DNN-HMM多语种电话语音识别器:性能分析与Kaldi实践
需积分: 10 160 浏览量
更新于2024-07-17
1
收藏 2.01MB PDF 举报
本篇论文主要探讨了基于深度神经网络(DNN)和隐马尔可夫模型(HMM)的多语言电话语音识别问题,针对五个东欧语言——捷克语、俄语、匈牙利语、斯洛伐克语和波兰语,这些语言的语音数据集在SpeechDat-E中可用。由于所使用的SAMPA(Simplified Articulatory Matrix Phonetic Alphabet)编码不规范,且不同符号代表相同的音素,首先提出了将特定语言的音素映射到通用的X-SAMPA音标字母表的方法。
研究重点在于分析多语言声学建模对连续语音识别任务的影响。分别对基于高斯混合模型-隐马尔可夫模型(GMM-HMM)系统和基于深度神经网络-高斯混合模型(DNN-GMM)方法进行了分析。实验是在保持每种语言特定声学模型不变的情况下进行的,利用Kaldi工具包实现了这些识别器。论文目标之一是提供Kaldi工具的教程式描述和SpeechDat数据库的使用指南,以便于该领域研究人员的进一步研究。
单语言HMM识别器在不同语言中的最佳准确率达到了18%至28%的词错误率(WER)。引入DNN-HMM后,整体上平均提升了约4%的WER。对于多语言HMM系统,识别准确率范围在25%至37%的WER之间。对于多语言DNN模型,其对语音识别准确性产生了显著提升,平均降低了约9%的WER。
论文还涵盖了语音识别任务中的音素识别和大词汇连续语音识别分析,以全面评估DNN-HMM架构在多语言电话语音识别中的性能。通过这个研究,作者不仅展示了深度学习技术在语音识别中的应用优势,而且提供了实用的工具和技术指导,为后续的研究者提供了宝贵的参考。
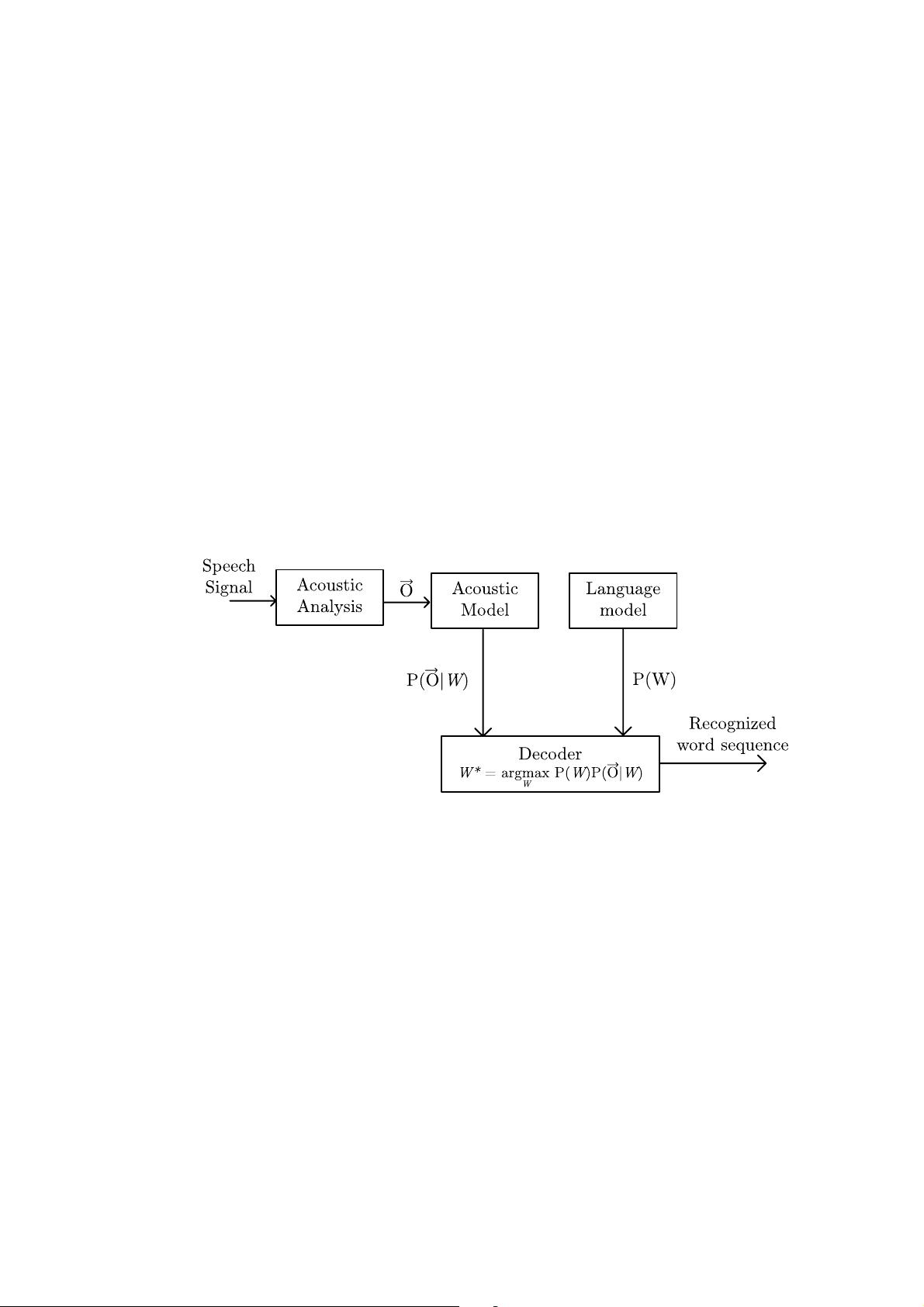
2 Continuous Speech Recognition
The first speech recognition attempts were to recognize the isolated words and expres-
sions. The principle of the first recognizers was a template matching. To evaluate and
compare two utterances, the dynamic programing was used to model the nonlinear vari-
ations in the spe ech speed of one of the utterances. Such approach is called the dynamic
time warping and it was the most used classification method in the 70s and early 80s.
During the 80s, the statistical classification methods were introduced and laid down
the base for continuos speech recognition. The statistical approach of continuos speech
recognition is described in this chapter.
Figure 1 The principle of a statistical large vocabulary speech recognition approach.
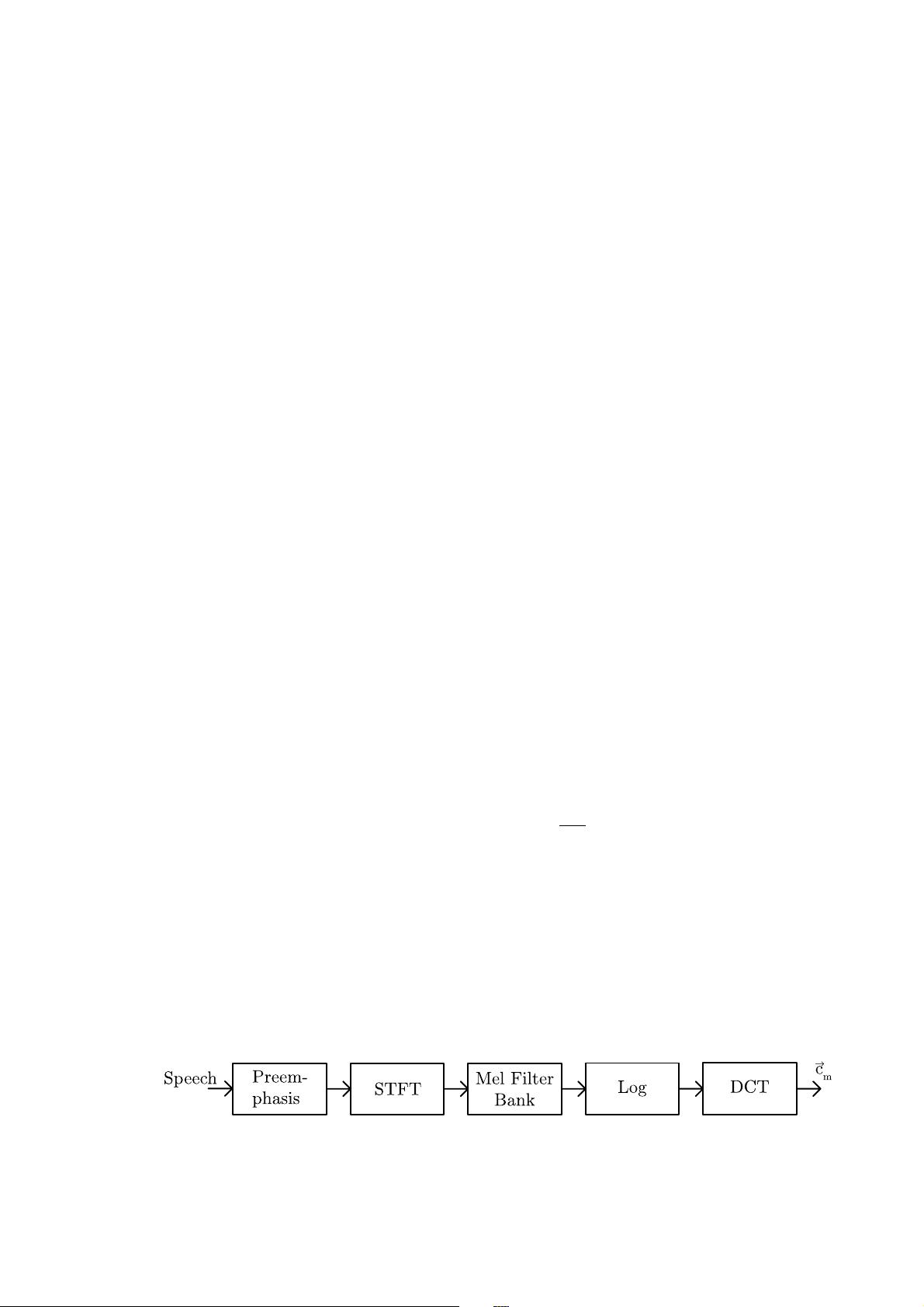
An acoustic analysis of the input speech signal performs two main subtasks. The first
is the s ignal processing itself. It can include denoising, echo cancellation, pre-emphasis
and other modifications to clean and normalize the input speech audio signal. The main
function of the acoustic analysis is to extract the sequence of features that is processed
and recognized by a decoder. The elements of this sequence represent the feature vectors
in the individual time steps t. Let’s denote this sequence as O =(x
1
, x
2
, x
3
,...,x
t
).
Let’s assume the sequence W =(w
1
,w
2
,w
3
,...,w
n
) of n words. Then the sequence of
the acoustic observations O generates W with the probability P (W |O). The key task
of the decoder is to find such sequence W
ú
which maximizes the probability P (W |O),
written as
W
ú
= argmax
W
P (W |O) . (1)
3


剩余65页未读,继续阅读
2023-08-03 上传
2023-05-12 上传
2023-10-16 上传
2024-05-28 上传
2023-08-21 上传

aiXpert
- 粉丝: 224
- 资源: 11
 我的内容管理
展开
我的内容管理
展开







最新资源
- JDK 17 Linux版本压缩包解压与安装指南
- C++/Qt飞行模拟器教员控制台系统源码发布
- TensorFlow深度学习实践:CNN在MNIST数据集上的应用
- 鸿蒙驱动HCIA资料整理-培训教材与开发者指南
- 凯撒Java版SaaS OA协同办公软件v2.0特性解析
- AutoCAD二次开发中文指南下载 - C#编程深入解析
- C语言冒泡排序算法实现详解
- Pointofix截屏:轻松实现高效截图体验
- Matlab实现SVM数据分类与预测教程
- 基于JSP+SQL的网站流量统计管理系统设计与实现
- C语言实现删除字符中重复项的方法与技巧
- e-sqlcipher.dll动态链接库的作用与应用
- 浙江工业大学自考网站开发与继续教育官网模板设计
- STM32 103C8T6 OLED 显示程序实现指南
- 高效压缩技术:删除重复字符压缩包
- JSP+SQL智能交通管理系统:违章处理与交通效率提升
