美国历年婴儿姓名数据探索:1880-2010
66 浏览量
更新于2024-09-01
收藏 497KB PDF 举报
"该资源是关于1880年至2010年全美婴儿姓名的数据集,包含不同性别的婴儿姓名及对应的出生总数。数据来源于GitHub上的'pydata-book'项目,通过Python的数据分析库Pandas、NumPy以及Matplotlib进行处理和可视化。在代码中,首先导入了相关库,然后读取并合并了每年的婴儿姓名数据,并进行了数据预处理,最终生成了 Pivot Table 对整体数据进行分析。"
在数据分析领域,掌握有效的数据处理和可视化技巧至关重要。在这个案例中,我们关注的是一个跨越131年的美国婴儿姓名数据集,包含了1880年至2010年间的婴儿姓名和出生数量,按性别分类。数据集的结构使得我们可以深入研究这一时期的社会文化变迁,例如姓名流行趋势、性别比例变化等。
首先,代码导入了Python数据分析的基础库,如NumPy用于数组操作,Pandas用于数据处理和DataFrame的创建,以及Matplotlib和Seaborn用于数据可视化。`%matplotlib inline`指令使图表在Jupyter Notebook或类似的环境中直接显示。
接着,通过`pd.read_csv()`函数读取TXT格式的文件,每个文件代表一年的数据,其中包含了名字、性别和出生数三列信息。使用`groupby()`方法按性别分组,计算每个性别的总出生数。
为了整合所有年份的数据,代码创建了一个名为`pieces`的空列表,然后遍历每一年的文件,将读取到的DataFrame添加到列表中,并为每一年的数据添加一个额外的列'year'。最后,使用`pd.concat()`函数将所有年份的数据合并成一个大的DataFrame。
在数据预处理阶段,Pandas的`pivot_table`函数被用来将原始数据重塑,创建一个宽格式的表格,其中行是名字,列是年份,值是对应年份的出生数。这样的转换对于分析特定年份的姓名流行度非常有用。
通过这个数据集,我们可以进行多种分析,比如:
1. **时间序列分析**:追踪特定姓名随时间的流行度,揭示姓名流行趋势。
2. **性别比例分析**:比较不同年份男婴和女婴的出生比例,观察性别比例变化。
3. **姓名趋势研究**:找出哪些名字在过去130年间最为流行,或者研究新旧名字的更迭模式。
4. **地域或族裔影响**:如果数据包括地域或族裔信息,可以进一步分析不同群体的命名习惯。
这些分析有助于我们理解社会文化、价值观以及人口统计学的变化,同时,这也是Python数据分析实践的一个典型例子,展示了如何利用Pandas进行数据清洗、整合和初步探索。
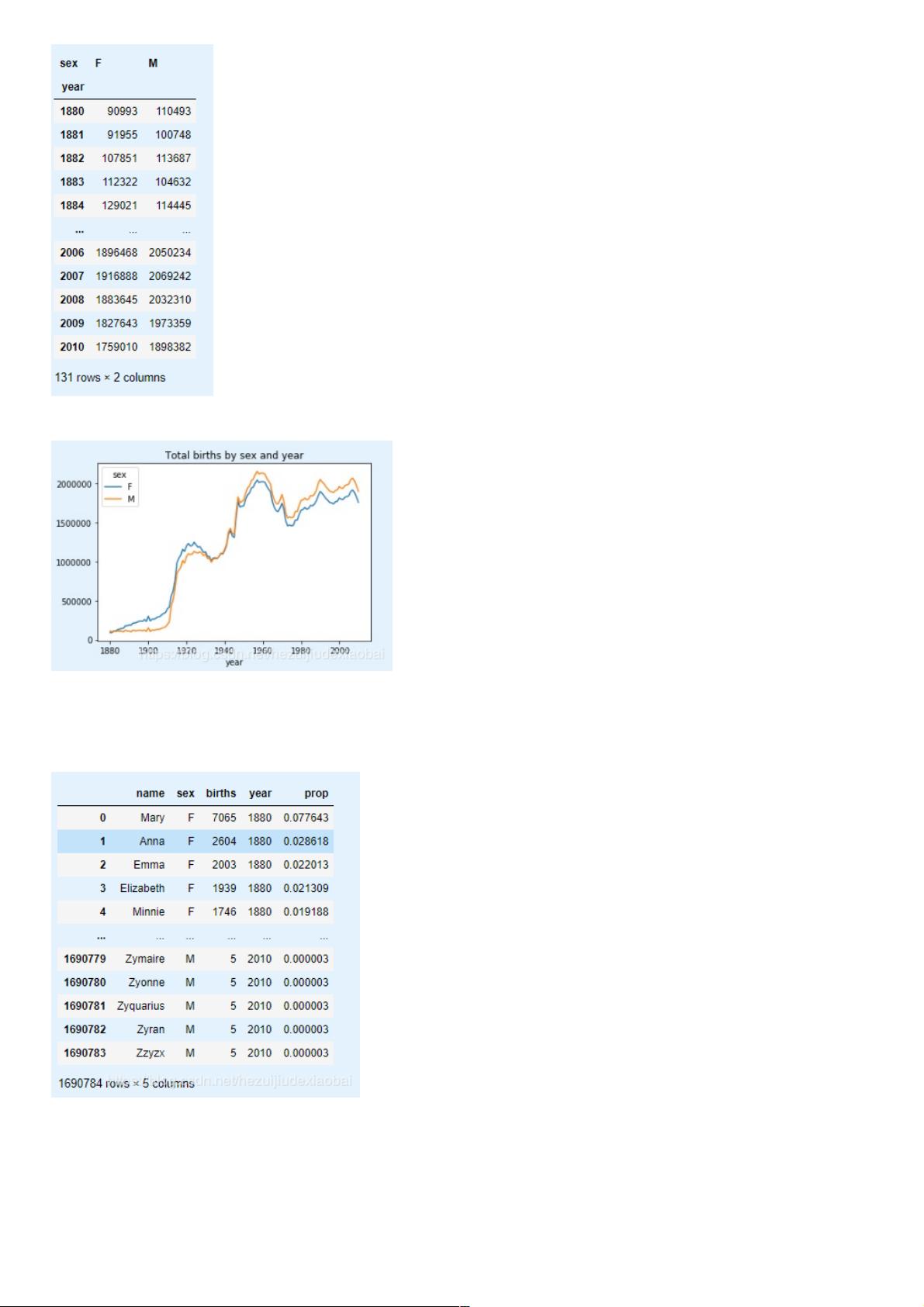
total_births.plot(title='Total births by sex and year')
def add_prop(group):
group['prop'] = group.births / group.births.sum()
return group
names = names.groupby(['year', 'sex']).apply(add_prop)
names
names.groupby(['year', 'sex']).prop.sum()
剩余11页未读,继续阅读
点击了解资源详情
点击了解资源详情
点击了解资源详情
2019-02-15 上传
2009-09-09 上传
2019-09-05 上传
2010-07-22 上传
2021-11-02 上传

weixin_38522552
- 粉丝: 5
- 资源: 922
 我的内容管理
展开
我的内容管理
展开







最新资源
- 俄罗斯RTSD数据集实现交通标志实时检测
- 易语言开发的文件批量改名工具使用Ex_Dui美化界面
- 爱心援助动态网页教程:前端开发实战指南
- 复旦微电子数字电路课件4章同步时序电路详解
- Dylan Manley的编程投资组合登录页面设计介绍
- Python实现H3K4me3与H3K27ac表观遗传标记域长度分析
- 易语言开源播放器项目:简易界面与强大的音频支持
- 介绍rxtx2.2全系统环境下的Java版本使用
- ZStack-CC2530 半开源协议栈使用与安装指南
- 易语言实现的八斗平台与淘宝评论采集软件开发
- Christiano响应式网站项目设计与技术特点
- QT图形框架中QGraphicRectItem的插入与缩放技术
- 组合逻辑电路深入解析与习题教程
- Vue+ECharts实现中国地图3D展示与交互功能
- MiSTer_MAME_SCRIPTS:自动下载MAME与HBMAME脚本指南
- 前端技术精髓:构建响应式盆栽展示网站
