机器学习算法实战剖析:回归、分类与聚类优缺点
需积分: 45 153 浏览量
更新于2024-07-18
2
收藏 271KB DOCX 举报
回归、分类与聚类是机器学习中三大核心任务,它们分别对应着对数值型数据的预测、离散型数据的分类和数据群体的分组。在深入理解这些算法之前,我们需要了解"没有免费午餐"的理论,即不存在一种通用的机器学习算法能适应所有问题,算法的选择取决于具体任务和数据特性。
回归方法是监督学习的一种,专注于预测连续的数值输出,例如房价、经济指标或学生成绩。线性回归是最基础的回归算法,通过拟合一条直线(在二维空间中)或超平面(多维空间)来描述数据之间的关系。为了防止过拟合,正则化技术如L1和L2正则化被引入,通过添加惩罚项控制模型复杂度。
分类方法则是处理离散输出的问题,例如文本情感分析、图像识别或疾病诊断。常见的分类算法包括逻辑回归(适用于二分类)、决策树、随机森林(集成多个决策树)、支持向量机(SVM)和各种深度学习模型(如卷积神经网络和循环神经网络)。选择哪种分类算法通常取决于数据的特征、类别数量以及算法的计算效率。
聚类方法则是无监督学习,目标是将数据分成自然的组别,而无需事先知道每个组的标签。K-means是最经典的聚类算法,通过迭代优化将数据分配到预设数量的簇中;而层次聚类则可以自上而下或自下而上构建聚类层次。密度聚类算法,如DBSCAN,根据数据点的邻域密度进行聚类。
在实际应用中,选择合适的机器学习任务和算法至关重要。理解这些任务的特性和适用场景可以帮助开发者做出明智的选择。例如,如果目标是预测连续数值,那么回归方法会是首选;如果需要对数据进行分类,就需要考虑各类分类算法的性能和数据的特异性;而当面对未标记数据时,聚类则可以帮助揭示数据内部的结构。
回归、分类和聚类方法各有优势和局限,理解并结合实际场景选择合适的算法是提高机器学习模型效果的关键。同时,不断更新知识库,关注新算法的发展,有助于保持竞争力和解决问题的能力。
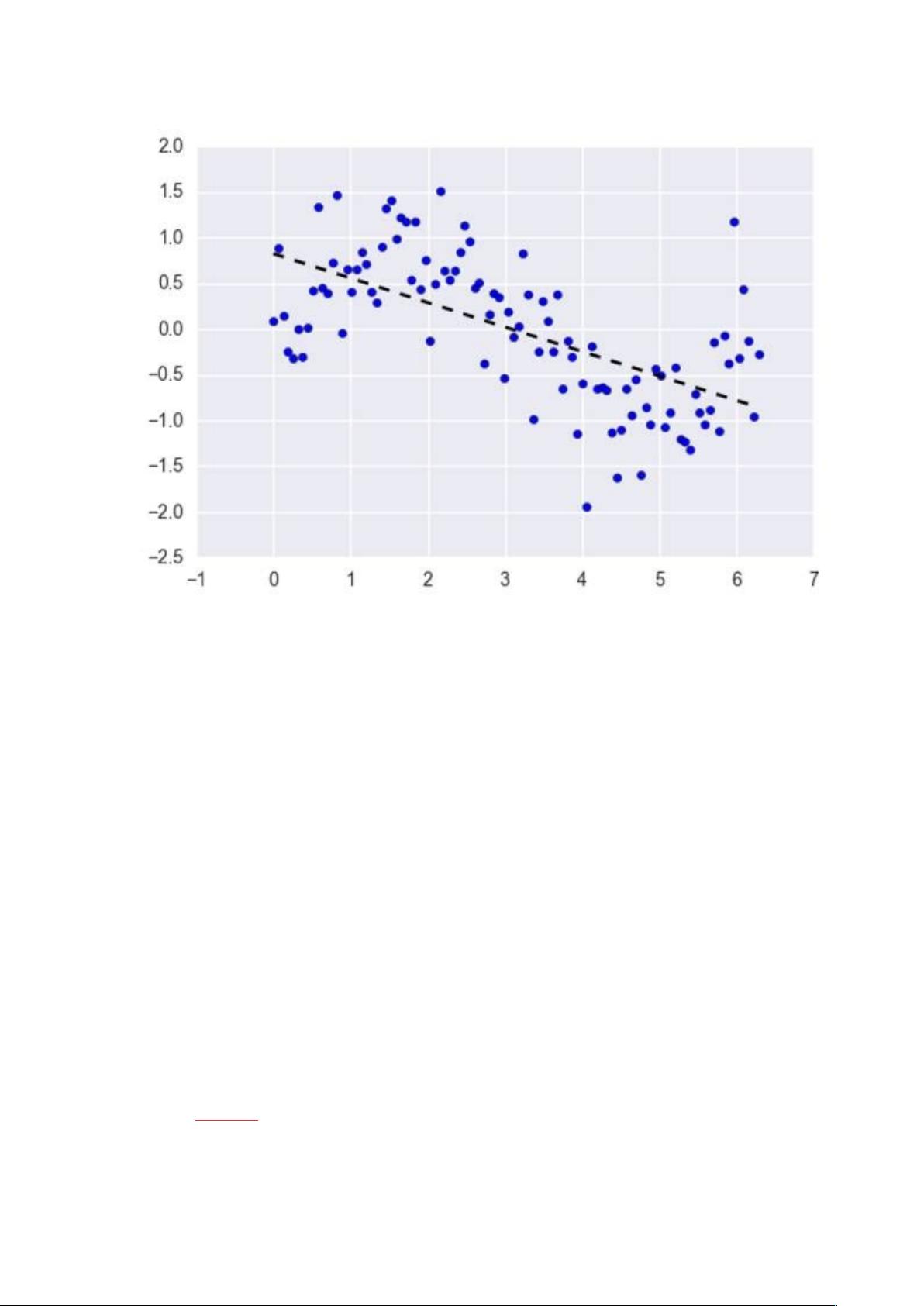
在实践中,简单的线性回归通常被使用正则化的回归方法(LASSO、Ridge 和
Elastic-Net)所代替。正则化其实就是一种对过多回归系数采取惩罚以减少过
拟合风险的技术。当然,我们还得确定惩罚强度以让模型在欠拟合和过拟合之
间达到平衡。
o 优点:线性回归的理解与解释都十分直观,并且还能通过正则化来降低
过拟合的风险。另外,线性模型很容易使用随机梯度下降和新数据更新
模型权重。
o 缺点:线性回归在变量是非线性关系的时候表现很差。并且其也不够灵
活以捕捉更复杂的模式,添加正确的交互项或使用多项式很困难并需要
大量时间。
Python 实现:http://scikit-learn.org/stable/modules/linear_model.html
R 实现:https://cran.r-project.org/web/packages/glmnet/index.html
剩余17页未读,继续阅读
2024-01-12 上传
2023-11-09 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情

wcr0537
- 粉丝: 1
- 资源: 27
 我的内容管理
展开
我的内容管理
展开







最新资源
- BottleJS快速入门:演示JavaScript依赖注入优势
- vConsole插件使用教程:输出与复制日志文件
- Node.js v12.7.0版本发布 - 适合高性能Web服务器与网络应用
- Android中实现图片的双指和双击缩放功能
- Anum Pinki英语至乌尔都语开源词典:23000词汇会话
- 三菱电机SLIMDIP智能功率模块在变频洗衣机的应用分析
- 用JavaScript实现的剪刀石头布游戏指南
- Node.js v12.22.1版发布 - 跨平台JavaScript环境新选择
- Infix修复发布:探索新的中缀处理方式
- 罕见疾病酶替代疗法药物非临床研究指导原则报告
- Node.js v10.20.0 版本发布,性能卓越的服务器端JavaScript
- hap-java-client:Java实现的HAP客户端库解析
- Shreyas Satish的GitHub博客自动化静态站点技术解析
- vtomole个人博客网站建设与维护经验分享
- MEAN.JS全栈解决方案:打造MongoDB、Express、AngularJS和Node.js应用
- 东南大学网络空间安全学院复试代码解析
