Transformer与注意力机制详解:提升深度学习效率的关键
46 浏览量
更新于2024-06-19
收藏 12.38MB PPTX 举报
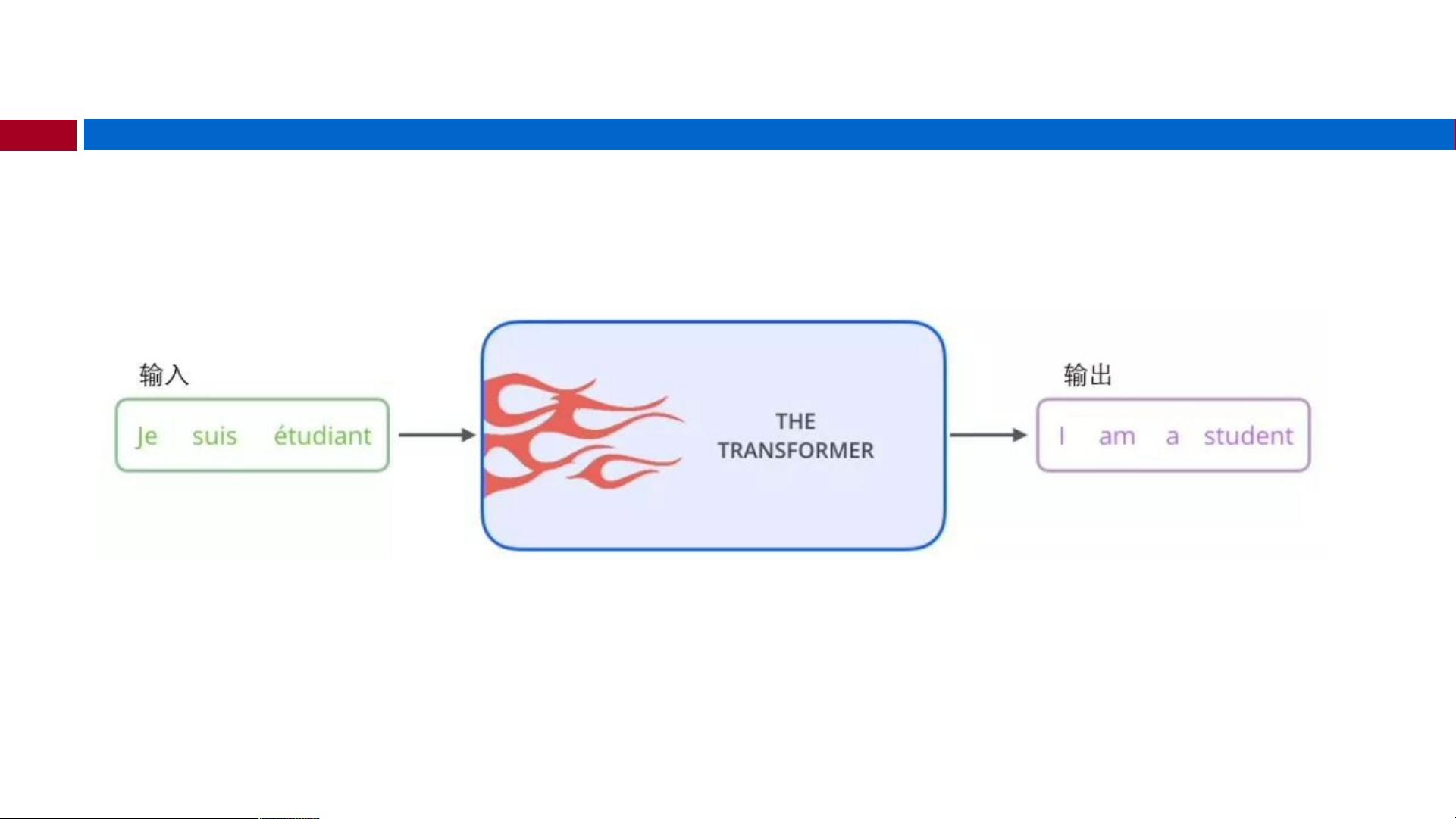
Transformer是一种革命性的神经网络架构,最初由Google的研究者在2017年的论文《Attention is All You Need》中提出,用于自然语言处理(NLP)任务中的序列到序列(Sequence-to-Sequence, Seq2Seq)建模,尤其是在机器翻译(Machine Translation)领域取得了突破性成果。相较于传统的循环神经网络(RNN)或长短期记忆网络(LSTM)和门控循环单元(GRU),Transformer通过注意力机制(Attention)显著提高了模型的计算效率和性能。
1. **Transformer介绍**:
Transformer完全抛弃了RNN中的循环结构,引入了自注意力(自注意力机制允许每个位置的输入同时考虑所有其他位置的信息)和多头注意力(Multi-Head Attention),这些组件使得模型能够在处理序列数据时无需考虑过去的状态,从而实现真正的并行计算。这种并行计算的优势使得Transformer在大规模数据集上的训练速度远超RNN。
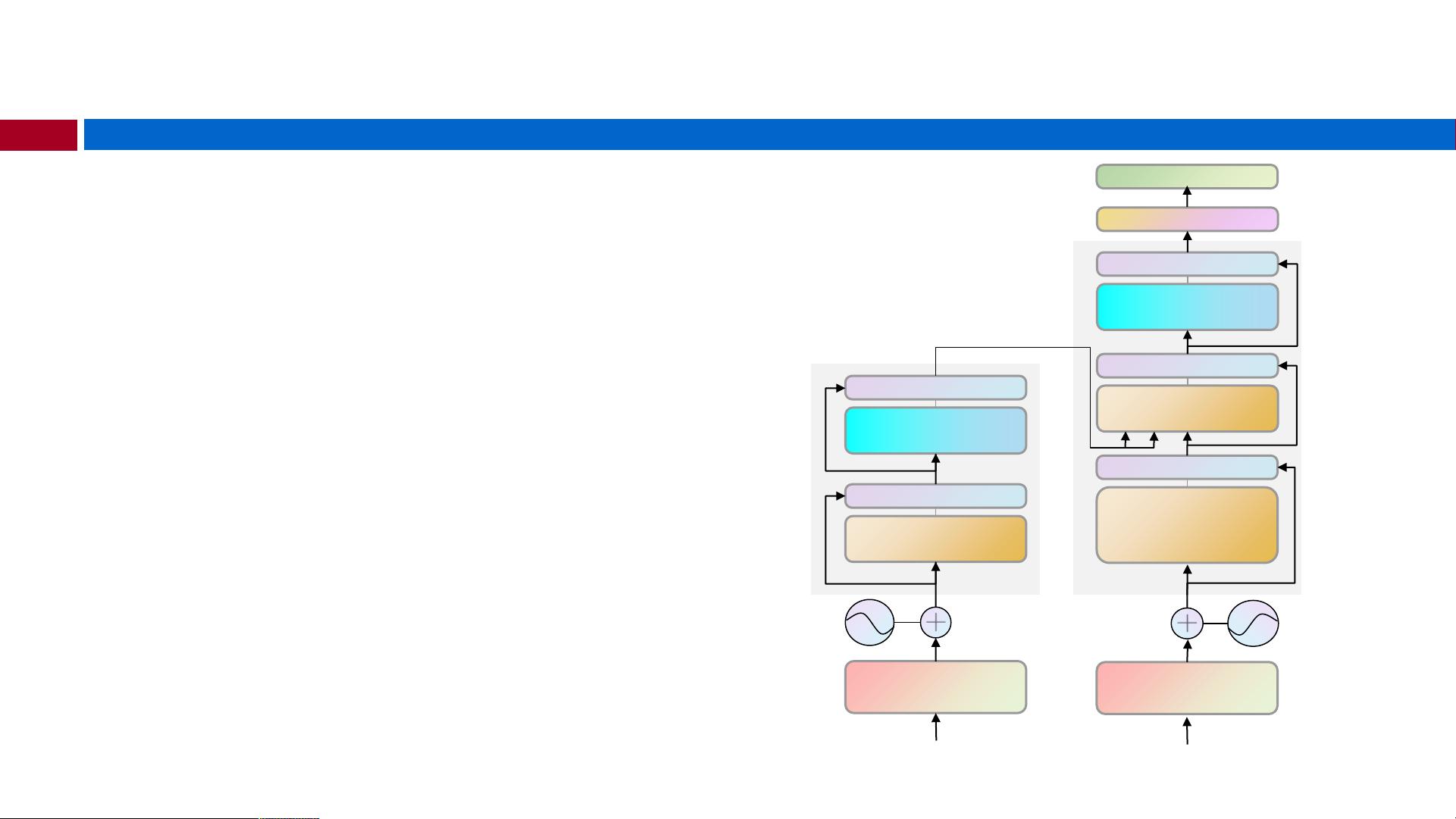
2. **Seq2Seq任务与Encoder-Decoder模型**:
在Seq2Seq任务中,Transformer通常包含一个编码器(Encoder)负责捕获输入序列的全局上下文,将其转换为固定大小的上下文向量,然后解码器(Decoder)利用这个上下文向量生成输出序列。输入和输出序列可能长度不同,这要求模型具有动态适应性。
3. **注意力机制**:
重点是注意力机制,它模仿了人类大脑处理信息的方式。在Transformer中,Attention计算涉及到三个关键元素:Query(Q)、Key(K)和Value(V)。每个位置的Query会与序列中所有Key进行比较,计算出每个位置对其他位置的“注意力权重”,然后根据这些权重加权求和值,以获取最相关的特征表示。这样,模型能够对每个位置给予不同的关注,提高信息处理的精准度。
4. **Attention的优点**:
- **参数效率**:由于注意力机制的局部连接,相比于卷积神经网络(CNN)和RNN,Transformer的参数数量更少,减少了对计算资源的需求,有助于模型的训练和部署。
- **计算速度**:RNN的递归性质导致它们的计算不能并行,而Transformer的注意力机制可以独立地处理每个位置,显著提升了计算速度,特别是在处理长序列时。
Transformer通过引入注意力机制,不仅解决了长距离依赖问题,还实现了高效的并行化处理,使其在自然语言处理等领域展现出强大的性能和应用潜力。Transformer架构的引入开启了新一代序列模型的新篇章,为深度学习中的许多任务带来了革新性的解决方案。
10
2017年google的机器翻译团队
在NIPS上发表了Attention is
all you need的文章,开创性地
提出了在序列转录领域,完全
抛弃CNN和RNN,只依赖
Attention-注意力结构的简单的
网络架构,名为Transformer;
论文实现的任务是机器翻译。
Transformer结
构
Multi-Head
Attention
Add&Norm
Input
Embedding
Output
Embedding
Feed
Forward
Add&Norm
Masked
Multi-Head
Attention
Add&Norm
Multi-Head
Attention
Add&Norm
Feed
Forward
Add&Norm
Linear
Softmax
Inputs
Outputs(shiftedright)
Positional
Encoding
Positional
Encoding
1.Transformer介绍
剩余57页未读,继续阅读
2021-01-07 上传
2023-02-07 上传
2023-03-29 上传
2023-10-18 上传
2023-07-20 上传
2023-05-31 上传
2024-06-19 上传
2023-03-28 上传

兔子牙丫丫
- 粉丝: 233
- 资源: 4
 我的内容管理
展开
我的内容管理
展开







最新资源
- Java毕业设计项目:校园二手交易网站开发指南
- Blaseball Plus插件开发与构建教程
- Deno Express:模仿Node.js Express的Deno Web服务器解决方案
- coc-snippets: 强化coc.nvim代码片段体验
- Java面向对象编程语言特性解析与学生信息管理系统开发
- 掌握Java实现硬盘链接技术:LinkDisks深度解析
- 基于Springboot和Vue的Java网盘系统开发
- jMonkeyEngine3 SDK:Netbeans集成的3D应用开发利器
- Python家庭作业指南与实践技巧
- Java企业级Web项目实践指南
- Eureka注册中心与Go客户端使用指南
- TsinghuaNet客户端:跨平台校园网联网解决方案
- 掌握lazycsv:C++中高效解析CSV文件的单头库
- FSDAF遥感影像时空融合python实现教程
- Envato Markets分析工具扩展:监控销售与评论
- Kotlin实现NumPy绑定:提升数组数据处理性能
