MVD-based 3D视频非对称编码提升视图渲染质量
97 浏览量
更新于2024-08-28
收藏 1.17MB PDF 举报
随着3-D视频技术的兴起,为用户带来高度沉浸式的体验已成为趋势。这种技术主要依赖于深度图像基渲染(DIBR)来生成虚拟视图,然而,深度图的失真可能导致虚拟视图中几何形状的变形,同时纹理视频的失真也会影响虚拟视图的质量。因此,对纹理视频和深度图进行有效的压缩至关重要,特别是在位分配上,非对称编码策略被证明是优化3D视频压缩和视图渲染问题的关键。
本文提出了一种创新的基于多视角视频加深度(MVD)的3D视频非对称编码方法,目标是提升视图渲染的质量。首先,文章构建了两个模型,一个用于表征3D视频中的视图渲染失真,另一个关注双目抑制效应,这是视图渲染过程中的重要因素。这两个模型被整合到编码框架中,形成一种非对称编码策略,旨在在保证压缩效率的同时,减少对视图质量和感知视觉质量的影响。
编码过程中,作者提出了色度重建算法,这是一种精细的技术,能够确保在压缩后的视频中,原始的色彩信息得到准确还原,这对于高质量的视图渲染至关重要。实验结果显示,与现有的编码方法相比,这种方法在比特率有限的情况下,能显著提高视图渲染性能,而且对3D视频的视觉感知影响微乎其微。
本文的工作在3D视频编码和视图渲染领域具有重要意义,它不仅解决了深度数据和纹理视频之间的编码不平衡问题,还展示了如何在压缩效率和视图质量之间找到最佳平衡,从而为用户提供更加流畅、逼真的3D体验。随着技术的发展,这种非对称编码方法可能成为未来3D视频传输和处理的重要基石。
SHAO et al.: ASYMMETRIC CODING OF MULTI-VIEW VIDEO PLUS DEPTH BASED 3-D VIDEO FOR VIEW RENDERING 159
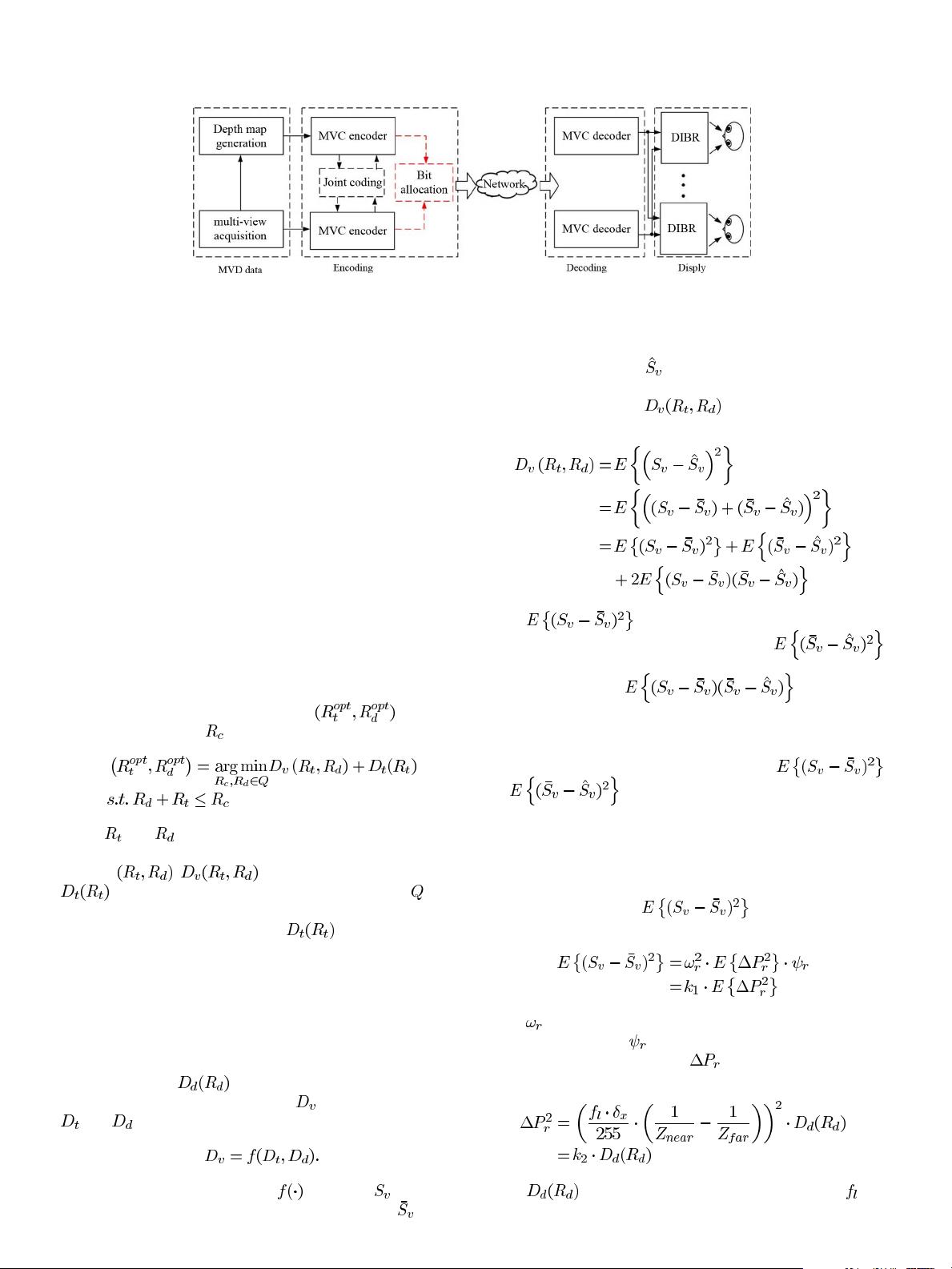
Fig. 1. System framework of the MVD-based 3-D video system.
asymmetric coding methods of 2-D video, the proposed asym-
metric coding method of 3-D video mainly consists of two parts,
that is, asymmetric coding of texture videos and depth maps, and
asymmetric coding of texture videos. In the system framework,
the first part is fulfilled by a bit allocation model which only
takes the objective quality as the optimization criterion, and the
second part is fulfilled by a chrominance reconstruction model
which takes the visual characteristics of binocular suppression
into consideration. Then, the two parts are combined into one
framework by implementing appropriate bitrate allocation and
rate control strategies. As a result, the objective quality of the
rendered virtual view will be improved while keeping the same
or nearly the same perceptual visual quality.
In the MVD-based 3-D video system, virtual views are ren-
dered from the compressed texture videos and depth maps, and
the distorted texture videos and depth maps resulting from com-
pression can be propagated to the virtual views. Therefore, the
optimal bitrate ratio problem between texture videos and depth
maps is necessary to be solved in MVD-based 3-D video coding.
In order to seek the optimal bitrate pair,
, under the
total bitrate constraint
, the problem is formulated as
(1)
where
and are the coding bitrates of texture videos and
depth maps, respectively; they are constructed a bitrate pair, de-
noted as
. is the view rendering distortion,
is the coding distortion of texture videos, and is the
candidate set of the bitrate pair. An important feature of the
model is that the coding distortion
of texture videos is
also included, because texture videos usually need to maintain
higher quality for the purpose of being compatible with 2-D dis-
play.
It is assumed that the multi-view acquisition, depth gener-
ation, view rendering, and 3-D display modules in Fig. 1 are
fixed; thus, the quality of the rendered virtual view may be
mainly affected by the coding distortions of texture videos and
depth maps. Let
denote coding distortion of depth
maps, the view rendering distortion
can be represented by
and as a function of
(2)
In order to model the function
in (2), let denote the
original texture image at the virtual view position,
denote
the image rendered by the original texture images and the com-
pressed depth maps, and
denote the image rendered by the
compressed texture images and the compressed depth maps, the
view rendering distortion
can be approximately de-
composed into two components
(3)
where
represents the average view rendering
distortion induced by depth compression, and
represents the average view rendering distortion induced by tex-
ture compression, and
approximates
to zero [25]. In practical view rendering implementation, the
virtual view is rendered from multiple adjacent views. Theo-
retically, the impact of different views on the same virtual view
should be taken in account in the distortions
and . Since the depth maps of different views
have large amounts of uniform contents, the impact of different
views on the same virtual view may be similar if the impact of
occlusion is ignored. For simplicity, we only consider the im-
pact from one adjacent view in the above distortions.
It is supposed that the location of virtual view is known, for
a particular virtual view,
can be characterized
by a linear model and expressed as [26]
(4)
where
is the weighting factor of the rendered virtual image
from a particular view,
is the linear parameter which is asso-
ciated with image contents, and
acts as the warping posi-
tion error, which is computed as [27]
(5)
where
is the coding distortion of depth maps, de-
notes the focal length of the camera in the horizontal direction,
剩余10页未读,继续阅读
2010-03-18 上传
2023-05-10 上传
2023-03-31 上传
2023-07-08 上传
2023-05-17 上传
2023-05-10 上传
2023-05-14 上传
2023-10-24 上传
2023-05-11 上传

weixin_38740130
- 粉丝: 6
- 资源: 927
 我的内容管理
展开
我的内容管理
展开







最新资源
- C++多态实现机制详解:虚函数与早期绑定
- Java多线程与异常处理详解
- 校园导游系统:无向图实现最短路径探索
- SQL2005彻底删除指南:避免重装失败
- GTD时间管理法:提升效率与组织生活的关键
- Python进制转换全攻略:从10进制到16进制
- 商丘物流业区位优势探究:发展战略与机遇
- C语言实训:简单计算器程序设计
- Oracle SQL命令大全:用户管理、权限操作与查询
- Struts2配置详解与示例
- C#编程规范与最佳实践
- C语言面试常见问题解析
- 超声波测距技术详解:电路与程序设计
- 反激开关电源设计:UC3844与TL431优化稳压
- Cisco路由器配置全攻略
- SQLServer 2005 CTE递归教程:创建员工层级结构
