1880-2010年美国婴儿姓名趋势分析
58 浏览量
更新于2024-09-01
1
收藏 497KB PDF 举报
本资源是一份关于1880年至2010年间美国全境婴儿姓名的数据分析项目,主要利用Python编程语言及其相关库进行数据处理和可视化。该项目首先从GitHub仓库中克隆了名为"pydata-book"的代码库,这个库包含了用于婴儿姓名数据分析的文本文件集合。
1. 数据导入与库加载
开始时,项目导入了必要的库,如`numpy`用于数组处理,`pandas`用于数据读取和DataFrame操作,`matplotlib`和`seaborn`用于数据可视化,`rcParams`设置图形参数,`rainbow`用于配置颜色映射,以及`warnings`和`pd.options`用于管理和控制警告信息以及数据展示格式。
2. 数据读取与整合
通过命令行工具`!ls`查看文件夹结构,并使用`pd.read_csv`函数逐年读取`yob`开头的TXT格式文件,这些文件记录了各个年份内的婴儿姓名和性别以及出生数量。将每一年的数据整合到`frames`列表中,然后用`pd.concat`函数合并成一个完整的`names` DataFrame,其中包含姓名、性别、出生次数和年份等信息。
3. 数据预处理与汇总
项目接着对数据进行预处理,使用`pd.DataFrame.pivot_table`方法创建了一个汇总表格,这个函数允许根据特定列(这里是'year')进行分组和聚合,计算出每个姓名在不同年份的总出生次数。这样可以得到全美婴儿姓名的历年趋势。
4. 可视化分析
分析部分可能包括绘制柱状图或线图来展示各个姓名的出生次数随时间的变化,以及性别间的对比。通过颜色映射和交互式图表,可以直观地看出哪些名字在不同时期最受欢迎,以及男女婴名字的流行程度变化。
5. 潜在的探索性分析
进一步的数据探索可能包括分析不同性别间最常出现的姓名,名字的命名模式(如是否随着文化趋势而变化),以及某些特定年份的异常值或热门名字的研究。
这个资源提供了对美国近130年婴儿姓名数据的深入洞察,不仅展示了各年龄段婴儿的名字分布,也揭示了名字选择背后的社会文化变迁。通过数据处理和可视化,研究者能够从中挖掘出关于命名习惯和人口趋势的有价值信息。
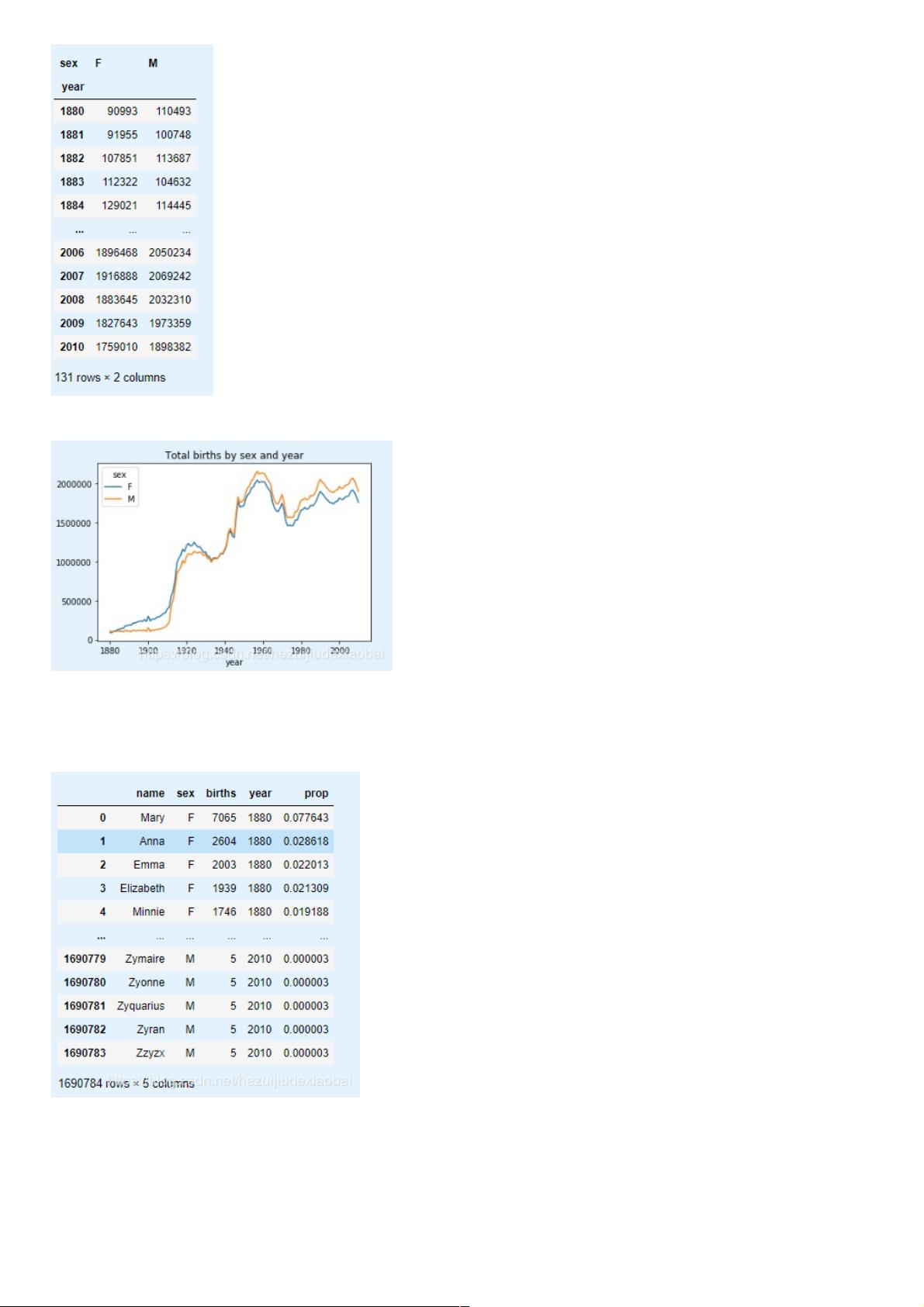
total_births.plot(title='Total births by sex and year')
def add_prop(group):
group['prop'] = group.births / group.births.sum()
return group
names = names.groupby(['year', 'sex']).apply(add_prop)
names
names.groupby(['year', 'sex']).prop.sum()
剩余11页未读,继续阅读
2019-02-15 上传
点击了解资源详情
点击了解资源详情
2009-09-09 上传
2019-09-05 上传
2010-07-22 上传
2021-11-02 上传
2021-07-07 上传

weixin_38550334
- 粉丝: 2
- 资源: 952
 我的内容管理
展开
我的内容管理
展开







最新资源
- Android圆角进度条控件的设计与应用
- mui框架实现带侧边栏的响应式布局
- Android仿知乎横线直线进度条实现教程
- SSM选课系统实现:Spring+SpringMVC+MyBatis源码剖析
- 使用JavaScript开发的流星待办事项应用
- Google Code Jam 2015竞赛回顾与Java编程实践
- Angular 2与NW.js集成:通过Webpack和Gulp构建环境详解
- OneDayTripPlanner:数字化城市旅游活动规划助手
- TinySTM 轻量级原子操作库的详细介绍与安装指南
- 模拟PHP序列化:JavaScript实现序列化与反序列化技术
- ***进销存系统全面功能介绍与开发指南
- 掌握Clojure命名空间的正确重新加载技巧
- 免费获取VMD模态分解Matlab源代码与案例数据
- BuglyEasyToUnity最新更新优化:简化Unity开发者接入流程
- Android学生俱乐部项目任务2解析与实践
- 掌握Elixir语言构建高效分布式网络爬虫
