CCNet:高效语义分割的跨界注意力机制
148 浏览量
更新于2024-08-27
收藏 833KB PDF 举报
"CCNet: Criss-Cross Attention for Semantic Segmentation"
这篇研究论文"CCNet:语义细分的跨界关注"提出了一种新的深度学习模型,即Criss-Cross Network (CCNet),用于语义分割任务。语义分割是计算机视觉领域的一个关键问题,其目标是将图像像素级地分类,以理解图像中的各个对象和场景元素。
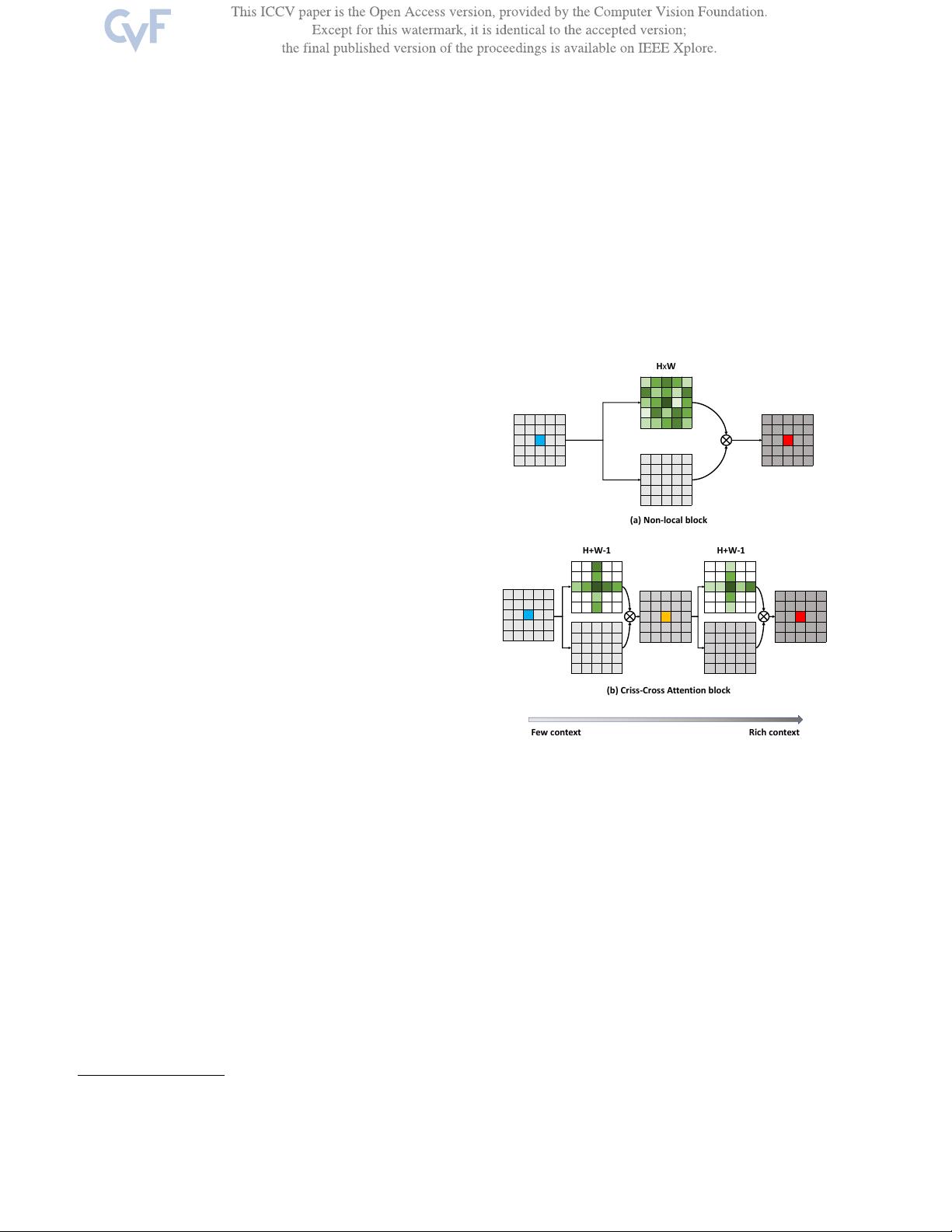
在CCNet中,作者们关注的是全图依赖性,这是提供有用上下文信息的关键因素,对于视觉理解任务非常有益。他们设计了一个创新的Criss-Cross注意力模块,它针对每个像素提取其交叉路径上的所有像素的上下文信息。这个模块的独特之处在于,它通过递归操作使得每个像素能够捕获来自所有像素的全图依赖性,从而增强模型对图像复杂结构的理解。
相比传统的非局部块(Non-Local Block),CCNet的显著优势在于:
1) GPU内存友好:提出的递归Criss-Cross注意力模块所需的GPU内存使用量减少了约11倍,这意味着在不牺牲性能的前提下,可以处理更大的输入图像和更复杂的模型。
2) 高计算效率:通过递归Criss-Cross注意力,模型的浮点运算次数(FLOPs)减少了大约85%,这极大地提高了计算效率,使得实时应用成为可能。
此外,该论文可能还讨论了CCNet在各种语义分割基准数据集上的实验结果,比如Cityscapes或PASCAL VOC,以验证其性能和与现有方法的比较。通过这些实验证明,CCNet在保持高精度的同时,实现了内存和计算资源的有效利用,从而为语义分割任务提供了一个有竞争力的解决方案。
CCNet的贡献在于它提供了一种新颖且高效的机制来处理图像的全局上下文,这对于解决视觉任务中的复杂场景理解和对象识别具有重要意义。这种方法不仅有助于提高现有语义分割模型的性能,还可能启发未来在计算机视觉、自动驾驶、机器人导航等领域的研究和应用。
CCNet: Criss-Cross Attention for Semantic Segmentation
Zilong Huang
1∗
, Xinggang Wang
1†
, Lichao Huang
2
, Chang Huang
2
, Yunchao Wei
3,4
, Wenyu Liu
1
1
School of EIC, Huazhong University of Science and Technology
2
Horizon Robotics
3
ReLER, UTS
4
Beckman Institute, University of Illinois at Urbana-Champaign
Abstract
Full-image dependencies provide useful contextual in-
formation to benefit visual understanding problems. In this
work, we propose a Criss-Cross Network (CCNet) for ob-
taining such contextual information in a more effective and
efficient way. Concretely, for each pixel, a novel criss-cross
attention module in CCNet harvests the contextual infor-
mation of all the pixels on its criss-cross path. By taking a
further recurrent operation, each pixel can finally capture
the full-image dependencies from all pixels. Overall, CC-
Net is with the following merits: 1) GPU memory friendly.
Compared with the non-local block, the proposed recurrent
criss-cross attention module requires 11× less GPU mem-
ory usage. 2) High computational efficiency. The recurrent
criss-cross attention significantly reduces FLOPs by about
85% of the non-local block in computing full-image depen-
dencies. 3) The state-of-the-art performance. We conduct
extensive experiments on popular semantic segmentation
benchmarks including Cityscapes, ADE20K, and instance
segmentation benchmark COCO. In particular, our CCNet
achieves the mIoU score of 81.4 and 45.22 on Cityscapes
test set and ADE20K validation set, respectively, which
are the new state-of-the-art results. The source code is
available at
https://github.com/speedinghzl/
CCNet
.
1. Introduction
Semantic segmentation, which is a fundamental problem
in the computer vision community, aims at assigning se-
mantic class labels to each pixel in the given image. It has
been extensively and actively studied in many recent works
and is also critical for various challenging and meaningful
applications such as autonomous driving [
14], augmented
reality [
1], and image editing [13]. Specifically, current
state-of-the-art semantic segmentation approaches based on
∗
The work was mainly done during an internship at Horizon Robotics
†
Corresponding author.
(a) Non-local block
(b) Criss-Cross Attention block
H+W-1
Rich context
Few context
H+W-1
HxW
Figure 1. Diagrams of two attention-based context aggregation
methods. (a) For each position (e.g. blue), the Non-local module
[
31] generates a dense attention map which has H × W weights
(in green). (b) For each position (e.g. blue), the criss-cross at-
tention module generates a sparse attention map which only has
H + W − 1 weights. After the recurrent operation, each position
(e.g. red) in the final output feature maps can collect information
from all pixels. For clear display, residual connections are ignored.
the fully convolutional network (FCN) [
26] have made re-
markable progress. However, due to the fixed geomet-
ric structures, they are inherently limited to local receptive
fields and short-range contextual information. These limita-
tions impose a great adverse effect on FCN-based methods
due to insufficient contextual information.
To make up for the above deficiency of FCN, some works
have been proposed to introduce useful contextual infor-
mation to benefit the semantic segmentation task. Specif-
ically, Chen et al. [
5] proposed atrous spatial pyramid pool-
603
下载后可阅读完整内容,剩余9页未读,立即下载
2021-05-11 上传
2021-09-25 上传
2019-08-12 上传
2023-03-16 上传
2023-06-09 上传
2023-09-24 上传
2023-10-25 上传
2023-09-12 上传
2023-07-28 上传

weixin_38722464
- 粉丝: 4
- 资源: 939
 我的内容管理
展开
我的内容管理
展开







最新资源
- 全国江河水系图层shp文件包下载
- 点云二值化测试数据集的详细解读
- JDiskCat:跨平台开源磁盘目录工具
- 加密FS模块:实现动态文件加密的Node.js包
- 宠物小精灵记忆配对游戏:强化你的命名记忆
- React入门教程:创建React应用与脚本使用指南
- Linux和Unix文件标记解决方案:贝岭的matlab代码
- Unity射击游戏UI套件:支持C#与多种屏幕布局
- MapboxGL Draw自定义模式:高效切割多边形方法
- C语言课程设计:计算机程序编辑语言的应用与优势
- 吴恩达课程手写实现Python优化器和网络模型
- PFT_2019项目:ft_printf测试器的新版测试规范
- MySQL数据库备份Shell脚本使用指南
- Ohbug扩展实现屏幕录像功能
- Ember CLI 插件:ember-cli-i18n-lazy-lookup 实现高效国际化
- Wireshark网络调试工具:中文支持的网口发包与分析
