Cassandra分布式数据库深度解析:模型与源代码探索
"Cassandra分布式模型与源代码分析"
Cassandra是一个强大的开源分布式数据库系统,它融合了Dynamo的Key/Value特性和Bigtable的列族(Column Family)数据模型。这个系统最初由Facebook开发,目的是处理大规模的数据存储需求,目前已被Twitter、Facebook等公司广泛采用。Cassandra的主要特点是其高度灵活的模式设计、出色的可扩展性以及对多数据中心的支持。
1. **灵活的模式设计**
Cassandra允许用户在运行时动态地添加或删除字段,无需预先定义严格的schema。这种灵活性使得它能够适应不断变化的数据需求,对于那些需要频繁调整数据结构的应用尤其适用。
2. **分布式特性**
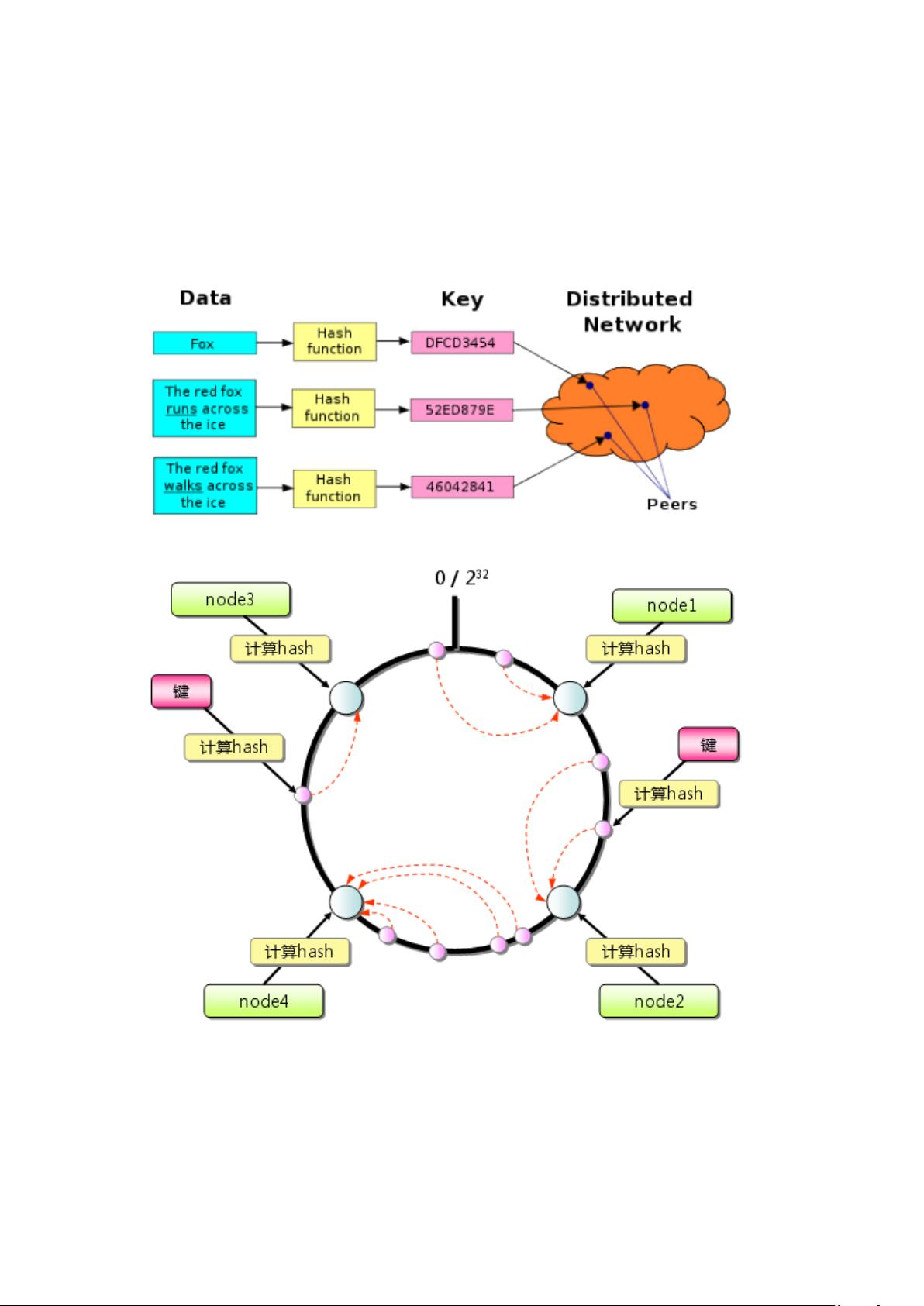
Cassandra的核心是分布式网络服务,它将数据分布在多个节点上,实现了数据的复制和分布。每个节点都可以执行读写操作,并且通过Gossip协议进行节点间的通信和状态同步,确保了高可用性和容错性。即使单个节点出现故障,整个集群仍能继续提供服务。
3. **基于列的结构化**
与传统的行式数据库不同,Cassandra采用列族数据模型,数据以键值对的形式存储,键可以进一步细分为行键和列键。这种结构有利于高效地进行范围查询和列选择,减少了不必要的数据传输。
4. **高可扩展性**
Cassandra的水平扩展能力非常出色,只需要向集群中添加新的节点,系统就能自动平衡负载,将数据分散到新节点上。无需停机、修改查询或手动迁移数据。
5. **多数据中心支持**
通过在多个地理位置部署数据中心,Cassandra可以实现跨区域的数据复制,确保在某个数据中心出现问题时,其他数据中心仍能提供服务,增强了系统的健壮性。
6. **范围查询与列表数据结构**
Cassandra支持范围查询,用户可以根据键的范围来检索数据。此外,其混合模式还允许使用超级列(Super Column),形成类似五维哈希的数据结构,进一步增强了数据组织的灵活性。
7. **分布式写操作**
写入Cassandra的数据会被复制到多个节点,确保了数据的一致性和可靠性。读操作则根据一致性级别路由到适当的节点,提供不同的读取性能和数据新鲜度的权衡。
8. **应用案例**
在实际应用中,Twitter和Facebook等社交媒体平台利用Cassandra处理海量的用户生成数据,如时间线、消息和用户偏好等。
通过对Cassandra的源代码分析,开发者可以深入了解其内部工作原理,优化查询性能,解决潜在的问题,并根据具体需求进行定制化开发。Cassandra是一个强大的工具,适合处理大规模、分布式的数据存储和检索任务。

2.8.5.7Existing Cluster (Upgrade from 0.6)
To provide some backwards compatibility, we've provided a JMX method in
the StorageServiceMBean that can be used to manually load schema definitions
from storage-conf.xml. This is a one-shot operation though, and will only work
on a system that contains no existing migrations. If you are upgrading a cluster,
you will probably only have to do this for one node (a seed). Gossip will take
care of promulgating the changes to the rest of the nodes as they come online.
For those who dont know how to do it (like me):
ps aux | grep cassandra # get pid of cassandra
jconsole PID
MBeans -> org.apache.cassandra.service -> StorageService -> Operations ->
loadSchemaFromYAML
2.8.5.8Concurrency
It is entirely possible and expected that a node will receive migration pushes
from multiple nodes. Because of this, all migrations are applied on a
single-threaded stage and versions are checked throughout to make sure that
no migration is applied twice, and no migration is applied out of sync.
Each migration knows the version UUID of the migration that immediately
precedes it. If a node is asked to apply a migration and its current version
UUID does not match the last version UUID of the migration, the migration is
discarded.
One weakness of this model is that it is vulnerable if a new update starts
before another update is promulgated to all live nodes--only one migration can
be active within a cluster at any time. One way to get around this is to choose
one node and only initiate migrations through it.



剩余100页未读,继续阅读
2023-06-11 上传
2023-05-24 上传
2023-05-17 上传
2023-03-20 上传
2023-06-08 上传
2023-06-11 上传
2023-07-11 上传
2023-05-05 上传
2023-03-30 上传

weishiym
- 粉丝: 27
- 资源: 9
 我的内容管理
展开
我的内容管理
展开







最新资源
- Postman安装与功能详解:适用于API测试与HTTP请求
- Dart打造简易Web服务器教程:simple-server-dart
- FFmpeg 4.4 快速搭建与环境变量配置教程
- 牛顿井在围棋中的应用:利用牛顿多项式求根技术
- SpringBoot结合MySQL实现MQTT消息持久化教程
- C语言实现水仙花数输出方法详解
- Avatar_Utils库1.0.10版本发布,Python开发者必备工具
- Python爬虫实现漫画榜单数据处理与可视化分析
- 解压缩教材程序文件的正确方法
- 快速搭建Spring Boot Web项目实战指南
- Avatar Utils 1.8.1 工具包的安装与使用指南
- GatewayWorker扩展包压缩文件的下载与使用指南
- 实现饮食目标的开源Visual Basic编码程序
- 打造个性化O'RLY动物封面生成器
- Avatar_Utils库打包文件安装与使用指南
- Python端口扫描工具的设计与实现要点解析
