MySQL Binlog实时同步HDFS:探究Canal、Maxwell与mysql_streamer的实践
17 浏览量
更新于2024-08-30
收藏 305KB PDF 举报
MySQL Binlog同步HDFS的方案是针对有数据实时性和增量同步需求的公司设计的一种技术解决方案。当关系型数据库如MySQL与大数据处理平台Hadoop生态(特别是HDFS)之间的数据传输变得越来越频繁,对数据传输的实时性要求也日益提升时,如何实时捕获MySQL的更新并将其高效地写入HDFS就显得尤为重要。
在19年,作者曾分享过关于Canal的文章,一个基于阿里开源的MySQL变化数据捕获工具,它通过模拟MySQL的主从复制(Master-Slave架构)机制来实现数据的实时同步。这种架构有助于解决多个问题:
1. **数据多点备份与可用性**:通过将数据从主库复制到从库,增加了数据的冗余,提升了整体系统的可用性和容错性。
2. **读写分流**:由于数据只在从库进行非实时操作,主库可以专注于处理读请求,从而提高并发性能,优化资源分配。
3. **非实时任务迁移**:非实时的数据处理任务可以在从库上执行,减少对主库的压力。
Canal的核心原理是模拟MySQL slave的行为,接收并解析master发送的二进制日志(Binary Log),即binlog。它包括以下几个关键组件:
- **Server**:每个运行实例对应一个Java虚拟机,负责管理数据的处理流程。
- **Instance**:代表一个数据队列,一个Server可以管理多个Instance,每个Instance有自己的事件解析器(EventParser)、事件处理和存储模块(EventSink和EventStore)、以及元数据管理器(MetaManager)。
- **EventParser**:负责与MySQL交互,获取binlog并解析数据,记录上次成功解析的位置。
- **EventSink**:处理和过滤解析后的数据,将其适配到Kafka或其他目的地。
- **EventStore**:存储持久化的数据,用于后续的查询和恢复。
- **MetaManager**:管理增量订阅和消费信息,确保数据订阅的精确性和一致性。
在实践中,作者研究了三种组合方案:
1. **Canal + Kafka Connect + Kafka**:通过Canal收集MySQL变化,然后通过Kafka Connect将数据实时发送到Kafka,Kafka进一步处理后进入HDFS。
2. **Maxwell (Zendesk) + Kafka**:Maxwell是Maxwell项目的一个变种,也是类似的binlog监听器,可能也有类似的Kafka集成用于数据同步。
3. **MySQL Streamer (Yelp) + Kafka**:Yelp的MySQL Streamer可能提供了另一种方式来捕获MySQL更改,并通过Kafka进行数据传递。
MySQL Binlog同步HDFS的方案利用了MySQL的复制机制和分布式消息队列的强大处理能力,为实时性和可扩展的数据处理提供了一种有效的方法。选择哪种工具取决于具体业务场景、性能需求和技术栈的兼容性。
MySQL Binlog同步同步HDFS的方案的方案
这个问题我想只要是在做数据开发的,有一定数据实时性要求、需要做数据的增量同步的公司都会遇到。
19年的时候我曾经写过一点canal的文章。
现在你只要看这个文章就可以了。
这篇文章是一个读者推荐给我的,原地址:https://dwz.cn/XYdYpNiI,作者:混绅士
我对其中的一些内容做了修改。
关系型数据库和Hadoop生态的沟通越来越密集,时效要求也越来越高。本篇就来调研下实时抓取MySQL更新数据到HDFS。
初步调研了canal(Ali)+kafka connect+kafka、maxwell(Zendesk)+kafka和mysql_streamer(Yelp)+kafka。这几个工具抓取MySQL的方式都是通过扫描binlog,模拟MySQL master
和slave(Mysql Replication架构–解决了:数据多点备份,提高数据可用性;读写分流,提高集群的并发能力。(并非是负载均衡);让一些非实时的数据操作,转移到slaves上
进行。)之间的协议来实现实时更新的。
先科普下先科普下Canal
Canal简介简介
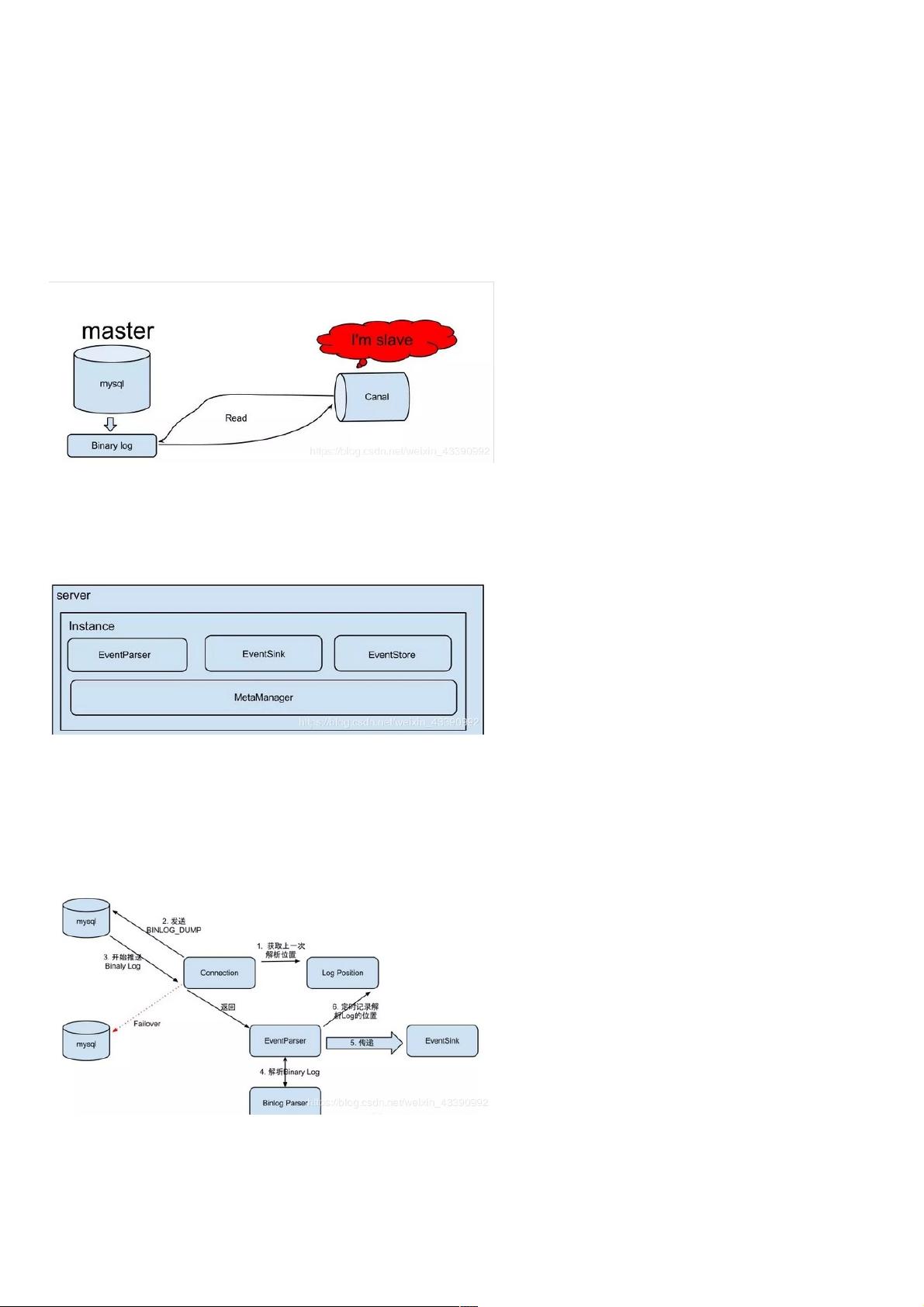
原理
Canal原理图
原理相对比较简单:原理相对比较简单:
canal模拟mysql slave的交互协议,伪装自己为mysql slave,向mysql master发送dump协议
mysql master收到dump请求,开始推送(slave拉取,不是master主动push给slaves)binary log给slave(也就是canal)
canal解析binary log对象(原始为byte流)
架构
Canal架构图
组件说明:组件说明:
server代表一个canal运行实例,对应于一个jvm
instance对应于一个数据队列(1个server对应1…n个instance)
而instance模块又由eventParser(数据源接入,模拟slave协议和master进行交互,协议解析)、eventSink(Parser和Store连接器,进行数据过滤,加工,分发的工作)、
eventStore(数据存储)和metaManager(增量订阅&消费信息管理器)组成。
EventParser在向mysql发送dump命令之前会先从Log Position中获取上次解析成功的位置(如果是第一次启动,则获取初始指定位置或者当前数据段binlog位点)。mysql接受到
dump命令后,由EventParser从mysql上pull binlog数据进行解析并传递给EventSink(传递给EventSink模块进行数据存储,是一个阻塞操作,直到存储成功 ),传送成功之后更新
Log Position。流程图如下:
EventParser流程图
EventSink起到一个类似channel的功能,可以对数据进行过滤、分发/路由(1:n)、归并(n:1)和加工。EventSink是连接EventParser和EventStore的桥梁。
EventStore实现模式是内存模式,内存结构为环形队列,由三个指针(Put、Get和Ack)标识数据存储和读取的位置。
MetaManager是增量订阅&消费信息管理器,增量订阅和消费之间的协议包括get/ack/rollback,分别为:
Message getWithoutAck(int batchSize),允许指定batchSize,一次可以获取多条,每次返回的对象为Message,包含的内容为:batch id[唯一标识]和entries[具体的数据对象]
void rollback(long batchId),顾名思义,回滚上次的get请求,重新获取数据。基于get获取的batchId进行提交,避免误操作
void ack(long batchId),顾名思议,确认已经消费成功,通知server删除数据。基于get获取的batchId进行提交,避免误操作
下载后可阅读完整内容,剩余3页未读,立即下载
1626 浏览量
57274 浏览量
196 浏览量
141 浏览量
130 浏览量
363 浏览量
2024-11-15 上传
214 浏览量

weixin_38691739
- 粉丝: 6
 我的内容管理
展开
我的内容管理
展开







最新资源
- Android平台DoKV:小巧强大Key-Value管理框架介绍
- Java图书管理系统源码与MySQL的无缝结合
- C语言实现JSON与结构体间的互转功能
- 快速标签插件:将构建信息轻松嵌入Java应用
- kimsoft-jscalendar:多语言、兼容主流浏览器的日历控件
- RxJava实现Android多线程下载与断点续传工具
- 直观示例展示JQuery UI插件强大功能
- Visual Studio代码PPA在Ubuntu中的安装指南
- 电子通信毕业设计必备:元器件与芯片资料大全
- LCD1602显示模块编程入门教程
- MySQL5.5安装教程与界面展示软件下载
- React Redux SweetAlert集成指南:增强交互与API简化
- .NET 2.0实现JSON数据生成与解析教程
- 上海交通大学计算机体系结构精品课件
- VC++开发的屏幕键盘工具与源码解析
- Android高效多线程图片下载与缓存解决方案
