KMP算法详解:高效字符串匹配
需积分: 15 100 浏览量
更新于2024-07-23
1
收藏 2.02MB PDF 举报
"字符串匹配的KMP算法是一种高效的字符串查找算法,由克努斯、莫里斯和普拉特提出。KMP算法避免了对已匹配字符的重复比较,从而提高了搜索效率。在主文本字符串S中查找词W时,它利用预处理得到的失配表来决定在不匹配发生时搜索应如何进行。失配表记录了词W内部各个子串的最长公共前缀和后缀,使得在不匹配发生时可以直接跳过这些已匹配的部分,直接从可能导致匹配的位置继续比较。
KMP算法步骤如下:
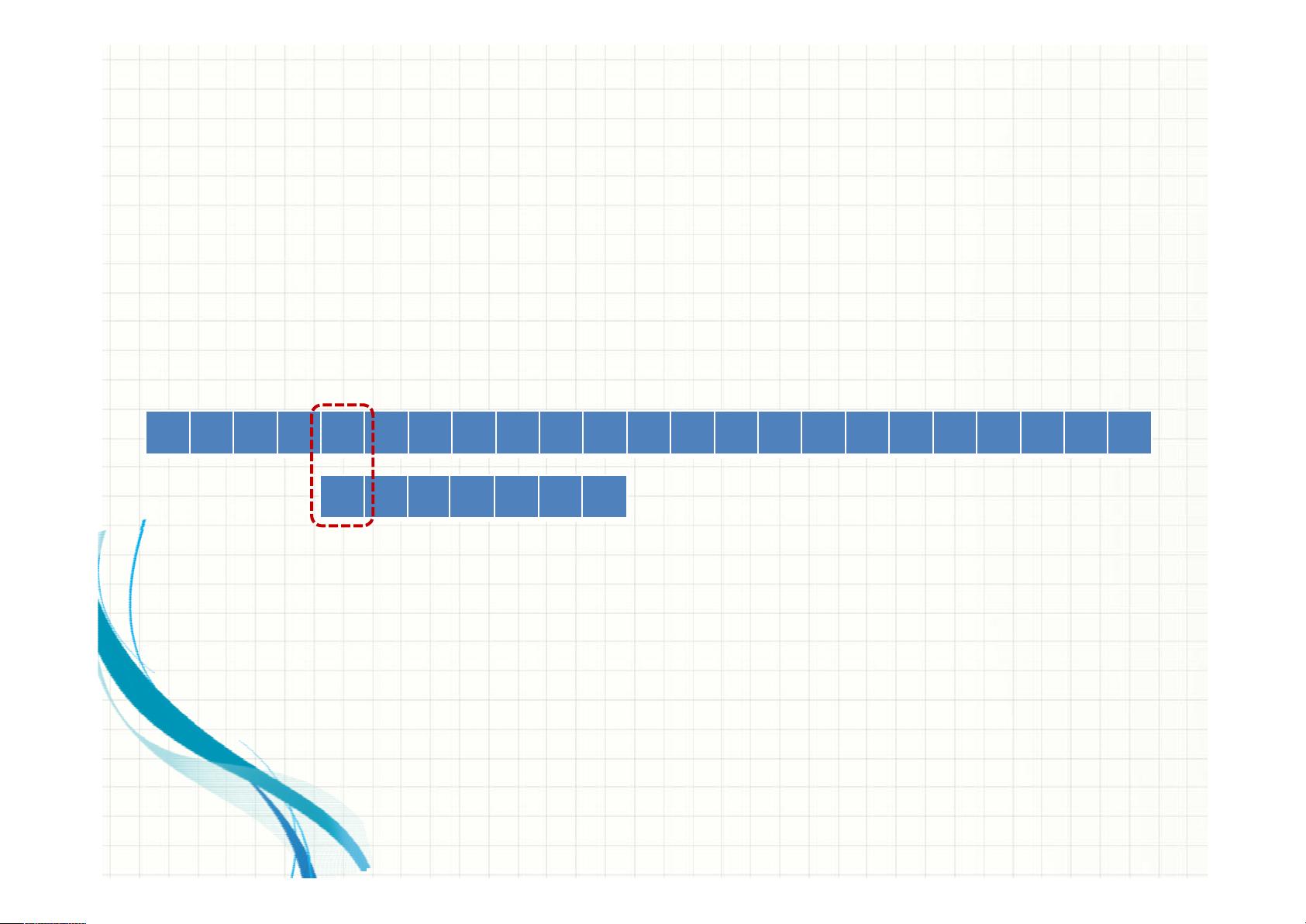
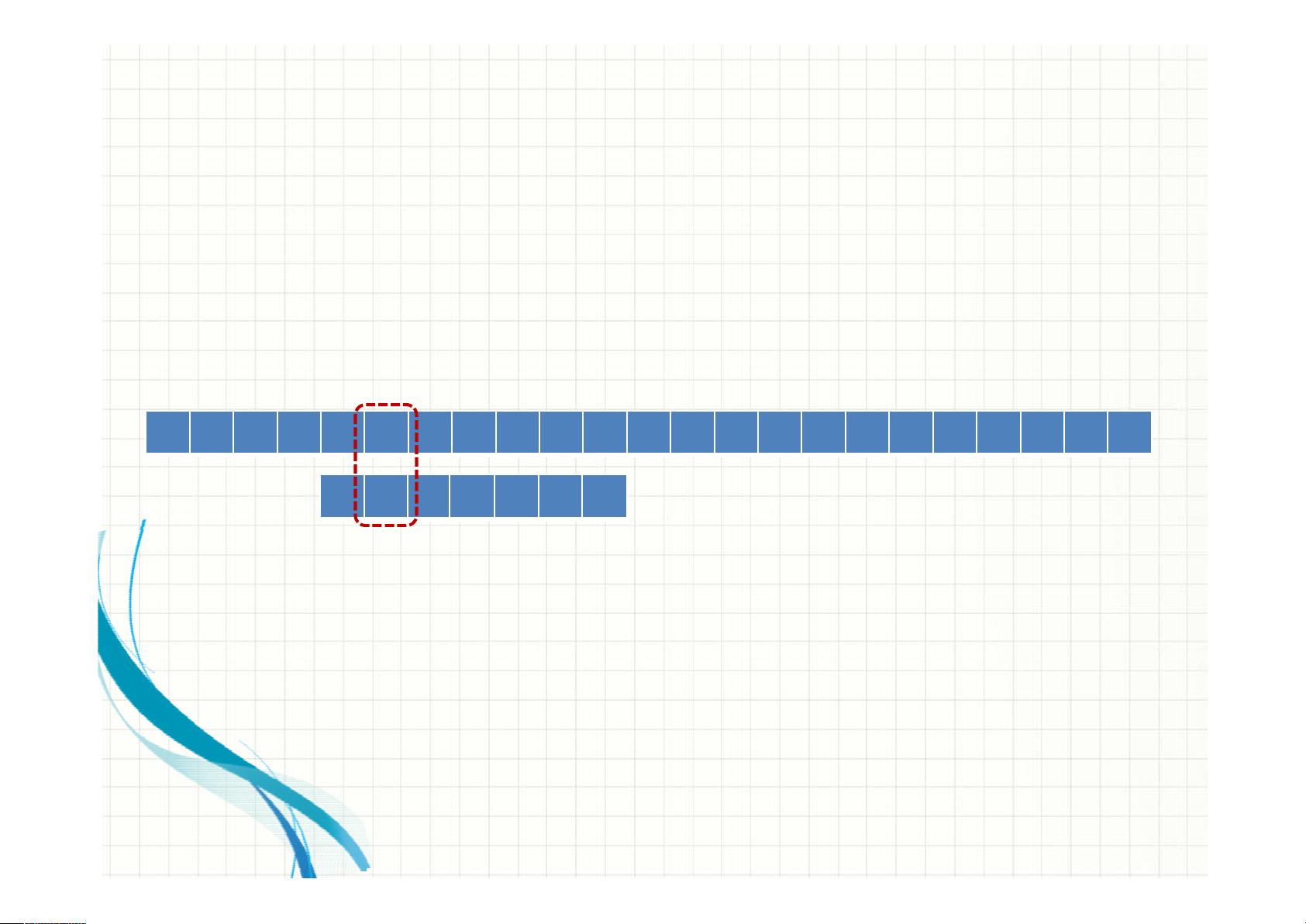
1. 预处理:构建失配表(也称部分匹配表或模式跳跃表),这个表指示了当当前字符不匹配时,应该向前移动多少位。例如,对于字符串P="ABCBDAB",失配表可能为:0, 1, 0, 2, 0, 1, 0。
2. 主循环:遍历主文本字符串S,逐字符与模式字符串P进行比较。如果当前字符匹配,就继续比较下一个字符;如果不匹配,则根据失配表的值,将模式字符串向右移动相应的位置,而不是回溯到主文本的下一个字符。
- 当比较到P[0]与S[i]不匹配时,根据失配表,如果P[0]之前有公共前缀,比如P[-1]与P[0],那么模式字符串P会向前移动失配表中P[0]对应的值,即P向右移动一位(因为P[-1]与S[i-1]匹配)。
- 如果失配表中的值为0,表示没有公共前缀,模式字符串P会整体向右移动一位。
3. 继续比较,直到找到所有匹配或遍历完整个主文本字符串S。
在示例中,我们看到KMP算法如何在字符串T="BBC ABCDAB ABCDABC DABDE"中查找模式P="ABC"的过程。当遇到不匹配时,如"T"中的"D"与"P"中的"A"不匹配,KMP算法会利用失配表确定下一次匹配的起始位置,而不会回溯到已匹配的字符。这样可以避免不必要的比较,提高查找效率。
KMP算法的主要优点是效率高,它的时间复杂度为O(n),其中n是主文本字符串S的长度。它不需要回溯,因此在处理大量数据时比简单的暴力逐个字符比较更为高效。然而,它需要预先计算失配表,这增加了额外的空间复杂度。尽管如此,KMP算法在字符串匹配问题中仍是一种常用的解决方案。"
B B C A B C D A B A B C D A B C D A B D E
A B C D A B D
直到字符串有一个字符,与搜索词
的第一个字符相同为止
。
剩余37页未读,继续阅读
2024-08-23 上传
2023-12-23 上传
2023-12-30 上传
2023-10-16 上传
2023-09-19 上传
2023-11-08 上传

「已注销」
- 粉丝: 0
- 资源: 8
 我的内容管理
展开
我的内容管理
展开







最新资源
- C语言快速排序算法的实现与应用
- KityFormula 编辑器压缩包功能解析
- 离线搭建Kubernetes 1.17.0集群教程与资源包分享
- Java毕业设计教学平台完整教程与源码
- 综合数据集汇总:浏览记录与市场研究分析
- STM32智能家居控制系统:创新设计与无线通讯
- 深入浅出C++20标准:四大新特性解析
- Real-ESRGAN: 开源项目提升图像超分辨率技术
- 植物大战僵尸杂交版v2.0.88:新元素新挑战
- 掌握数据分析核心模型,预测未来不是梦
- Android平台蓝牙HC-06/08模块数据交互技巧
- Python源码分享:计算100至200之间的所有素数
- 免费视频修复利器:Digital Video Repair
- Chrome浏览器新版本Adblock Plus插件发布
- GifSplitter:Linux下GIF转BMP的核心工具
- Vue.js开发教程:全面学习资源指南
