Spark源码深度解析:Shuffle过程与性能优化
113 浏览量
更新于2024-08-27
1
收藏 204KB PDF 举报
"Spark源码系列(六)Shuffle的过程解析"
在Spark中,Shuffle是一个至关重要的操作,它发生在分布式计算中的数据重新分配阶段,通常在执行如reduceByKey、groupByKey这样的聚合操作时触发。Shuffle是性能瓶颈的主要来源,但也是实现复杂计算逻辑的关键步骤。本文将深入探讨Shuffle过程的划分、中间结果的存储以及数据的拉取方法。
Shuffle过程的划分主要涉及到数据如何在不同的节点之间重新分布。当调用reduceByKey时,我们可以通过指定`numPartitions`参数来自定义reduce任务的数量。默认情况下,如果不指定这个参数,其分区策略会根据以下规则确定:
1. 如果已经定义了自定义的分区器`partitioner`,那么将按照这个分区器来进行分区,确保相同key的数据被发送到同一个reduce任务处理。
2. 若未定义分区器,但设置了配置`spark.default.parallelism`,则会使用哈希分区器,且reduce任务的数量等于设置的并行度。
3. 如果连`spark.default.parallelism`也没有设置,系统会根据输入数据的原始分片数量(如Hadoop输入数据的块大小)来决定reduce任务的数量。这可能会导致大量的小文件问题,因为每个原始分片都会成为一个reduce任务,影响效率。
在Shuffle过程中,中间结果的存储通常采用MapReduce中的“Map阶段”和“Reduce阶段”的概念。在Map阶段,每个节点上的数据会被局部处理,并根据分区规则生成键值对。这些键值对被写入磁盘,形成临时文件,称为“shuffle文件”。然后在Reduce阶段,各个节点会根据需要拉取其他节点上属于同一分区的键值对,进行合并和归约操作。
数据拉取过程,也叫shuffle read,涉及到网络传输。Spark通过Map端的partitioner和Reduce端的fetcher协同工作,将数据从一个节点传输到另一个节点。在fetcher中,数据会被分成多个块,每个块通过网络异步拉取,以提高整体性能。同时,为了防止内存压力过大,Spark还实现了内存溢出到磁盘的机制,即DiskBlockManager,确保即使在内存不足的情况下也能完成shuffle过程。
Spark的Shuffle管理机制还包括了优化措施,例如使用内存中的缓存(shuffle spill to memory)减少磁盘IO,以及压缩中间结果以节省网络带宽。然而,Shuffle操作的开销仍然是显著的,因此理解其工作原理对于优化Spark应用程序的性能至关重要。合理地设置reduce任务的数量、利用数据本地性、以及调整内存和磁盘策略,都能有效改善Shuffle的性能表现。
Spark源码系列(六)源码系列(六)Shuffle的过程解析的过程解析
Spark大会上,所有的演讲嘉宾都认为shuffle是最影响性能的地方,但是又无可奈何。之前去百度面试hadoop的时候,也被问
到了这个问题,直接回答了不知道。这篇文章主要是沿着下面几个问题来开展:shuffle过程的划分?shuffle的中间结果如何存
储?shuffle的数据如何拉取过来?
Shuffle过程的划分
Spark的操作模型是基于RDD的,当调用RDD的reduceByKey、groupByKey等类似的操作的时候,就需要有shuffle了。再拿
出reduceByKey这个来讲。
def reduceByKey(func: (V, V) => V, numPartitions: Int): RDD[(K, V)] = {
reduceByKey(new HashPartitioner(numPartitions), func)
}
reduceByKey的时候,我们可以手动设定reduce的个数,如果不指定的话,就可能不受控制了。
def defaultPartitioner(rdd: RDD[_], others: RDD[_]*): Partitioner = {
val bySize = (Seq(rdd) ++ others).sortBy(_.partitions.size).reverse
for (r <- bySize if r.partitioner.isDefined) {
return r.partitioner.get
}
if (rdd.context.conf.contains("spark.default.parallelism")) {
new HashPartitioner(rdd.context.defaultParallelism)
} else {
new HashPartitioner(bySize.head.partitions.size)
}
}
如果不指定reduce个数的话,就按默认的走:
1、如果自定义了分区函数partitioner的话,就按你的分区函数来走。
2、如果没有定义,那么如果设置了spark.default.parallelism,就使用哈希的分区方式,reduce个数就是设置的这个值。
3、如果这个也没设置,那就按照输入数据的分片的数量来设定。如果是hadoop的输入数据的话,这个就多了。。。大家可要
小心啊。
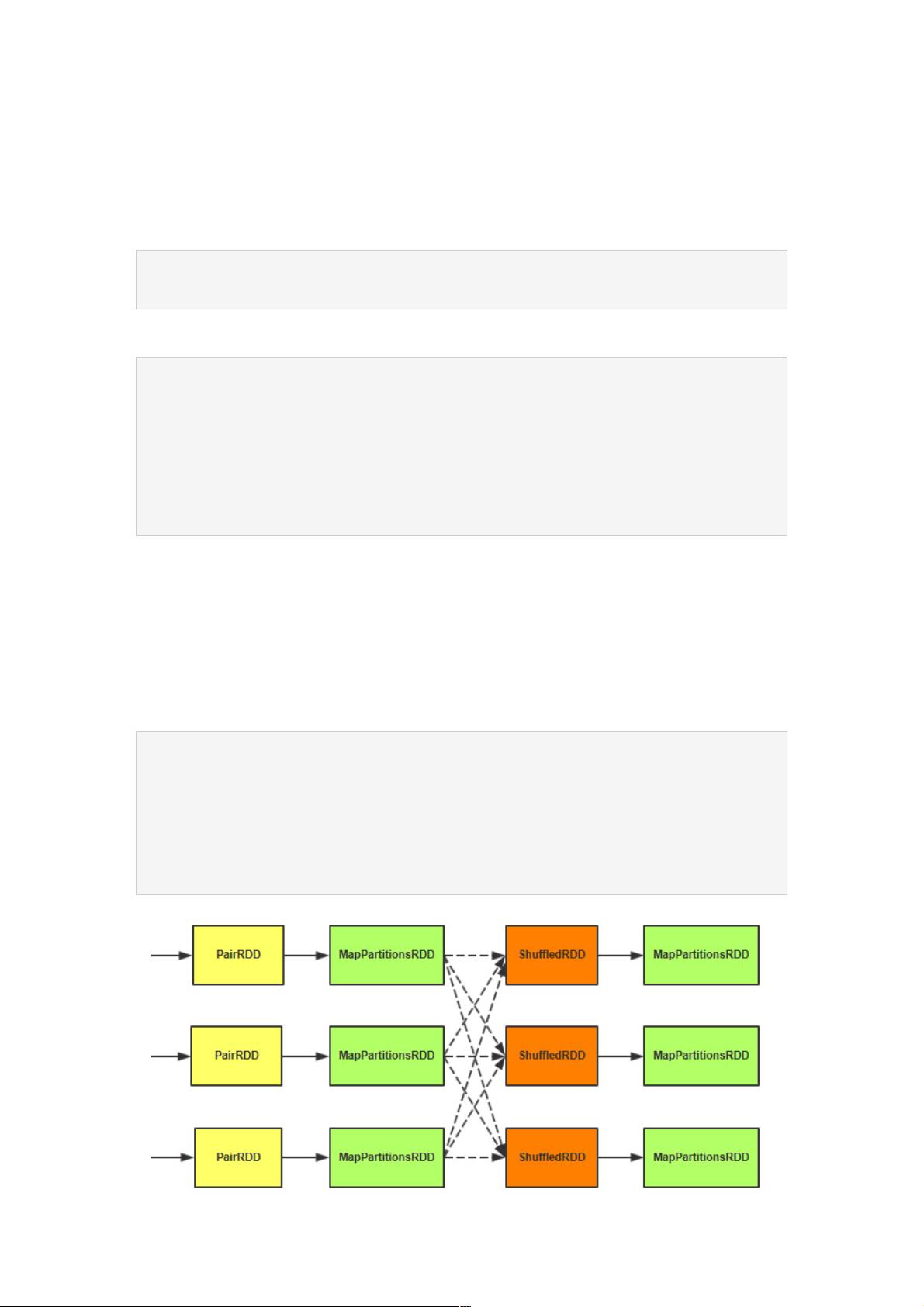
设定完之后,它会做三件事情,也就是之前讲的3次RDD转换。
//map端先按照key合并一次
val combined = self.mapPartitionsWithContext((context, iter) => {
aggregator.combineValuesByKey(iter, context)
}, preservesPartitioning = true)
//reduce抓取数据
val partitioned = new ShuffledRDD[K, C, (K, C)](combined, partitioner).setSerializer(serializer)
//合并数据,执行reduce计算
partitioned.mapPartitionsWithContext((context, iter) => {
new InterruptibleIterator(context, aggregator.combineCombinersByKey(iter, context))
}, preservesPartitioning = true)
1、在第一个MapPartitionsRDD这里先做一次map端的聚合操作。
下载后可阅读完整内容,剩余6页未读,立即下载
点击了解资源详情
点击了解资源详情
点击了解资源详情
2018-05-22 上传
2017-06-15 上传
2018-11-29 上传
2017-11-16 上传
2021-12-05 上传
点击了解资源详情

weixin_38581447
- 粉丝: 8
- 资源: 911
 我的内容管理
展开
我的内容管理
展开







最新资源
- PyPI 官网下载 | trading_calendars-1.11.11.tar.gz
- blog:使用 Jekyll 和 Mathjax 编写方程式的每日计算机视觉博客
- Java课程设计《Swing学生管理系统》.zip
- wish_together
- LED驱动电路设计.rar-综合文档
- Clicky Monitor-crx插件
- 手机海报展示样机PSD
- 毕业设计&课设-惯性导航系统(INS)和GPS组合导航MATLAB程序。.zip
- IWA-CA2-ID_2017104:IWA CA2
- DevSecOps:用于测试和演示目的的回购
- Bookmarkanator-Core:一个跨平台工具,不仅可以为网址添加书签,还可以为系统文件和文件夹以及文本注释添加书签
- jquery网站瀑布流插件masonry
- followup:在PrestaShop 1.6中通过每日定制的电子邮件跟您的客户进行跟进
- knot:使用 Google 表单和电子表格制作的 URL Shortner
- 死锁检测:死锁检测的Java实现
- MF0001全套毕业设计(含论文,源码,使用说明).zip
