠缺。以下是对高手回答的详细解析:
1. 整体架构:
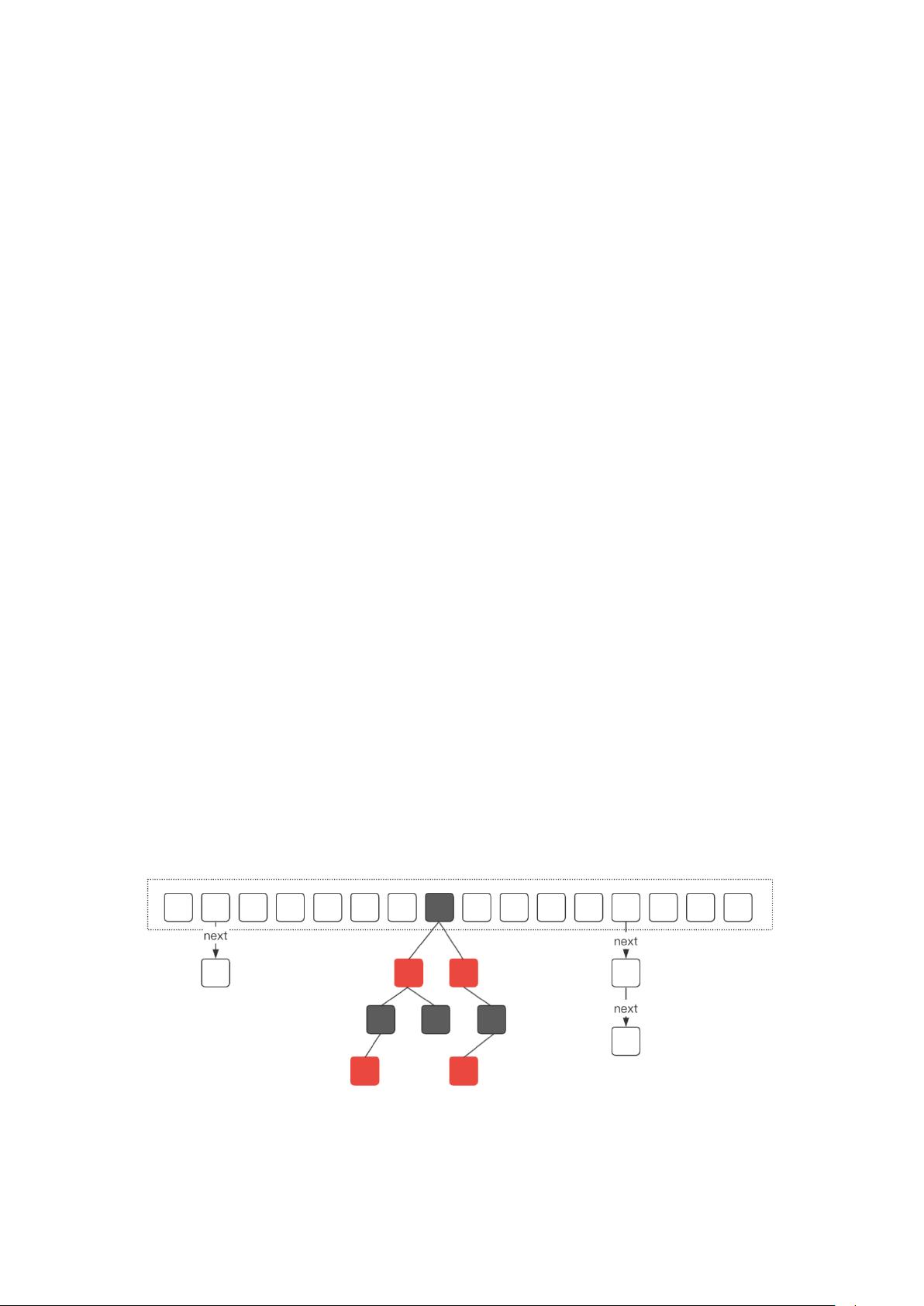
ConcurrentHashMap在JDK1.8中采用了特殊的存储结构,由数组、单向链表和红黑树组成。数组作为基本的存储单元,通过哈希函数将键值对分布到不同的位置。当冲突发生时,首先尝试使用链表存储,链表长度超过一定阈值(默认8)时,会切换到红黑树,这有助于保持查询效率。当链表再次变短(小于8),红黑树又会恢复为链表。
2. 基本功能:
ConcurrentHashMap的主要功能类似于HashMap,提供键值对的存储、查找、删除等操作。但它增强了并发性,允许多个线程同时读写,通过分段锁(Segment)的方式实现了线程安全。每个Segment是一个独立的哈希表,互不影响,确保了并发操作的原子性。
3. 性能优化:
- 并发性与数据安全:ConcurrentHashMap通过使用读写分离的策略,读操作几乎不需要加锁,大大提高了读取性能。写操作则在特定的Node节点上加锁,确保数据的一致性。
- 动态调整:ConcurrentHashMap在插入元素后,会根据负载因子自动调整数组大小,以维持良好的性能。这包括从链表转换为红黑树,以及从红黑树退化回链表。
- 缓存利用:类似CPU的三级缓存策略,ConcurrentHashMap可以利用缓存行来提高内存访问效率,减少缓存未命中的开销。
- 数据库优化:MySQL的缓冲池机制也有类似的思路,通过预加载数据到内存缓存,提高数据查询速度。
总结来说,高手在回答关于ConcurrentHashMap的问题时,不仅会详细解释其底层结构、核心功能,还会强调其并发性能优化策略和如何平衡并发和数据一致性。这对于理解并应对复杂的面试问题至关重要。
【面试普通人 VS 高手系列】ConcurrentHashMap 底层具体实现知道吗?实现原理是什么?
之 前 分 享 过 一 期 HashMap 的 面 试 题 , 然 后 有 个 小 伙 伴 私 信 我 说 , 他 遇 到 了 一 个
ConcurrentHashMap 的问题不知道怎么回答。
于是,就有了这一期的内容!!
我是 Mic,一个工作了 14 年的 Java 程序员,今天我来分享关于 ”ConcurrentHashMap 底
层实现原理“ 这个问题,
看看普通人和高手是如何回答的!
普通人:
嗯.. ConcurrentHashMap 是用数组和链表的方式来实现的,嗯… 在 JDK1.8 里面还引入了
红黑树。然后链表和红黑树是解决 hash 冲突的。嗯……
高手:
这个问题我从这三个方面来回答:
ConcurrentHashMap 的整体架构
ConcurrentHashMap 的基本功能
ConcurrentHashMap 在性能方面的优化
ConcurrentHashMap 的整体架构
这个是 ConcurrentHashMap 在 JDK1.8 中的存储结构,它是由数组、单向链表、红黑树组
成。
下载后可阅读完整内容,剩余3页未读,立即下载

书博教育
- 粉丝: 1
- 资源: 2834
 我的内容管理
展开
我的内容管理
展开







最新资源
- Hadoop生态系统与MapReduce详解
- MDS系列三相整流桥模块技术规格与特性
- MFC编程:指针与句柄获取全面解析
- LM06:多模4G高速数据模块,支持GSM至TD-LTE
- 使用Gradle与Nexus构建私有仓库
- JAVA编程规范指南:命名规则与文件样式
- EMC VNX5500 存储系统日常维护指南
- 大数据驱动的互联网用户体验深度管理策略
- 改进型Booth算法:32位浮点阵列乘法器的高速设计与算法比较
- H3CNE网络认证重点知识整理
- Linux环境下MongoDB的详细安装教程
- 压缩文法的等价变换与多余规则删除
- BRMS入门指南:JBOSS安装与基础操作详解
- Win7环境下Android开发环境配置全攻略
- SHT10 C语言程序与LCD1602显示实例及精度校准
- 反垃圾邮件技术:现状与前景
