深度学习中的噪声标签处理与α-池化研究
需积分: 9 180 浏览量
更新于2024-09-07
收藏 7.95MB PDF 举报
"这篇论文探讨了深度学习中的噪声标签问题,并提出了一种新的池化方法——广义无序池化(Generalized Orderless Pooling),它在训练过程中可以学习到最优的池化策略。此外,该研究还提供了一种可视化决策的新方法,能够识别出对测试图像预测影响最大的训练图像部分,有助于理解和分析模型决策的依据。"
在当前的深度学习领域,卷积神经网络(CNN)架构已经成为许多计算机视觉任务的核心。平均池化(Average Pooling)作为一种常用的特征编码步骤,通常被用于CNN的最后层。然而,在细粒度识别(fine-grained recognition)任务中,如鸟类物种识别等,更复杂的全局表示,如双线性池化(Bilinear Pooling),已经展现出更好的性能。
在这篇名为“noise label paper”的研究中,作者们对平均池化和双线性池化进行了泛化,提出了“α-池化”(α-Pooling)。α-池化允许在训练过程中学习到最佳的池化策略,这使得网络能根据数据自动调整其池化方式,从而适应不同的任务需求,提高了模型的适应性和泛化能力。
除了新颖的池化方法,论文还引入了一种可视化技术,可以揭示模型决策背后的图像区域影响。这项技术能够标识出训练集中哪些部分对特定测试图像的预测结果影响最大。这对于用户来说,可以提供决策的解释性,增强模型的可信度。同时,对于研究人员来说,这是一种深入理解模型如何利用不同语义部分进行决策的有力工具。例如,通过这种方法,研究者发现更高容量的VGG16模型在识别鸟类时,更侧重于鸟的头部特征,而相对低容量的VGG-M模型可能关注的区域则不同。
这项工作在深度学习模型的优化和解释性方面迈出了重要的一步,对于提升模型的性能和理解模型的决策过程具有重要意义。通过学习适应性的池化策略和可视化决策过程,未来的研究者可以更好地调整和解释他们的模型,这对于提升模型的准确性和透明度至关重要。
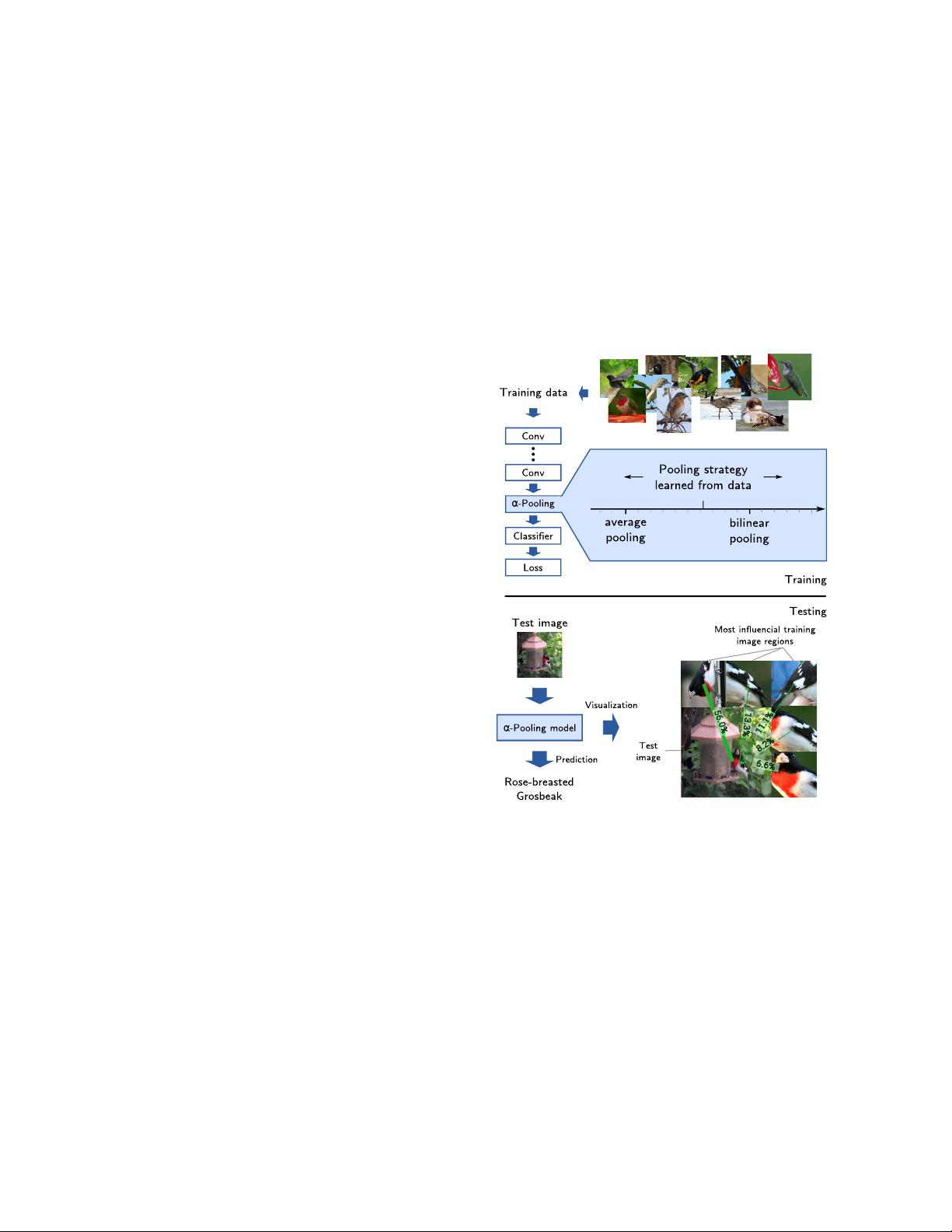
Generalized orderless pooling performs implicit salient matching
Marcel Simon
1
, Yang Gao
2
, Trevor Darrell
2
, Joachim Denzler
1
, Erik Rodner
3
1
Computer Vision Group, University of Jena, Germany
2
EECS, UC Berkeley, USA
3
Corporate Research and Technology, Carl Zeiss AG
{marcel.simon, joachim.denzler}@uni-jena.de {yg, trevor}@eecs.berkeley.edu
Abstract
Most recent CNN architectures use average pooling as
a final feature encoding step. In the field of fine-grained
recognition, however, recent global representations like bi-
linear pooling offer improved performance. In this paper,
we generalize average and bilinear pooling to “α-pooling”,
allowing for learning the pooling strategy during training.
In addition, we present a novel way to visualize decisions
made by these approaches. We identify parts of training
images having the highest influence on the prediction of a
given test image. It allows for justifying decisions to users
and also for analyzing the influence of semantic parts. For
example, we can show that the higher capacity VGG16
model focuses much more on the bird’s head than, e.g.,
the lower-capacity VGG-M model when recognizing fine-
grained bird categories. Both contributions allow us to an-
alyze the difference when moving between average and bi-
linear pooling. In addition, experiments show that our gen-
eralized approach can outperform both across a variety of
standard datasets.
1. Introduction
Deep architectures are characterized by interleaved con-
volution layers to compute intermediate features and pool-
ing layers to aggregate information. Inspired by recent re-
sults in fine-grained recognition [19, 10] showing certain
pooling strategies offered equivalent performance as clas-
sic models involving explicit correspondence, we investi-
gate here a new pooling layer generalization for deep neu-
ral networks suitable both for fine-grained and more generic
recognition tasks.
Fine-grained recognition developed from a niche re-
search field into a popular topic with numerous applications,
ranging from automated monitoring of animal species [9]
to fine-grained recognition of cloth types [8]. The defin-
ing property of fine-grained recognition is that all possi-
ble object categories share a similar object structure and
hence similar object parts. Since the objects do not sig-
Figure 1. We present the novel pooling strategy α-pooling, which
replaces the final average pooling or bilinear pooling layer in
CNNs. It allows for a smooth combination of average and bilinear
pooling techniques. The optimal pooling strategy can be learned
during training to optimally adapt to the properties of the task. In
addition, we present a novel way to visualize predictions of α-
pooling-based classification decisions. It allows in particular for
analyzing incorrect classification decisions, which is an important
addition to all widely used orderless pooling strategies.
nificantly differ in the overall shape, subtle differences in
the appearance of an object part can likely make the differ-
ence between two classes. For example, one of the most
popular fine-grained tasks is bird species recognition. All
birds have the basic body structure with beak, head, throat,
belly, wings as well as tail parts, and two species might dif-
1
arXiv:1705.00487v3 [cs.CV] 20 Jul 2017
下载后可阅读完整内容,剩余9页未读,立即下载
2021-04-14 上传
2018-12-27 上传
2024-08-20 上传
2023-06-01 上传
2021-05-17 上传
2021-05-19 上传
2021-04-28 上传
2022-07-14 上传
2021-04-16 上传

mingmingdiii
- 粉丝: 0
- 资源: 1
 我的内容管理
展开
我的内容管理
展开







最新资源
- Fisher Iris Setosa数据的主成分分析及可视化- Matlab实现
- 深入理解JavaScript类与面向对象编程
- Argspect-0.0.1版本Python包发布与使用说明
- OpenNetAdmin v09.07.15 PHP项目源码下载
- 掌握Node.js: 构建高性能Web服务器与应用程序
- Matlab矢量绘图工具:polarG函数使用详解
- 实现Vue.js中PDF文件的签名显示功能
- 开源项目PSPSolver:资源约束调度问题求解器库
- 探索vwru系统:大众的虚拟现实招聘平台
- 深入理解cJSON:案例与源文件解析
- 多边形扩展算法在MATLAB中的应用与实现
- 用React类组件创建迷你待办事项列表指南
- Python库setuptools-58.5.3助力高效开发
- fmfiles工具:在MATLAB中查找丢失文件并列出错误
- 老枪二级域名系统PHP源码简易版发布
- 探索DOSGUI开源库:C/C++图形界面开发新篇章
